はじめに(方法論の概要)
本書の目的
本書の読者は、ITに関しては素人であるが、業務をよく理解していること、論理的な思考には慣れていることを前提にしています。そのような企業が、はじめて情報システムを構築するとき、どのように進めればよいかを示したものです。「IT素人集団でもここまでできる」「この程度はやるべきだ」という内容を示しています。
特に独創的な方法論を展開するのではありません。これまでの方法論を「IT知識なしに」「はじめて」取り組めるようにアレンジしたものです。しかし、初歩的な内容ではありません。IT活用の経験が長い大企業でも「当初からこのようなアプローチをしていればよかったのに」と思うこともありましょう。
ここでは、システム設計をテーマにします。
- 「IT推進にあたっては、まず経営戦略を策定し、それに基づき~」といわれます。それは重要なことなのですが、ここでは、「システムを作る」ことに絞ります。
- システムを作るには、プログラムを作成する、データベースを実装することが話題になりがちですが、それらは外注するのが適切なので取り扱いません。それ以前の論理的な設計段階を対象にします。
本方法論の特徴
一般のシステム設計の方法とやや異なる方法論を採用しています。そのポイントは、情報システムをマスタシステムとイベントシステムに分離すべきこと、そして、ファイルや項目に関する辞書(メタデータベース)が重要であり、辞書の整備をすることがシステム設計なのだという考え方です。
マスタシステムとイベントシステムの分離とマスタシステムの先行
一般に事務処理で用いるファイルは、マスタファイルとイベントファイルに区分できます(参照:「マスタファイルとイベントファイル」)。そして、それぞれのファイルを設計し運用することをマスタシステム、イベントシステムといいます。
マスタファイルとは、得意先台帳や商品台帳のようなものです。得意先や商品などに関して、あまり変化しない事項を集めたファイルです。得意先マスタには得意先コード、得意先名称、住所など、商品マスタには商品コードや商品名、メーカー名、商品区分などの項目が入っています。
イベントファイルとは、売上ファイルや仕入ファイルのように、売上や仕入れなどの事象(イベント)が発生したときにデータが追加されるファイルです。
例えば社員の所属部門や地位のファイルは、現状の情報だけが必要だと考えればマスタファイルだといえますし、人事異動というイベントにより蓄積されるのだと考えればイベントファイルになります。あるいは、イベントファイルとしてもつが、最新の情報はマスタファイルでもつことも考えられます。
このように、マスタとイベントの区別は厳格なものではありません。人事異動(イベント)の発生頻度、所属部門や地位(項目)の参照頻度から「適当に」判断してかまいません。かなりルーズな方法論なのです。
通常の方法論では、販売システムや会計システムなど個別のシステムを設計する段階で、マスタファイルやイベントファイルを設計するのですが、本方法論では、個々のシステムを検討する以前、極端にはIT化を前提とせずに、マスタファイルの構造を決めます。すなわち、得意先台帳や商品台帳などの整備をすることを先行させるのです。
そして、イベントシステムは、販売システムなどの個別システムに該当します。この段階での進め方は一般の方法論とほぼ同じですが、基本的にはデータ中心アプローチという方法論をベースにしています。すなわち、ほしい情報は何かを調べることにより、イベントファイルの内容を決定し、それを作成するのにどのように入力するかを考えるという手順になります。
このイベントシステムを構築するときに、マスタシステムが存在することにより、個別システムの構築が容易になり、他の個別システムと整合性のあるシステムになるのです。
辞書(メタデータベース)の構築
マスタシステムとは台帳を作ることだといいました。それには、
・どのような台帳が必要か(存在するか)
・台帳にどのような内容を記載すべきか(記載されているか)
を明確にしなければなりません。
台帳の台帳(メタ台帳)にあたるものが辞書(の一部)なのです。
本方法論では、得意先業種や商品区分など、業務で用いるすべての用語(概念)について台帳化します。IT専門用語では、データの正規化という概念に基づいています。
ここで重要なことは用語の定義です。「得意先」とは何かを厳密に定義して、それを社内標準語にするのです。イベントシステムでの「出荷」や「売上」などについても同様です。
「辞書」といっているのは、多様な検索ができるからです。「得意先」に関するデータが入っているファイルはどれか、そのファイルとどのファイルを組み合わせると、得意先別売上集計表が得られるのかという検索を容易にするのが辞書の目的です。
すなわちこの辞書は、マスタファイルやイベントファイルがもつべき情報(項目)を整理したものです。辞書が整備されていれば、それに合わせて具体的にファイルを実装するだけになります。
具体的な辞書の内容などについては後述します。
本方法論の利点
一般的なシステム設計論と比較して、本方法論は次のような利点があります。というよりも、これらの利点を追求して本方法論を提唱しているのですが「銀の弾丸」ではありません。実際には、この方法論にも限界がありますし、矛盾が生じる場合もあります。それらを少なくするために、ケースバイケースでの工夫が必要になります。
中途半端でも無駄な作業にならない
通常のシステム設計論では、そのシステムが完成しないと、それまでの作業が無駄になることが多く、そのため、しっかりした計画をたててから作業に着手することが必要だと説かれています。それは正しいとはいえますが、「ITの素人がはじめて」のときに、そのような計画が策定できるとは思えません。
この方法論の最大の利点は「無駄な作業をしない」こと、「中途半端な作業だけでも、それなりに役立つ」ことです。この方法論では、当初から網羅的な大規模作業を要求しません。逐次的に拡大・充実させていけばよいのです。そのとき、手戻りが生じないように、当初からしっかりやるべきこと、順次充実していけばよいことを切り分けることを説明しています。
- 最初の作業である「用語を列挙して定義をする」ことだけでも、社内用語の統一ができ、部門間での誤解を防ぐのに役立ちます。
- 「商品区分などの項目を調べる」などは、商品についてどの部門がどのような切り口での情報を必要としているかを全社的に調べるので、部門間の相互理解に役立ちます。すなわち、システム化を前提にしなくても役に立つ作業なのです。/li>
- マスタシステムの構築だけで終わっている段階でも、「○○の条件に合致した社員は?」というような台帳検索的な利用ができます。
システム開発費用の削減
情報システム開発はベンダに発注するのが通常ですが、この方法論では利用者側でかなりの作業ができます。そのため、開発費用を低く抑えることができます。効率性、操作性、セキュリティなどを無視すれば、あるいは独力で開発できるかもしれません。
- 辞書が整備されていれば、構築すべきシステムの内容をベンダに誤解なく伝えることができます。既に外部仕様書どころか内部仕様書の一部まで完成しているのですから、委託すべき作業を少なくできます。
- おそらくマスタファイルは利用者だけで作成できるでしょう(後日更新システムの構築は必要ですが)。ベンダに依頼するのはイベントシステムだけになるので、これも委託作業を小さくなります。
- 辞書を活用することにより、情報検索系システムをエンドユーザ・コンピューティングで行えるようになります。エンドユーザが独力で多くの情報が得られるので、イベントシステムでの出力帳票類を少なくできます(参照:情報検索系による基幹業務系の簡素化」。
縦割りシステムの危険からの回避
例えば、販売システムでの売上データは会計システムでの売掛金データになるように、各個別システムは緊密に連携しています。このとき、売上ファイルから売掛金ファイルへ容易に変換できる必要があります。また、「仕入先に自社製品をどれだけ売っているか」を知りたいとき、仕入先コードと得意先コードが異なっていたら名寄せ作業が複雑になります。このような、縦割りシステムの問題点は多く指摘されています。
縦割りシステムになるのを防ぐために、全社的なシステム化計画の策定が必要だとか、システム開発に他部門担当者をメンバーに加えるべきだとかいわれています。マスタシステムを先行させることにより、全社的な観点から体系化が行われますので、あまり意識しなくても自動的に縦割りシステムになるのを防ぐ(少なくする)ことができます。
「辞書」のイメージ
この方法論では、システム設計とは(少なくともその主要部分は)辞書を作ることであるとしています。そして、辞書の内容や留意事項に関して、本書のいろいろな個所で散在して説明しているため、全体像が把握できないと思います。それでここでは全体のイメージを示します。当然ながら、企業環境や目的に合わせて工夫する必要がありますので、ここでは概略的なイメージであることをお断りしておきます。また、ここでは説明なしに用語や概念を用いていますが、それは本文をお読みいただくうちに理解できると思います。
辞書の構成
辞書は「項目説明書」「ファイル説明書」「ファイル-項目対照表」「ファイル-処理対照表」の4ファイルから構成されます。
項目説明書
専門用語でいえば「正規化後のエンティティ及びその属性に関するメタ情報を記録したデータベース」です。
得意先や商品など「概念としてのモノ」をここでは項目といいます(専門用語ではエンティティといいます)。企業で用いられているすべて(当然、気づいたものにものだけになるが)の項目を列挙して、商品区分と商品、部門と社員のような親子関係などの関連(リレーションシップ)ににより体系化して(正規化して)、それぞれの項目を一つのデータ(レコード)としたファイルです。
「得意先」項目を例にすれば、次のような内容をもっています。
必須
・項目名「得意先」、システムで用いる変数名(英数字)「tokuisaki」
・「得意先」とは何かの定義。厳密な定義をした文書へのリンクと「1行定義」
・得意先と1:1の関係になるもの。得意先名称、略称、住所など。
・得意先の親になる項目。得意先区分、業種、府県など。
オプション
・この項目の更新などを管理する部門や手続き
・得意先コードの付け方に関する文書へのリンク
・その他得意先に関する地図、写真、商談などの資料へのリンク
ここでは売上高のようなイベントにより発生する情報は対象にしていません。
ファイル説明書
作成されるすべてのファイルにつき、その内容を解説したものです。
マスタファイルは、各項目につき一つのファイルが対応します。項目の変数名がファイル名になります。ファイルの内容はおそらく自明でしょうから、この説明書の対象外としてもよいし、イベントファイルとは別のファイル説明書にしてもよいでしょう。
イベントファイルではこれが重要になります。イベントファイルでは、「売上ファイル」といっても、月別のファイル、それを年度に累積したり、月単位で集計したり、ある商品だけを抽出したものなど多様なファイルが存在します。しかも、返品などがあった場合、数量や金額を修正した結果になっているのか、売上と返品の二つのデータになっているのかなど、それらの説明が必要になります。
必須
・ファイル名称「売上」とその英字名「uriage」
・物理的ファイルとのリンク
・厳密な説明をした文書へのリンクと「1行説明」
オプション
・年月区分、集計有無などをコード化することが便利な場合もあります。
ここで、物理的ファイルとのリンクでは、絶対年月よりも「当月」、「前月」、「前年同月」などの相対年月にしておき、毎月リンク先を更新するほうが便利です。
ファイル-項目対照表
指定したファイルがもつ項目はどれか、この項目をもつファイルはどれかを検索するための対照表です。マスタファイルとイベントファイルの両方、イベントファイルだけにある項目(数量や金額など)も加えて一つのファイルにします。
ファイル名と項目名を英数名でペアでもつのが通常ですが、日本語名を知るのにファイル説明書や項目説明書を参照するのが面倒だとするならば、それらを加えてもよいし、その他の適当な情報を加えてもよいでしょう。
逆に、この作成が面倒だとするのであれば、ファイル設計で必ず作成するファイルデザイン(このファイルに含まれる項目リスト)をそのまま使うこともできます。しかし、項目からファイルを検索する効率的なツールが必要です。
ファイル-処理対照表
東京(得意先住所)での商品区分別売上一覧表は、売上ファイルを入力とし、得意先マスタの府県、商品マスタの商品区分により抽出・集計して得られます。このように通常の出力処理は主となるイベントファイルをマスタファイルと照合する操作になります。この対照表は、イベントファイルから得られる既存の帳票類やプログラムを知り、重複した帳票出力を節減したり、類似プログラムを修正して情報を得たりすることを目的としたものです。主にエンドユーザ用のものです。
イベントファイルから検索するのが通常でしょうが、帳票やプログラムの名称や区分を工夫すれば、そちらから検索することもできます。帳票とプログラムとで、対照表に入れるべき情報は異なりますが、利用者はどちらにあるか知らないのですから、一つのファイルにしたほうが便利です。
共通
・イベントファイル名
・プログラム名または帳票名
・プログラム/帳票区分
・検索用キーワード
プログラム
・プログラムのファイルへのリンク
・プログラム説明書へのリンク(プログラム内に記述されていれば不要)
帳票
・帳票のひな型(実際に数字がはいっており、注釈を上書きされていれば最適)
・帳票の説明書へのリンク(内容説明、配布先、配布時期など)
エンドユーザが最も重宝するファイルです。この充実程度が情報検索系システムの普及を左右します。
エンドユーザが新規あるいは修正したプログラムを(できればベテランがチェックして注釈を加えて)、この対照表に加える制度を設けると、自動的に充実します。
辞書の機能と実装
エンドユーザがある情報を得たいとき、例えば次のようなアプローチをするでしょう。
- 「ファイル-処理対照表」から自分のニーズに類似したプログラムを検索する。
- 自分のニーズにこのファイルを用いるべきか、もっと適したファイルがあるかを「ファイル説明書」で確認する。
- プログラムの抽出や集計のキー項目を変えるとき、その項目の意味やコード体系を「項目説明書」で調べる。
アプローチの順序は、場合により千差万別です。データ入力時に得意先コードを知りたいだけの場合もあります。長距離配送の上位10件を得たいといような新規のニーズもあります。あるいは、システム設計者がマスタファイルの構造や変数名を調べたい場合もあります。
しかも、利用者「ファイル-処理対照表」や「ファイル説明書」の存在やその内容を理解していない(理解しなくてもよいようにしたい)ので、どこからでも、どの情報へも得られるようにしたいのです。そのための相互参照機能が求められます。
これらのファイルは紙の文書では役に立ちません。随時変更になるので、古いマニュアルがあると思わぬトラブルになります。
Excelファイルも不適切です。作成するのにはExcelは便利ですが、上記のような多角的な検索に対応できません。原稿作成にはExcelを用いても、コンピュータに実装するときはデータベースとしてもつことが必要です。
多くの場合は、Webブラウザで他の業務をしている画面からぺルプ機能として利用するでしょう。それであればXMLの形式でもつのが最適だといえます。これにすれば、ファイルのなかに未定義の項目があることへの対処もできます。少なくともリレーショナルデータベースにしておくべきです。
ITの素人が、データベースに実装したり、相互参照機能を作成したり、それをブラウザでのヘルプ的な操作環境にするのは無理です。原稿をExcelで作成して、それを実装するのは専門家に依頼するのが適切です。また、当初から多様な機能を考えるのは困難だし、利用している間に要望やアイデアが出てくるものです。これも、「中途半端でも無駄な作業にならない」ように工夫する必要があります。
項目説明書の初期作成
項目の列挙と整理
項目の列挙
システム化の対象であるかどうかに関係なく、業務全体を対象にして項目(専門用語ではエンティティ)を列挙します。エンティティとは、単純にいえば「概念でとらえた用語」のことです。得意先、納入先、商品、商品区分、部門、社員などのことです。「出荷」「売上」「年月日」「数量」「金額」など、イベントに関する用語もエンティティですが、それらはイベントシステムで取り扱い、ここではモノに関する用語だけに絞ります(「安部商店」とか「川崎工場」など具体的な個々のモノはエンティティではありません。インスタンスといいます。インスタンスをグループ化した概念用語がエンティティだと理解してよいでしょう)。
できるだけ多くの項目を列挙することが重要です。例えば、同じ商品でもバラのものとダース単位のものなどを区別するために「荷姿」が必要な場合もあります。得意先の「業種」が必要なこともありましょう。おそらく数百の項目が列挙できるはずです。
もしExcelを用いるならば、一つの項目が1行になります。この列に「項目名」という見出しをつけておきます。
用語の統一と定義
個々の項目について、用語の統一をします。
例えば「得意先」を、請求書の送付先として用いたり、商品の納入先として用いるようなホモニム(同名異義語)、「得意先」を「顧客」「お客様」などというようなシノニム(異名同義語)を排除して、社内標準用語にまとめることが必要です(参照:「用語定義の重要性」)
この作業過程で「用語(項目)の定義」を文書にします。誰がみても正確に理解できるように、くどぎる程度に記述した「厳密定義」と、関係者なら誤解しない程度に記述したせいぜい10~15文字以内の「1行定義」の二つを作成することがコツです。
この作業により、いくつかのエンティティが一つになったり、新しいエンティティが追加されるでしょう。
Excelでの3列目(2列目には後述の「変数名」を入れる)に1行定義を記入し、これとは別の「項目定義」フォルダに各項目名(英字名)をつけたファイル(txtがよい)に厳密定義を記述し、4列目にそのファイルとのリンクをいれます(以降、このような記述は省略します。適当に判断してください)。
項目間の関連を整理する
専門用語でいえば、データの正規化にあたる作業です。これは一見やさしそうですが、実際に作業してみると間違いをすることが多いのです。専門家の指導(2時間程度でよい)を受けたほうがよいでしょう。
親子
例えば、商品は一つの商品区分に属するし、商品区分にはいくつかの商品があるという場合、商品区分と商品の間には親子の関連(リレーションシップ)、あるいは「1:Nの関連」があるといいます。このような関連は、得意先と納入先、部門と社員などの間に存在します(部門と社員の関連において、社員が複数の部門に属することがあるときは「M:Nの関連」になるので、親子の関連はありません)。
親子の関連は、親-子-孫のように多階層になる場合がありますが、そこまで関連付ける必要はなく、直接の親子関だけでよいのです。
汎化
例えば「得意先」と「仕入先」は、「相手先」という項目を作れば一つにまとめられます。このとき、相手先をスーパークラス、得意先と仕入先をサブクラスといいます。同様に、サブクラス「正社員」「パート社員」「派遣社員」はスーパクラス「社員」にまとめられます。その「まとめる」ことを「汎化」といいます。
例えば、「部品の仕入先に自社製品をどれだけ販売しているか」を知りたいとき、得意先と仕入先を同一コードにしておけば名寄せ作業を回避することができます。このように汎化したエンティティを設定することは、将来の情報システム活用に大きな効果があります。また、得意先と仕入先の区分をしたいのであれば「相手先区分」という項目を設定します。
なお、このような関連を図表化する技法にER図やクラス図があります。細かい規則は不要ですが、ベンダはこれらの図表で説明することが多いので、その概略は理解しておきましょう。
関連事項
コード体系を決めてコード付けをする
得意先コード、商品コードなど、一般に項目にはコードを付けます。コードは次のような用途に用いられるので、実務の観点、しかも関係する全部門の観点からコード付けを考える必要があります。
- 通常、売上データなどのデータの入力や、データの検索をする場合、得意先や商品の名称を入力するのは煩雑ですし、間違いも発生します。コード入力のほうが簡単です。反面、JANコードのような長いコードはコードを暗記するのが大変です。
- 通常、データの出力順序は、コードの小さい順に並びます。業務での使いやすさや慣習に合致するコードにするべきです。
- 出力順序と関連しますが、最初の数桁でグループ化しておくことにより、仕分けや集計の作業が容易になります。そのためコード体系での工夫が必要です。
食品や日常雑貨にあらかじめ印刷されているJANコードのような標準コードがある場合はそれを利用するのが適切です。性別、都道府県、市区町村などJIS化されているものもあります。ここでは、自社独自でコード付けをするときの留意事項を示します。
- ある商品を取り扱わなくなったので、そのコードを他の商品に再利用するようなことは厳禁です。過去のデータが使えなくなってしまいます。
- 変化があってもコードの変更をするべきではありません。例えば社員コードに所属や地位などを入れると、人事異動や昇進のたびに新しいコードを付けることになります。そうすると、その社員の過去のデータと組み合わせた情報を得るのが非常に困難になります。通常は、先頭の2桁で入社年度、その後は通し番号にしておく程度が適切です。
- コード体系の変更はなおさら避けるべきです。多様な分類をコードの桁で示そうとすると、コードが長くなるだけでなく、ある分類に属するデータが増加したとき、コード付けできなくなります。その際例外を設けると、体系化した意味を失ってしまいます。分類の方法は、コードの特定桁による方法とマスタファイルの項目(商品区分など)を設ける方法がありますが、コードによる方法は、絶対に変更をする必要がない1つか2つの体系だけに絞るのが適切です。
マスタファイルの論理設計をする
「得意先」項目には「得意先」マスタ、「商品」項目には「商品」マスタが対応するように、原則として、各項目に対して一つのマスタファイルができます。
得意先マスタでの、得意先コード、得意先名、得意先区分コードなどのように、ファイルにはいくつかの項目があります。その項目は、大きく3つ(場合によっては4つ)あります。
- 主キー:得意先での得意先コードのように、マスタファイルのなかのデータを決める項目です。マスタファイルのなかに主キーが同じ値のデータは一つしかありません。それで、主キーのことをユニークキーともいいます。そして、他の項目は、「主キーが決まれば一意に決まる」項目になります。
- 1:1の関連項目:得意先名称や得意先住所などです。これは、エンティティとしては取り扱わず、得意先名称マスタのようなファイルは存在しません。
- 親のコード:得意先区分のように、親のエンティティがある場合、親のコード(得意先区分コードや府県コードなど)を項目にします。しかし、親のコードだけで、得意先区分名称や府県名称など親エンティティの項目は入れません。これは非常に重要な規則です。これを間違わないために、データの正規化を行うのです。
- 汎化をした場合には、その区分が必要になることがあります。例えば、得意先と仕入先を相手先としたとき、その区分が必要ならば、「取引形態コード」を設けて区分します。この場合は不要なことが多いでしょうが、「正社員」「パート」「派遣」を汎化して「社員」とした場合には「雇用形態コード」が必要になるでしょう。
いくつかの留意事項
「得意先」や「商品」などのエンティティ名は、画面表示や帳票印刷での欄の名称になります。誤解が生じなく簡潔な名称にする必要があります。また、インスタンスの名称ですが、例えば得意先名称には「○○株式会社」など、請求書に印刷するような正式名称だけでなく、社内管理用の画面表示や帳票印刷で用いる略称が必要です。そのための「得意先略称」のような項目も設定しておく必要があります。
用語統一をしたら、システムでの用語(データベースやプログラムなどで使う変数名)も同時に決定します。日本語が使える言語だけではないので、英数字の変数名も必要です。日本語の場合もあまり長々しいのは不便です。
- 英字にする場合、英語にするのかローマ字にするのか、ローマ字ではヘボン式か訓令式かなど統一しておくのが適切です。スペルミスでのトラブルは案外多いのです。
- 「エンティティ名=マスタファイル名=主キーの項目名」とするのが適切です。例えば、エンティティ得意先に対応するマスタファイルの名称はtokuisakiファイルであり、その主キーである得意先コードの変数名はtokuisakiであるというようにします。
- 例えば、tokuisaki-nとかtokuisaki-rのように、名称や略称など多くのエンティティで共通する項目名の表記方法を統一しておくと便利です。
- 例えば得意先に関しては、地図や写真、商談報告、その他の情報など、イベントデータ以外の多様な情報があります。項目説明書これらの文書へのリンクを入れておくと、辞書の効果が大きくなります。
しかし、エンティティにより、これら文書は多様ですので、統一的な項目体系にするのは困難です。それで、エンティティファイルの項目には「文書情報の有無」程度の項目にしておき、それからリンクしたファイルに、個別の文書へのリンク一覧を作成するなどの工夫をします。
得意先という項目の設定、新規得意先の追加、そのコード付番など、それぞれの項目を管理する部門や手続きに関する事項もマスタに入れておくことが運営上役に立つ場合があります。
辞書やマスタファイルの整備だけでも利用価値がある
マスタファイルの実装
ここまで作業をすれば、マスタファイルそのものを作成してコンピュータに実装することができます。その際、以降の作業進展に伴い、項目追加が行われるので、それを行いやすいデータの持ち方が必要になります。原稿はExcelでもよいのですが、コンピュータに実装する場合は、データベースにする必要があります。
Excelからデータベースへの変換そのものは簡単ですが、どのようなデータベースにするか(Accessでよいか、MySQL や PostgreSQL にするかなど)は、今後の利用を考えて決定する必要があるので、専門家と相談するのが適切です。
辞書(項目説明書)やマスタファイルが整備されていることは、イベントシステムの構築に大きな効果がありますが、それに関しては後述します。ここでは、イベントシステムに関係なく、ここまでの段階でもかなりの効果があることを示します。すなわち、これらの作業は無駄にならないのです。
項目説明書の整備による効果
- 社内用語が統一されます。ホモニムやシノニムによる誤解がなくなります。これは、ITに関係なく、報告や討議での誤解を防ぐために重要なことなのです。また、情報システム構築をベンダに依頼するとき、ベンダが用語を正しく理解するためにも重要です。
- エンティティの定義は、親子や汎化などによる他のエンティティに影響します。これらのエンティティがどの業務(部門)に関係しており、どのように用いられているかが明確になります。エンティティの追加や定義の変更が影響する範囲を知ることができ、ある部門が独断で決めたことが他部門に思わぬ影響を及ぼすようなことを防ぐことができます。
- 得意先や商品などは、多くの部門で多様な切り口で加工しています。それを一覧形式で把握できるので、全社的に最適なコード付けができます。
マスタファイルが実装されたときの効果
イベントデータに関係しないという制約があるが、それでも多様な条件検索ができます。
・特定の得意先に関する台帳情報の一覧
・得意先の府県別構成、取引開始時期別構成
・英語が堪能な20歳台の社員のリスト
などが簡単に得られます。
マスタシステムの維持管理
マスタシステム運営体制
継続的な充実作業が必要
当初から万全な辞書を作成し、マスタファイルを実装することは不可能です。気づいたり必要になるたびに追加更新することが重要なのです。
先に「中途半端でも役に立つ」といいましたが、それは「実態と乖離していないならば」という条件付きです。実態と異なるものになったら、その影響は甚大です。常に実態を反映して修正する必要があります。しかも、修正をするときには、それにより波及する影響を検討する必要があります(修正ができないような部分は、むしろ削除してしまうほうが安全です)。
イベントシステムの検討時には、マスタファイルの項目追加が必要になることが多くあります。イベントシステムでは特定の業務を対象にするので、全体的な整合性を見失いがちです。それをマスタシステムの観点からチェックする必要があります。
マスタシステム運営体制が必要
継続的作業を維持するのは、責任と権限のある組織体制で継続的に行うことが求められます。しかし、マスタ項目の追加や定義変更は、頻繁に起こりますし、それに関係する部門はまちまちです。そのため、同じメンバーが定期的に集まるような組織では円滑に作業ができません。
どのような組織にするかは、企業の状況にもよりますが、かなりの権限をもつ「マスタ管理委員会」的な組織があり、その監督下で臨機応変に関係者が会合をもつのが適切でしょう。先に「項目説明書にそれぞれの項目を管理する部門を入れておく」としたのは、その会合での責任部門を明確にするためでもあります。
管理運営での留意事項
オーソライズとローカルの両立が必要
マスタファイルの項目のうち、基幹業務系システムで必要になる項目は比較的少なく、多角的な切り口で検索加工を行う情報検索系システムからのニーズに基づくものが多く、しかも、ニーズの変化により新規に必要になったり不要になったりします。
基幹業務系システム用の項目に関する定義の管理やマスタファイルのデータ入力は、オーソライズした体制・方法で運営することが重要です。それに対して、情報検索系システム用の項目では、迅速な対応が必要ですので、あまり厳格な規則にするのはなく、エンドユーザに任せるほうが適切な場合があります。さらに、直接にエンドユーザにマスタファイルをアクセスさせると、故意あるいは過失により基幹業務系システム用の項目までも変更される危険がありますし、エンドユーザが変更作業をしている間は、基幹業務系システムでそのファイルが使えない状態になることもあります。
両立のための工夫
これを回避するために、管理面から3つに区分するのが適切です。
A(情報検索系システム用)
エンドユーザには参照できるだけで更新させない。
B(承認された情報検索系システム用)
項目の追加や定義改訂には、しかるべき承認ルールが存在する。
マスタファイルのその項目のデータ入力は、定められた担当者が定められた方法で行う。
C(ローカルな情報検索系システム用)
エンドユーザが勝手に作成・変更してもよい。
実際の管理が大変なのはCです。無条件にCを認めると多様なトラブルが発生しますし、それを禁止すると使い勝手が悪くなります。
実務的には、CはA・Bとは物理的には異なるファイルにしておき、論理的には一つのファイルとして取り扱えるようにする(ビューにする。その説明は省略しますが、ビューの設定が容易なデータベースを選択することが条件になります)のが適切です。そして、必要に応じてCをBに昇格させることにします。
そのビューをエンドユーザごとに設定するのでは煩雑になるので、C用として一つのビューを設定し、Cの部分は他のエンドユーザによるトラブルが発生しても仕方がないとしてもよいでしょう。エンドユーザをいくつかのグループに分けることもできましょう。
いずれにせよ、Cを放置しておくと気づかないうちに膨大なごみ箱になってしまいます。事後でよいから報告させること、報告のないものは通告なしに削除されることがあること、定期的に整理をすることなどの規則を設ける必要があります。
イベントシステムと項目説明書・マスタファイルの関係
イベントシステムとは
イベントシステムとは、販売システムや会計システムなど、特定の分野を対象としたシステムです。基幹業務系システムともいいます。通常はベンダに委託して構築します。
イベントファイルとは、注文や出荷などのイベントが発生したときに更新されるファイルです。注文ファイル、出荷ファイルという個々のファイルになるか、注文や出荷を汎化した受払という概念でまとめられた受払ファイルとしてもつかは、以降の検討によります。
ここでのイベントシステム設計とは、具体的な入力画面を設計したり出力帳票を作成する処理方法を検討することではなく、イベントファイルがどのような情報をもてばよいかを考えることだとします。すなわち、ファイル設計の分野です。
また、イベントシステムとは基幹業務系システムだといいましたが、ここで作成されたイベントファイルは、情報検索系システムとしても利用される(安全上、物理的には他のファイルにするでしょうが)ことを前提にしています。
イベントシステムは、ごく単純にいえば、次の3つに区分されます。
- 出力処理
- イベントファイルを入力として、マスタファイルの項目によりデータを抽出、集計、編集する処理です。編集は各帳票により千差万別なので、ここでは、抽出・集計されたデータが整えばよいということにします。
- 入力処理
- イベントファイルを最新の状態にする処理です。
- 中核処理
- 一般には、一つの入力データが複数のイベントファイルに関係したり、一つのイベントファイルが項目により複数の入力処理が必要になる場合があります。そのように、入力処理からイベントファイルの更新に至る処理のことを中核処理といいます。
ここでは、イベントファイルの設計ですので、中核処理は対象としません。入力処理で直接にイベントファイルが作成されることとします。
イベントファイルの検討による項目説明書とマスタファイルの拡充
イベントファイルの項目に関する基本的な考え方
まず、出力したい帳票類を調べます。既存のものもあれば、新規のものもあります。その帳票を作成するのに必要なイベントファイルが存在するとして、抽出や集計のキーとなる項目があるか、イベントファイルからマスタファイルを参照するのは共通のキー項目が必要だがそれがあるかなどを検討します。
イベントファイルの照合キー項目の確認
例えば、東京(得意先の住所が東京)の商品区分別売上集計表が必要だとします。抽出のためには、得意先マスタに府県の項目があること、売上ファイル(イベントファイル)に得意先コードがあることが必要です。集計のためには、商品マスタに商品区分の項目があり、売上ファイルに商品コードが必要であることがわかります。商品区分の名称も必要でしょうから、商品区分マスタに商品区分名称があり、商品マスタに商品区分コードがなければなりません。
ここで、売上ファイルに府県や商品区分も入れておけば、マスタファイルは不要だと考えるかもしれません。そのような考えが非常に困るのです。売上ファイルは多様な出力に用いられます。それらに必要な項目を全部持たせたら、売上ファイルのサイズは膨大なものになります。しかも、新しい切り口が発生するたびに売上ファイルの項目を追加しなければなりません。さらに重要なことは、府県や商品区分は購買ファイルの出力にも必要になります。売上ファイルと購買ファイルの間で同期をとる必要がありますが、その作業は大変です。
すなわち、イベントファイルにはマスタファイルと照合するためのキーとなる項目が必要であること、逆に、照合したマスタファイルから探せる項目はイベントファイルには入れないという原則があります。これを、イベントファイルでのデータの正規化といいます(注)。
(注)データの正規化の説明
作業や管理を容易にするには、府県や商品区分などのデータについて、「一つのデータは一か所(一つのファイル)にしか存在しない」というルールを徹底することが肝心です。そのような手段を「データの正規化」といいます。「マスタファイルの論理設計」で親子の関連を述べましたが、これはマスタファイルの正規化を行ったのです。それと同様に、イベントファイルにおいてもデータの正規化をするべきなのです。
やや専門的になりますが、データの正規化について説明しておきます。商品の単価をどのファイルにおくかを例にします(実務的には数量と金額はペアになって処理されることが多いので、正規化をせずに、計算された金額を数量と同じイベントファイルに入れておくのが通常ですが、正規化の考え方を説明するためにこの例が適切なので、あえて取り上げます)。
- どの得意先でも同じ単価を適用するならば、商品が決まれば単価が決まるのですから、単価は商品マスタの項目になります。
- 逆に、取引のたびに単価を交渉するのであれば、売上ファイルのデータを入力するたびに単価も入力することになるので、マスタファイルの項目にはなりません。
- 得意先により異なるが、同一得意先にはいつも同じ単価を適用するのであれば、得意先と商品を決めると単価が決まることになります。このときは、得意先と商品を連結(連結キーという)したコードを主キーとする単価マスタの項目になります。
- 得意先により、すべての商品に同一の割引率を適用するのであれば、単価マスタを作るよりも、得意先マスタの項目に割引率という項目を作り、それと商品マスタの項目である単価(標準単価)とで計算させるほうが簡単です。 さらに、得意先をいくつかのグループにわけて、グループごとに割引率を適用するのであれば、得意先マスタに得意先区分の項目を設け、さらに得意先区分単価マスタを作るのが適切です。
このように、多様なケースが考えられます。しかも、将来の変更も考える必要があります。
マスタの項目の追加が必要になる
帳票類を調べると、商品をグループ別に集計するといっても、そのグループ化の仕方が異なることがあります。できれば、特別な理由がなければ、これを機会に統一することが望ましいのですが、それが無理なこともあります。その場合には、商品区分1、商品区分2(このような名称は不適切ですが)のように、複数の区分を設けることになります。
また、特定の商品について例外処理をする場合があります。それをプログラムで、
if 商品コード=○○ or 商品コード=△△ ・・・
と記述するのでは、
・対象商品が変更になたときに、プログラムを修正しなければならない。
・他のプログラムでも同じ処理をしているとき、そのプログラムを探す必要がある。
という欠点があります。
商品マスタに「例外区分」の項目を設けて
if 商品コード=商品マスタ例外区分が真 ・・・
とすることにより、回避することができます。しかも、「例外区分」の項目説明書での「厳密定義」で例外処理の内容や例外が必要な理由などを記述することができます。
業務を取り巻く環境は常に変化していますが、環境変化に対してマスタファイルだけを変えればよく、既存のプログラムに影響を与えないようにすることは、経営の観点からも重要なことなのです。
入力処理との関係
データの正規化は、入力処理の簡素化にも役立ちます。請求書の送付先を得意先とし、商品を入入する場所を納入先とします。得意先と納入先の間には親子の関連があり、納入先がわかれば得意先は自動的に決まります。そのため、受注伝票には得意先と納入先が記述されていたとしても、納入先コードだけを入力すればよいことになります。
このように、マスタファイルが整備されていなければ、マスタファイルにある項目は入力する必要がなくなるので、入力作業が簡素化されます。
コンピュータに誤ったデータが入力されると、その影響が大きいので、入力時にデータチェックをすることが重要です。納入先コードを入力したら納入先マスタを照合して、納入先名称を表示することにより誤入力を少なくすることができます。
ここで、もし納入先により取り扱う商品が限定させている、あるいは、1回の受注量に上限(常識的に考えられる上限)があるような場合、納入先コード、商品コード、上限値を項目とする「納入先取扱商品マスター」を作成しておけば、商品コードや受注量の入力ミスを防ぐことができます。
ファイル説明書の作成
エンティティの拡充とイベントファイルの構成
マスタシステムでは、エンティティとは概念的なモノだといいましたが、本来は「名詞」で表されるそべてがエンティティなのです。イベントシステムでは、次のようなエンティティが必要になります。
- 「受注」「売上」「返品」「人事異動」など「○○する」という表現になるエンティティ
- それに関連する「年月日」「数量」「金額」、さらに「入力者」や「入力時刻」など、モノに関するエンティティ
用語の統一と定義
ここでも用語の統一をする必要があります。「出荷」とは、得意先に配送するために倉庫から商品を出すことを指すのか、自社の倉庫間での転送も含むのか、このようなことを定義して「1行定義」と「厳密定義」をする必要があります。しかし、それ以外の情報は特に必要はないので、未定義のままにしておいてもよいでしょう。
数量や金額などの計算項目は、それ自体が主キーになることはないので、エンティティではあってもマスタファイルは存在しません。年月日も同様です。
数量、金額、年月日などは多くのイベントファイルに現れます。その変数名は「ファイル名-数量」とするような工夫をしないと混乱してしまいます。年月日は -ymd、数量は -s、金額は -\ のような統一した略記法を用いることもできます。あるいは、用語の一意性が崩れますが、すべて「年月日」「数量」としてしまうほうが簡単になることもあります。
汎化が重要な検討事項になる
例えば、売上、出荷、転送、返品、さらに仕入や紛失などのエンティティは、倉庫の商品在庫の増減であるとして、「受払」というエンティティ(スーパークラス)に汎化することができます。そして、受払コードが1ならば売上、2ならば出荷、・・・、というように設定します。この場合も受払コードの1桁目を倉庫在庫の増減、2桁目を所有権移転の有無というように付けることもできます。
どこまで汎化をするかにより、ファイルの構成が異なります。例えば、
個々のサブクラスでファイルにするならば
受注ファイル:年月日、納入先コード、商品コード、数量
出荷ファイル:年月日、納入先コード、出荷倉庫コード、商品コード、数量
売上ファイル:年月日、得意先コード、商品コード、数量
仕入ファイル:年月日、仕入先コード、受入倉庫コード、数量
であるとします。
受注・出荷を受払と汎化すると、受注の場合は出荷倉庫コードは空白として、
受注ファイル:受払コード、年月日、納入先コード、出荷倉庫コード、商品コード、数量
売上ファイルを加えると、受注と出荷では納入先を客先、売上では得意先を客先とすることにより、
受払ファイル:受払コード、年月日、客先コード、出荷倉庫コード、商品コード、数量
さらに仕入も加えるて、不要な項目は空白とする考え方では、
受払ファイル:受払コード、年月日、得意先コード、納入先コード、
仕入先コード、出荷倉庫コード、入荷倉庫コード、商品コード、数量
受払コードにより項目の内容を変えるならば、
受払ファイル:受払コード、年月日、Fromコード、Toコード、商品コード、数量
のように多様な設計が考えられます。
どれがよいかは、そのイベントファイルがどのように利用されるかにより異なるので、一概にはいえませんが、
個別エンティティの場合
利点:わかりやすい
欠点:複数のファイルにまたがった処理が多くなる
汎化して空白項目をもたせる場合
利点:わかりやすい。一つのファイルの処理になる
欠点:データ容量に無駄が生じる
汎化して項目に複数の意味をもたせる場合
利点:一つのファイル。データ量がコンパクト
欠点:わかりにくい。プログラムが複雑になる
の特徴があります。
しかし、項目に複数の意味をもたせるのは避けたほうがよいでしょう。空白によるデータ容量の問題は、データベースをXMLデータベースにすれば解決できますが、未だその技術がポピュラーではありません。いづれにせよ「はじめて」の段階では、効率性よりも操作性、操作性よりもわかりやすさを優先すべきです。
イベントファイルの特徴
マスタファイルと比較して、イベントファイルでは、次のような特徴があります。
- データ期間により複数の同名ファイルが存在します。人事異動ファイル程度では、永久に一つのファイルにしても大したことはないでしょうが、売上ファイルなどは大量になるので、月別のファイルにする必要があります。すなわち、同一のファイル名称なのに、複数の物理的なファイルが存在することになります。これは派生ファイル問題として後述します。
- 主キーが存在しない(存在する必要がない)。売上ファイルのあるデータを特定するのに、同じ納入先と商品の売上データはいくつもありますし、年月日を与えても同一日に売上が発生することがあります。
- イベントファイルの項目には、名称など1:1に対応する項目は存在しません。
- マスタファイルの場合、主キーと1:Nの関連がある項目は、その項目自体がエンティティになるのでが、イベントファイルでは、数量や金額など計算項目があるファイルが多くあります。計算項目はエンティティにはなりません。
派生ファイルの取扱
派生ファイル(オペレーショナルファイル)の発生
マスタファイルは、各エンティティに一つのファイルが対応し、エンティティ名=ファイル名になります。イベントファイルでも原則的にそうすべきなのですが、現実には困難です。
- 月別ファイル
売上ファイルのような大量ファイルは、物理的に月別にしないと効率が悪くなる。 - 累積ファイル
時間的な推移を調べたいときには、月別、年度別になっている複数のファイルを一つのファイルにまとめたほうが取り扱いやすい。 - サマリーファイル(集計ファイル)
イベントで発生した個々のデータ(ディテールデータ)ではなく、あらかじめ得意先や商品に月次集計したサマリーファイルを用いても得られる帳票類は多くありますし、そのほうが効率的です。ところが、その集計するキーが多様であり、多くの派生ファイルが存在します。 - 抽出ファイル
部門別にディテールデータをもつほうが便利な場合もあります。これも特定の商品、得意先など抽出するキーが多様であり、多くの派生ファイルが存在します。 - 項目選択ファイル
データ容量を小さくして効率化を図るため、セキュリティのためなどの理由で、特定の項目(給与や成績など)を削除して公開するファイルです。 - これらを組み合わせた派生ファイル
比較的、数は少ないのですが、マスタファイルでも項目選択による派生ファイルがあります。
- マスタファイルの項目には基幹業務系システムで使う項目は少ない。その項目を外すことにより、基幹業務系システムの処理効率が増大する。
- マスタ間の照合処理を減らすために、例えば、商品マスタに商品区分名称を入れておきたい。
- セキュリティの観点から、マスタファイルから特定の項目(給与や成績など)を削除しておきたい。
あまりにも派生ファイルが多いと管理できなくなります。ハードウェアやソフトウェアの発展により、効率性による派生化は、ある程度無視したほうが適切ですが、それでも多くの派生ファイルが存在します。
最も重要な派生化は、基幹業務系システムと情報検索系システムでのファイル分離です。エンドユーザが直接に基幹業務系システム用のファイルをアクセスするのは、効率面でも安全面でも不適切なので、同じ内容であっても、情報検索系システム用のファイルを作成すべきです。しかしここでは、説明の都合上、同じファイルを用いることとします。
派生化での留意事項
派生化に当たって、次の事項に留意することが重要です。
- 派生ファイルだけが存在して、正規化ファイルが存在しないような状況にしないこと
すなわち、必要に応じて正規化ファイルから派生ファイルが作れる環境にしておくこと - 場当たり的な派生ファイル作成を禁じること
使い捨ての一時ふぁいるならよいが、継続的な利用、複数人の利用の場合は承認手続きが必要 - 派生ファイルにした条件を明確にしておくこと(後述のファイル説明書参照)
そして、すぐに物理的な派生ファイルを作るのではなく、次の順序で行うべきです、
- 当初は不便・非効率でも正規化ファイルを用いる。
ハードウェアやソフトウェアの投資で解決するのが結局は安上がりになる - よく使う処理に関しては、ビューを用いて「便利さ」を実現する
利用者にとっては、それで解決したように思われる。ターンアラウンドは遅いが。 - 効率が問題になった段階で、そのビューを実体化する(派生ファイルの作成)
ファイル説明書の作成
イベントファイルでは内容解説が重要
マスタファイルでは内容がほぼ自明なので、ファイル説明書は不要かもしれません。しかし、イベントファイルでは、これが非常に重要になります。エンドユーザが情報検索系システムを使わない(使えない)のは、使い方が難しいというよりも、これが整備されていないため、得られた値が自分が理解している値と大きく異なるので信用できないことが原因であることが多いのです。
- そのファイルにあるデータの時期の範囲を明確にする必要があります。
- 抽出ファイルでは、作成者が意識せずに抽出している場合があります。例えば、売上ファイルの数量を合計すれば全社全商品の売上高になるのか、例外はあるのかなどです。
- 特に数量や金額の説明が重要です。10個の売上があり2個の返品があったとき、データは8の一つだけか、10と-2の2つのデータがあるのかなどについて、明確な解説をする必要があります。それが不明確だと、実際の販売は8なのに、12になったりします。
ファイル説明書の内容
ファイル説明書には、次の内容が必要です。定義以外の項目は検索や一覧表表示に使うものです。
・1行定義
・厳密な定義をした文書へのリンク
・ファイル-項目対照表でのファイル名
・対象年月
・サマリー単位(月別、年月程度の区分)
・全数/抽出区分(有無程度)
対照表の作成
ファイル-項目対照表の作成
これの目的は自明でしょう。指定したファイルに含まれる項目は何か、指定した項目をもつファイルは何かを検索するためです。
そのため、全ファイルと全項目を網羅することが重要です。マスタファイルではマスタ説明書は不要かもしれないといいましたが、この対照表には加えなければなりません。イベントファイルでは、年月日、数量、金額などはマスタにならないといいましたが、対照表にはこれらも加えなければなりません。
ファイルに含まれる項目のリストをファイルデザインといいますが、一般に、あるファイルを設計したとき、ファイルデザインは必ず作成するはずです。また、実装されているデータベースから簡単にリストがとれます。網羅性を保証するためには、ファイルデザインからこの対照表を作るのが適切です。
あるいは、あえて対照表を作らず、ファイルデザインをそのまま検索するほうが間違いがないといえます。そのとき、項目からファイルを検索する効率の高いツールが必要になります。
ファイル-項目対照表の作成
ファイル-項目対照表の目的
この目的は、主としてエンドユーザへの基幹業務系システム利用の便宜を図ることにあります。エンドユーザとしては、いかに他の辞書が整備していても、手っ取り早く実物やひな型を利用したいと思います。あるいは、他の辞書は、この対照表にない処理をしたいときの補助的な位置づけだともいえます。
自分のニーズにそのまま使える帳票が基幹業務系システムで出力されているのに、エンドユーザはそれを知らないで、自分で出力しようとしていることがよくあります。また、既存の帳票はないが、それに似た情報を出力するプログラムがあれば、それを一部修正することは、白紙の状態からプログラムを作るよりもはるかに容易です。
この対照表は、既存帳票や類似プログラムを簡単に発見できる仕組みを提供するものです。
ファイル-項目対照表の内容
通常では、ある情報を出力するには、一つのイベントファイルを入力にして、いくつかのマスタファイルにある項目により、抽出や集計をして、マスタファイルにある名称を取り出して編集するという処理になります。それで、イベントファイル名と帳票・プログラム名との対照表があればよいことになります。さらに、その検索を便利にするような情報があればなおさら結構です。
帳票とプログラムとで、対照表に入れるべき情報は異なりますが、利用者はどちらにあるか知らないのですから、一つのファイルにしたほうが便利です。
共通
・イベントファイル名
・プログラム名または帳票名
・プログラム/帳票区分
・検索用キーワード
プログラム
・プログラムのファイルへのリンク
・プログラム説明書へのリンク(プログラム内に記述されていれば不要)
帳票
・帳票のひな型(実際に数字がはいっており、注釈を上書きされていれば最適)
・帳票の説明書へのリンク(内容説明、配布先、配布時期など)
- 帳票の表示は、帳票の印刷用紙を示したのでは役に立ちません。実際に主力した帳票のうち、代表的なページをPDFにして、注釈を上書きしておくのが便利です。
- 最近のプログラムは、プログラムコードを記述するのではなく、画面を操作しながら作成する環境になってきました。特に、エンドユーザ用のツールはそうなっています。
これは便利な環境なのですが、ここでの「類似プログラムの一部修正」的な活用の場合は、その説明をするのが大変です。むしろ、SQLプログラムに修正すべき個所を示したほうが、使う側にも簡単だということもあります。 - エンドユーザが新規あるいは修正したプログラムを(できればベテランがチェックして注釈を加えて)、この対照表に加える制度を設けると、自動的に充実します。
トピックス
イベントファイルからの情報入手の利便化
辞書機能を拡大する
辞書やファイルが整備されたとして、これだけでエンドユーザは円滑にほしい情報が入手できるでしょうか? 例えば、利用者が「コダマ電器へのテレビの売上高」がほしいとします。そのために、利用者はどのようなことをするのでしょうか? そのプロセスをシミュレーションすると、以下のようになります。
質問文の整理
- 「得意先=コダマ電器」「商品区分=テレビ」であることを知らなければなりません。エンティティは多いのですから、「得意先」「商品区分」という名称を暗記しているとは思えません。しかも、英字名やコードが必要かもしれません。
「コダマ電器」を入力して、「エンティティ=得意先」「コダマ電器の得意先コード=1324」を出力する機能が求められます。すべてのマスタファイルをスキャンすれば得られるでしょうが、かなり面倒です。名称、エンティティ、コードだけを集めた対応表があれば便利です。 - あるいは「コダマ」や「TV」と与えるかもしれません。
名称に同意語を付ける必要があります。 - 「売上高」は、イベントファイルの項目であること、その項目名は「金額」となっているかもしれません。あるいは、イベントファイルには「数量」だけがあり、単価マスタから単価を得て計算するのかもしれません。
これをサポートする機能はかなり困難です。 - これだけでは条件が不足しています。対象年月(の範囲)、集計のレベル(全合計、商品別集計、明細など)が必要になります。これらの指定が必要なことを利用者が知っていなければなりません。
最も単純な支援方法は、対象となるイベントファイルの項目リストを表示して、それぞれに抽出条件、集計順位、出力項目指定などを入力させる方法です。しかし、利用者がどの項目を指定すればよいかを知らないと、面倒な作業になります。しかも、この段階では対象となるイベントファイルが特定されていないのです。
必要なファイルの特定
- イベントファイルに、該当する期間を含み、「得意先コード」「商品区分コード」「金額」の項目があり、データのなかに「コダマ電器」「テレビ」があるファイルが見つかれば、それがランクの高い候補になります。それを利用者はどのようにして探すのでしょうか?
これには、ファイル-項目対照表により、「得意先コード」と「商品区分コード」をもつファイルを検索する機能がそのまま利用できます。このとき、得意先マスタと商品区分マスタを探すのも容易でしょう。 - 商品区分コードをもつイベントファイルがなくても、商品コードをもつがあれば、商品マスタと商品区分マスタから「テレビ」に該当する商品コードがわかるのですから、それを利用すればよいことがわかります。では、どのようして、商品コードを探せばよいと気づくのでしょうか?
商品コードを親に持つエンティティを探すのは容易です。子のマスタファイルには親エンティティのコードがあるはずですから、項目説明書やファイル-項目対応表でマスタファイルだけについて検索すればよいことになります。 - ところが、商品区分を親に持つエンティティが複数ある場合、どれが求めるものかを特定する機能はおそらく困難でしょう。さらに、親-子-孫のように複雑なルートで関連づける必要がある場合、検索エンティティを特定するためには複雑なロジックになります。
複雑なロジックのツールを作るよりも、エンティティの関連を図化したER図やクラス図を表示するのが簡単です。これらは、項目説明書を作成する段階で必ず作る図ですし、図を作成する機能はデータベースが標準機能としてもっています。利便性をあげるために、該当するエンティティを中央に表示してスクロールできるようにすること、その図に適切な情報を加えておく程度の工夫をすればよいでしょう。 - このようにして、求める情報に必要なファイルの候補を探したところ、イベントファイルには当月だけか/当月を含む累積ファイルか、サマリーファイルかディテールファイルか、多様な派生ファイルがあります。そのなかから最も効率的なファイルを特定することになります。
関連するマスタファイル数が少ないこと、イベントファイルのデータ数が少ないことを基準にすればよいでしょうが、それ以外にもあるかもしれません。いずれにせよ、候補のリストを優先順にリストして、利用者に特定させる機能があれば便利です。そのためには、ここまでのプロセスで、候補になったものを記録しておく機能が必要になりますが、かなりややこしいシステムになりそうです。
プログラムの自動生成
- ここまでで、入力となるイベントファイルと必要とするマスタファイルが特定できました。抽出条件や集計方法も明確になっています。しかし、利用者はこれからSQLプログラムを作成する必要があります。
これらの情報が適切に与えられていれば、SQLプログラムを自動生成するシステムを作ることは、専門家にとっては比較的容易です。しかし、上記の操作から、情報を自動生成システムに受け渡すシステムはかなり複雑になりましょう。 - 自動生成されたプログラムがあり実行結果が得られるとしても、おそらく抽出・集計したデータのファイルが得られるだけでしょう。小計・中計・大計などの処理はされていません。さらに、利用者は出力画面や帳票の体裁を重視します。グラフにしたいこともあります。
この要求は多様ですので、そこまで対応する機能を実現するのは不可能です。それで、ここで得られたデータファイルをExcelのワークシートに転送して、それ以降の加工は利用者に押し付けるのが適切です。
このように、利用者は、情報を得るために多様な知識を駆使して多くの作業を行う必要があります。それをすべてサポートすることは困難ですし、このプロセスを統合的に管理するシステムを実現するのはさらに困難です。しかし、部分的な機能は比較的容易に実現できましょう。その機能を実現するために、辞書にどのような情報を与えればよいかを検討し、逐次拡充していくことが重要です。
機能拡大よりも「ファイル-処理対照表」の充実を
このような汎用的な機能拡大を図ることは、労力がかかるわりには利用者の利便につながらないこともあります。むしろその労力を「ファイル-処理対照表」での「ひな型プログラム」の拡充に注ぐほうが現実的です。
実際には、情報検索系システムで利用される分野にはバラツキがあります。各利用者にとっては、自分が利用するファイルはかなり限定されます。そのため、汎用的なツールよりも、目的に限定されたツールのほうが使いやすいのです。
また、情報検索系システムの提供方式では「1をクリックすれば○○集計表、2ならば△△分析表」というようなメニューを作成して提供する方式があります。これは利用者にとって便利なのですが、そのメニューを作成するIT部門の負荷が増大しますし、利用者は提供された情報しか入手できません。
「ファイル-処理対照表」は、そのメニュー提供を汎用化したものだといえます。しかも、ひな型から派生したプログラムも新ひな型になるので、利用に伴い自動的にメニューが増大するという利点があります。
このひな型でのプログラム言語は任意ですが、一般的にはSQLが適しています。そのため、利用者がSQLの基本程度を理解していれば、ひな型の提供が容易になる効果があります。
利用者に「データの正規化」を習得させることが重要
上記のシミュレーションで推察できるように、利用者の知識が高ければ作業が円滑にできます。その最も重要な知識は、どのような項目やファイルがあるのか、その内容はどうかの知識ですが、これは辞書の整備で解決できます。
追加機能に関連する知識では、イベントファイルとマスタファイルの照合、マスタファイル間での親子関連などに関する知識、すなわちデータの正規化に関する知識です。この知識が十分ならば、ここで掲げた追加機能の大部分は不要になるか、あるいは、簡単な機能で十分になります。SQLプログラムも、ひな型を修正する程度ならば、理解するのが容易になります。
データの正規化は、理論は簡単なのですが、実際に適用する知識にするのは訓練が必要です。それには「項目説明書」の作成に利用者を参加させ、その作業を通して理解させるのが最も簡単であり効果的です。
一般文書との相互活用
無理な項目列挙は無駄になる
例えば、得意先マスタを設計するとき、「業種」「積極性」「当社への忠誠度」など多様な項目を加えてコード化したくなるものです。これらを列挙するのは大切ですが、それをマスタの項目として設定するかどうかは検討する必要があります。
当初は意気込んで入力しても、基幹業務系システムで用いることがないので義務化されません(主管部門の項目を入れることは義務化に役立ちますが)。それで、更新されなかったり、新規得意先では「その他」や「空白」ばかりになったりします。これでは使いものにならないばかりか、誤った利用をされるかもしれません。維持できないことはしないほうがよいのです。
文書ファイルへのリンクを入れる
でも、このような情報があるのに活用しないのはもったいないことです。それで、当初はコード化せずに、このような情報が記載されている文書へのリンクを項目にしておくのです(その分類に工夫がいるでしょうが)。そして、多くの得意先に同じ項目の情報が集まるようになった時点でコード化して、項目とすればよいのです。これならば「中途半端」でも役に立ちます。
このような文書には、地図、外観、商談報告など多様なものがあります。それらをバラバラにしておかずに、統一した体系で保存します。それだけでも、社内検索エンジンで検索するのが容易になります。
そして、それらの文書とマスタファイルとの相互リンクを作ります(中間に「文書リンク集」が必要になる場合が多い)。それにより、ある得意先への売上状況の変化を調べたときに、商談を参考にすることができますし、社内検索エンジンでヒットした得意先の売上情報を知ることもできます。
文書と「ファイル-処理対照表」の連携
文書がHTML(JavaScript)など外部プログラムを呼び出せる形式で作られており、「ファイル-処理対照表」を操作するプログラムがあれば、文書のなかから「ファイル-処理対照表」のひな型を呼び出し、一部修正して、その結果を文書内で表示させることもできます。
例えば、報告書文書で、ひな型の「年月」だけを修正するだけで、データの部分を最新の状態にすることができます。このような用途は多いと思われます。
ベンダへの要望
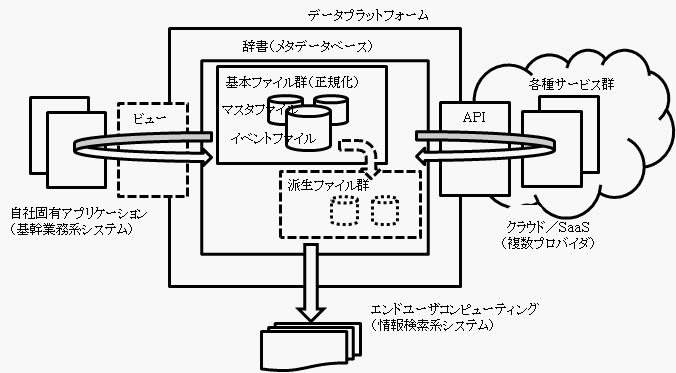
SaaSベンダへの要望
最近、多数のソフトウェアベンダがSaaSやクラウドコンピューティング(ここでは両者をSaaSで代表させます)を提供するようになりました。IT化での初期費用が低減されることから、中小企業(特に小企業)でのIT化の最初の壁を低くするのに適切な環境であるとして、経済産業省ではJ-SaaSを推進しています。
ところが現段階でのSaaS提供環境は未だ不十分です。異なるベンダのサービス(機能)間でインタフェースの統一がとれていないために、A社の受注サービスとB社の出荷サービスを連携させるのが難しい状況です。このような状況では、SaaSの最大の目標である「各ベンダのサービスの良いとこどり」が実現できず、特定のベンダに丸投げになってしまうことになりかねません。
この方法論からの視点では、ここで掲げたファイル群や辞書が「データのプラットフォーム」であり、それを基盤として、個々のサービスを呼び出して活用するようにしたいのです。具体的には、
・ここでのファイルを各サービスでのファイルを仮想的にマッピングする手段
・各サービスで用いる項目名(エンティティ名)などのカスタマイズ化
(操作画面や出力帳票での表示項目名をユーザが変更できること)
・情報検索系システム利用との矛盾のない環境
を推進してほしいのです。
それにより、SaaSの利用がさらに活発になると思われます。
BIベンダへの要望
エンドユーザ利用環境ではBI(ビジネスインテリジェンス)が普及しつつあります。その一つの機能として「ファイル-処理対照表」を利用目的に応じてカスタマイズしたものを提供するような仕組みがあれば、BIを構築するのが容易になると思います。
実は、この方法論は机上の産物であり、実装ツールがありません。私はレガシー環境で、この方法論を展開し、部分的なツールを実装した経験があるのですが、オープン環境、Web環境での経験がありません。このような方法論はオープン環境、Web環境でこそ、効果が高いと思います。本方法論を支援するツールをサービスにできないでしょうか。
おわりに(蛇足)
本書の目的の裏側
「IT素人集団がはじめて」システム設計をする方法論を示しました。ところどころに専門家の協力が必要なこともありますが、大局的には「この程度ならできる」と納得いただけたのではないでしょうか。
実は、ベンダに委託する場合でも、これらの事項はユーザがやらされることなのです。文書や図表にする作業はベンダが行うにせよ、その内容はユーザへのヒアリングを通して得たものなのです。わざわざヒアリングでベンダに教えるためにカネを払うのは不合理ですので、その部分は独力でやってしまおうという目的でもあります。
この方法論のもう一つの目的は、情報検索系システムによるエンドユーザの自主利用を自明のこととしていることです。現在の情報システムの最大の課題に、保守改訂の容易化があります。経営環境が変化しているのに、活動を規制している基幹業務系システムの保守改訂が追い付かず、タイミングを失しています。本来は経営戦略にITを活用するのが任務のIT部門は、保守改訂やエンドユーザからの頻繁な要求により硬直化しています。
このような環境を打破するには、エンドユーザが自ら情報入手をする情報検索系システムの普及が最も効果的です。それには、エンドユーザに辞書作りなどに参加させて、その気にさせることが必要です。これは、IT化が進んでいない「IT素人集団」では、なおさら重要なことですし、反面、当初からエンドユーザを引き込むのに適した環境なのです。
本書批判
本書では、大きな矛盾があります。辞書の大部分は、情報検索系システムを支援するための仕組みです。ところが、本文中でも記述しているように、基幹業務系システムと情報検索系システムのファイルは分離すべきなのです。それはエンドユーザの故意や過失による破壊や改ざんから基幹業務系システムのファイルを守ること、基幹業務系システムの処理を妨げないことも重要ですが、それ以前に、両者ではファイルのデータが異なるのです。
基幹業務系システムは会計監査や内部統制の対象になります。返品の例では、販売伝票と返品伝票が発行されるのですから、データも販売と返品の二つがないと困ります。販売伝票に誤りがある場合も、それを取り消す伝票と、正しい伝票の3伝票があるように、データも三つ存在するはずです。ところが情報検索系システムでは、結果がほしいだけなのですから相殺した一つのデータにしたほうが取り扱いやすいのです。月をまたがった返品についても、前月ファイルに遡及して修正したおいたほうが便利です。
このようなことを考慮すると、辞書の多くは、基幹業務系システム用と情報検索系システム用の二本立てにするのが適切な場合が多いのです。また、そうしたときには、項目や説明もIT部門向けとエンドユーザ向けで表現を変えるほうがよい場合もあります。本書では、記述の都合上、このような重大事項をほほかぶりしています。
実際にこの方法論を導入するのに、大きな課題があることを隠しています。項目説明書では、エンドユーザがイベントファイルとマスタファイルの間、マスタファイル間での照合について理解できることを前提にしています。ところが現実には、それを理解して円滑に扱えるには、かなりの論理的思考の訓練が必要なのです。それを本書では冒頭に「読者は論理的な思考に慣れている」ことを条件として逃げています。
そのようなごまかしがあるため、IT知識が高い人のほうが、この方法論に対する評価が高いのではないかと思います。冒頭の「IT活用の経験が長い大企業でも~」は、暗にその言い逃れです。
本書で繰り返しているように、この方法論はそれ自体がかなり雑であり自由度が高いものですし、中途半端でも作業が無駄にならないという特徴があります。本書の矛盾を適当な工夫で回避して、本書の表と裏の目的を実現されるよう期待しております。