スタートページ> JavaScript> 他言語> Python 目次> → 機械学習 パターン認識
ここでは、「機械学習」の「教師あり学習」のモデルとして「二値分類モデル」を取り扱います。
二値分類モデルとは、ある特性をもったデータが正群・負群のどちらに属するかを判定するモデルです。統計学での解法では、判別分析がありますが、ここではAI(機械学習)のアプローチでモデル化します。
教師あり学習とは、まず訓練用(学習用:trainning)として、正解つきのデータをコンピュータに与えて、コンピュータが何らかの方法で、正解を求める判別モデルを生成します。次に、検証用(評価用:test)のデータを与えて計算させ、それと正解データとの一致度を調べて、モデルの信頼性を評価する方法です。
「何らかの方法」といえ、人間が基本となる方法を与える必要があります。ここでは単純なニューラルネットワークモデルを採用します。すなわち、ここでのモデルは、非常に単純化したニューラルネットワークモデルの説明でもあります。
(1)入力データ 訓練用(学習用:trainning)データ 教師付き学習によりモデルを作成する 検証用(評価用:test)データ 作成されたモデルに新データを入力して精度を評価する (2)ニューラルネットワークモデルの定義 ニューラルネットワークモデルの構造は、隠れ層の段数と各層のニューロンの個数で決まります。 (参照:http://www.kogures.com/hitoshi/others/neuro/playground.png) 段数が多く、ニューロンが多ければ、精度の良いモデルになりますが、処理時間が長くなります。 そのため、まず簡単なモデルで実験し評価をして、必要に応じて追加することになります。 (3)学習方法の設計と最適化 モデルの作成とは、ノードを結ぶシナプスに重みを与えることですが、多数の計算方法があります。 これも試行錯誤が必要ですが、当面の方法を指定することになります。 (4)学習経過 (2)(3)で設計したモデルに(1)で用意した訓練用データを与えて、モデルを作成します。 学習した結果をグラフや表で示します。 (5)学習結果、判別式の表示 各シナプスの重み、ニューロンのバイアスの値を表示します。 (6)評価用データによる評価 (4)のモデルに評価用データを入力して、個々のデータが正群・負群のどちらになるかを計算します。 その結果が、事前に用意した評価用区分表と比較することにより、精度を評価します。 精度に満足できなければ、(2)や(3)を変更して試行錯誤を繰り返します。 (7)新データの判別 ここまででモデルが完成したとして、データを与えたときの判別をします。
特性値 X(x1, x2) と、その区分 y(正群/負群=1/-1)からなる大量の組(ここでは81組)があります。
そのうちの大部分(ここでは63組)を教師付き学習用のデータ(train)とし、それを用いてコンピュータが生成したルールの信頼度を評価するデータ(test)(ここでは18組)に分けます。
本来は、元の81組からランダムにtrainとtestに分けるのですが、そのステップは省略しています(入力データでの train の歯抜けの要素が test になったとしています。)
ここでは、x1+x2 ≧0ならばy=1、<ならばy=-1となるようにしていますが、あえていくつかを、異なる値を正解だとして与えています。当然、システムにはそれを知らせていません。
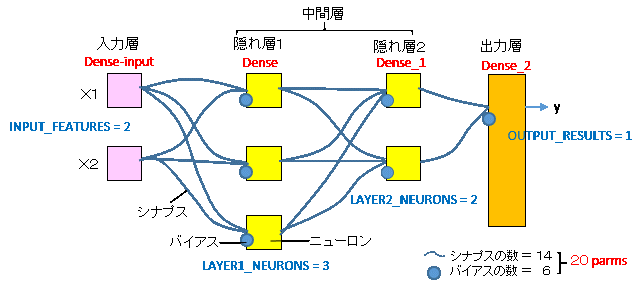
ルールはコンピュータが考えるとはいっても、それを探すための骨組みは人間が与える必要があります。ニューラルネットワークモデルでは、例えば下図のようなモデルを設定します。中間層(隠れ層)の段数を多くし、各層の段数を多くする(ニューロンの数を多くする)ことにより、人間の頭脳に近い判断ができるでしょうが、ここでは非常にシンプルなモデルにしました。
機械学習(コンピュータにルールを発見させる)とは、 X-train を y-train に一致させるように各シナプスとバイアスの重みを計算させることです。
Python系でのニューラルネットワークモデル関係の定番な拡張モジュールに tensorflow があります。
import tensorflow as tf
として利用できます。これを用いれば、図のモデルは次のように表示できます(図の青字部分)
INPUT_FEATURES = 2 # 入力の特性数:(Χ1とΧ2) 2
LAYER1_NEURONS = 3 # 隠れ層1のニューロンの数: 3
LAYER2_NEURONS = 2 # 隠れ層2のニューロンの数: 2
OUTPUT_RESULTS = 1 # 出力結果の数(二値分類では1に固定)
あるニューロンが入力信号を受け取り、次のニューロンへと伝播する際の変換関数のことです。
脳と同様に弱い入力信号なら出力しない。次第に強さに応じた強さで出力するが、ある強度に達すると一定にします。
このような変換関数には、シグモイド関数(Sigmoid function)、tanh関数(Hyperbolic tangent function)などがありますが、その特徴などは省略します。
ACTIVATION = 'tanh' # 活性化関数: tanh関数
ここでのモデルの定義とは、モデルの構成と各層(layer)の特性、活性化関数などを組み合わせて、実際の計算に必要なモデルを定義することです。
tensorflow の Keras モジュールを使って記述します。
Kerasによるモデルの定義方法には次の3つがあります。 Sequential(積層型)モデル: コンパクトで簡単な書き方 Functional(関数型)API: 複雑なモデルも定義できる柔軟な書き方 Subclassing(サブクラス型)モデル: 難易度は少し上がるが、フルカスタマイズが可能 layers(レイヤー;層)の定義方法も数種類あります。 ここでは、ニューラルネットワークで通常の全結合レイヤーであるDenseレイヤーを用います。 下のように隠れ層(layer)内でのニューロンを増やすにはunitsの数を増やします。 隠れ層を増やすには、tf.keras.layers.Dense を追加します。 model = tf.keras.models.Sequential([ tf.keras.layers.Dense( #入力層 input_shape=(INPUT_FEATURES,), # 入力の形状 # 隠れ層1 units=LAYER1_NEURONS, # ニューロンの数 activation=ACTIVATION), # 活性化関数 tf.keras.layers.Dense( # 隠れ層2 units=LAYER2_NEURONS, # ニューロンの数 activation=ACTIVATION), # 活性化関数 tf.keras.layers.Dense( # 出力層 units=OUTPUT_RESULTS, # ニューロンの数 activation='tanh'), # 活性化関数(※tanh固定) ])
表形式
print(model.summary())
図形式
tf.keras.utils.plot_model(
model,
show_shapes=True,
show_layer_names=True,
to_file='model.png')
from IPython.display import Image
Image(retina=False, filename='model.png')
次の出力が得られます。
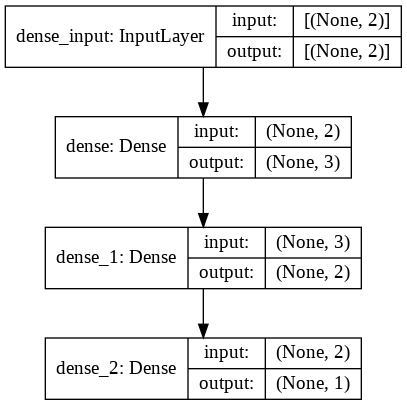
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 3) 9 _________________________________________________________________ dense_1 (Dense) (None, 2) 8 _________________________________________________________________ dense_2 (Dense) (None, 1) 3 ================================================================= Total params: 20 Trainable params: 20 Non-trainable params: 0
ここまででモデルができました。ここからは実際に計算する段階になります。このように2つのステップにわけるのは、機械学習では1回の試行で満足する結果が得られるのではなく、試行錯誤を重ねる必要がありますが、モデル全体の変更にまで戻るよりも、最適化の条件を変えるほうが簡便だからです。ここでの試行錯誤で満足できる結果が得られないときに、モデルの変更に戻ります。
Keras 自体はテンソル積、畳み込み等々の低レベルな操作は処理しないので、この処理に特化し最適化されたテンソル操作ライブラリであるバックエンド・エンジンを用います。それで、関数の形になります。
(なお、近年はこの方法ではなく、tf.keras を利用するようになりましたが、ここでは省略します。)
import tensorflow.keras.backend as K def tanh_accuracy(y_true, y_pred): # y_trueは正解、y_predは予測(出力) threshold = K.cast(0.0, y_pred.dtype) # -1か1かを分ける閾値を作成 y_pred = K.cast(y_pred >= threshold, y_pred.dtype) # 閾値未満で0、以上で1に変換 return K.mean(K.equal(y_true, y_pred * 2 - 1.0), axis=-1) # 2倍して-1.0することで、0/1を-1.0/1.0にスケール変換して正解率を計算
損失(loss)とは、最適化モデルにX_train のデータを入れて計算した予測値と、y_trainの正解値の差のことです。# 不一致の度合いといってもよいでしょう。逆に一致度は精度(accuracy)といいます。
最適化とは、損失を最小にするために、パラメタ(重み)を適宜更新することです。その更新方法には、一般には微分になりますが、SGDやAdamなどがあります。
学習率とは、最適化アルゴリズムでの刻み幅のようなものです。学習率が低すぎると進行せず、学習率が高すぎると不安定になり、収束しません。
予測値(tanh_accuracy)と正解値(y_train)の差の尺度を平均二乗誤差とし、それを最小にする(正解率を高める)ようなパラメタ(重み)を探すために、確率的勾配降下法で学習率3%の刻みで学習させるモデルを生成します。
LOSS = 'mean_squared_error' # 損失関数: 損失の尺度を平均二乗誤差とする
OPTIMIZER = tf.keras.optimizers.SGD # 最適化:確率的勾配降下法
LEARNING_RATE = 0.03 # 学習率: 0.03
model.compile(optimizer=OPTIMIZER(learning_rate=LEARNING_RATE),
loss=LOSS,
metrics=[tanh_accuracy]) # 精度(正解率)
X_train が y_train の正解に一致した組数の割合を正解率(accuracy)といい、誤差を損失値(loss)といいます。最適化とは、正解率を大に、損失値を最小にするように、パラメタ(シナプスとバイアス、ここでは20個ある)の値を決定することです。
最適化は逐次改善で行います。train を batch_size という少量のデータ(BATCH_SIZE)に分けて行います。
それをさらに、最適化(学習)に用いるデータ(狭義の train)とここでの検証用のデータ(valid)に分けます、その比率をVALIDATION_SPLITとして与えます。
このバッチでの最適化処理をエポックといいます。それを繰り返しながら、パラメタの値を改善していきます。その打切り回数をエポック数(EPOCHS)といいます。
BATCH_SIZE = 10 # バッチサイズ: 15(選択肢は「1」~「30」) EPOCHS = 30 # エポック数 VALIDATION_SPLIT = 0.2 # 精度検証用の割合
Epoch 1/30 5/5 [==================] 1s 46ms/step loss:0.421 tanh_accuracy:0.86 val_loss:0.514 val_tanh_accuracy:0.846 Epoch 2/30 5/5 [==================] 0s 8ms/step loss:0.283 tanh_accuracy:0.92 val_loss:0.442 val_tanh_accuracy:0.846 Epoch 3/30 5/5 [==================] 0s 8ms/step loss:0.241 tanh_accuracy:0.94 val_loss:0.429 val_tanh_accuracy:0.923 Epoch 5/30 5/5 [==================] 0s 8ms/step loss:0.214 tanh_accuracy:0.94 val_loss:0.404 val_tanh_accuracy:0.923 Epoch 10/30 5/5 [==================] 0s 7ms/step loss:0.178 tanh_accuracy:0.96 val_loss:0.490 val_tanh_accuracy:0.846 Epoch 20/30 5/5 [==================] 0s 7ms/step loss:0.152 tanh_accuracy:0.96 val_loss:0.585 val_tanh_accuracy:0.769 Epoch 30/30 5/5 [==================] 0s 8ms/step loss:0.142 tanh_accuracy:0.96 val_loss:0.643 val_tanh_accuracy:0.769
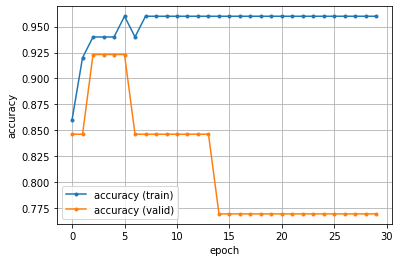
正解率(accuracy)のグラフ
import matplotlib.pyplot as plt
plt.figure()
train_acc = hist.history['tanh_accuracy']
valid_acc = hist.history['val_tanh_accuracy']
epochs = len(train_acc)
plt.plot(range(epochs), train_acc, marker='.', label='accuracy (train)')
plt.plot(range(epochs), valid_acc, marker='.', label='accuracy (valid)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('accuracy')
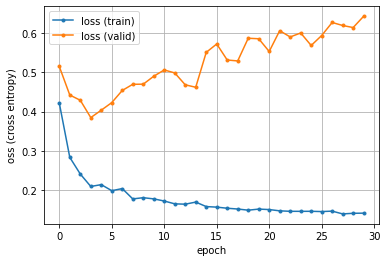
損失(loss)のグラフ
plt.figure()
train_loss = hist.history['loss']
valid_loss = hist.history['val_loss']
epochs = len(train_loss)
plt.plot(range(epochs), train_loss, marker='.', label='loss (train)')
plt.plot(range(epochs), valid_loss, marker='.', label='loss (valid)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss (cross entropy)')
plt.show()
図のように、エポックが繰り返される(試行錯誤が進む)につれて、train の正解率は大になり損失(誤差)は小になっていきます。モデルが適切ならば、検証用のデータ(valid)も同様になるべきなのですが、逆になっており、このモデルは実務的に用いるのは不適切です。過学習に陥っているようです(改善するのが面倒なので、このままにしておきます)。
場合によっては、精度検証用データの損失の結果が、次第に増加したり大きく変動することがあります。
単純にいえば、モデルが過剰に精緻になり、新しい訓練用データ(バッチデータ)により、重箱の隅をほじくる状態になるのです。そのため、パラメタの変化が激しくなり、いつも同じの精度検証用データでは、かえって損失が増大してしまうのです。
そのような状態が起きたときは、次のような手段が効果的です。
訓練用データを増やしバッチデータを大にする。
隠れ層の段数やニューロンの個数を減らす。
重みの小さいシナプスの線を削除(ドロップアウト)する。
活性化関数を工夫する。
print('model.get_weights()[0] 入力層→隠れ層1(係数)\n', model.get_weights()[0])
print('model.get_weights()[1] (バイアス)\n', model.get_weights()[1])
print('model.get_weights()[2] 隠れ層1→隠れ層2(係数)\n', model.get_weights()[2])
print('model.get_weights()[3] (バイアス)\n', model.get_weights()[3])
print('model.get_weights()[4] 隠れ層2→出力層(係数)\n', model.get_weights()[4])
print('model.get_weights()[5] (バイアス)\n', model.get_weights()[5])
入力層→隠れ層1 9個のパラメタ
model.get_weights()[0]
上 中 下 ←隠れ層1
[[-0.935, 1.060, -0.130], X1 入力層
[-0.852, 0.018, -0.321]] X2
model.get_weights()[1]
[-0.231, -0.006, -0.240] バイアス(切片)
↓
(-0.935*x1 - 0.852*x2 - 0.231) 隠れ層1上のニューロンが受け取る信号
隠れ層1→隠れ層2 8個のパラメタ
model.get_weights()[2]
上 下 ←隠れ層2
[[-0.303, 0.855], 上 隠れ層1
[-0.101, -0.083], 中
[-0.960, 0.582]] 下
model.get_weights()[3]
[ 0.152, -0.221] バイアス(切片)
↓
(-0.303*上 - 0.101*中 - 0.960*下 + 0.152) 隠れ層2上のニューロンが受け取る信号
隠れ層2→出力層 3個のパラメタ
model.get_weights()[4]
[[ 0.944], 上 隠れ層2
[-1.501]], 下
model.get_weights()[5]
[ 0.165] バイアス(切片)
↓
(0.944*上 - 1.501*下 + 0.165) 隠れ層2全体から出力層が受け取る信号
これをモデルの図に記入すると次のようになります。重みが正のシナプスは青、負は赤、太さは絶対値(強度)です。
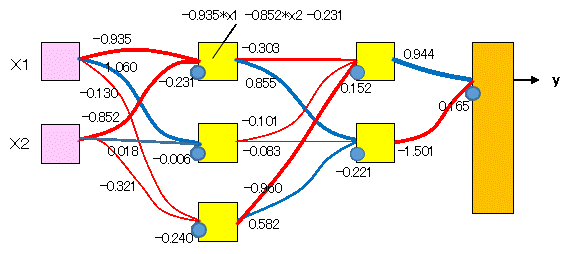
これにより、x1, x2 の値を入れれば、出力層の値が得られるのでは? と思ったのですが、合致しませんでした!
その理由は、活性化関数による補正を考慮していない(信号が低いと発火しない)からだと思われます。
result_proba = model.predict(X_test) result_class = np.frompyfunc(lambda x: 1 if x >= 0.0 else -1, 1, 1)(result_proba) # 離散化 print(result_proba) # 予測 print(result_class) # 分類
..... 入力データ ..... 結果 yと判別 x1 x2 x1+x2 符号 y スコア 判別 の違い 1 4 3 7 1 1 0.983 1 2 4 -1 3 1 1 0.970 1 3 3 1 4 1 1 0.980 1 4 3 -3 0 1 1 0.630 1 5 2 4 6 1 1 0.983 1 6 2 0 2 1 1 0.971 1 7 1 2 3 1 1 0.980 1 8 1 -3 -2 -1 1 -0.883 -1 × 9 0 -2 -2 -1 1 -0.844 -1 × 10 0 0 0 1 -1 0.866 1 × 11 -1 4 3 1 1 0.982 1 12 -1 -1 -2 -1 -1 -0.767 -1 13 -2 1 -1 -1 1 0.098 1 14 -2 -4 -6 -1 -1 -0.943 -1 15 -3 3 0 1 1 0.914 1 16 -3 -2 -5 -1 -1 -0.921 -1 17 -4 0 -4 -1 -1 -0.827 -1 18 -4 -4 -8 -1 -1 -0.947 -1 モデルの評価 score = model.evaluate(X_test, y_test) print('損失:', score[0]) # 損失: 0.637 print('正解率:', score[1]) # 正解率 0.833
判別の結果は3組がエラーになり、15組が正しく判定されました。それで正解率は 0.833=83.3% となりました。(4)で「このモデルが実務的には使えない」といいましたが、そうだと思います。もっと簡単なルールがあるのに、あえて複雑にしているのでしょう。
そもそも入力データでは「x1+x2>≧0→y=1,<0→y=ー1」をベースにして、学習データでは63組中4組を逆にしていました、そして、評価でも18組中4組を変えていたのです。すなわち学習させたデータよりも、評価用のデータのほうがベースとずれていたのです。
判別誤りがすべて変更した組であることは、この正解率よりも信頼性が高いように思われます。
実務では、毎回(1)から(6)までを行うのではなく、(6)までの結果を保存しておけば、新しい(x1,x2)のデータを与えだけで1/
ー1のどちらに属するかを簡単に判別することができます。
例えば、次の入力データを与えれば、次の判別結果になります。
x1 x2 スコア 判別 2 1 0.978 1 2 0 0.971 1 2 -1 0.947 1 2 -2 0.734 1 2 -3 -0.619 -1
実務でこのようなアプローチをするには、次のような要件を満たす必要があります。
yが1/-1の2値ではなく、複数の区分になることが多いでしょう。
xの特性も2つだけでなく、多くの特性を考慮する必要があります。
→ そのため、大量のデータが必要になります。
特性には数量的なものだけでなく、質的な特性が多いし、特性を欠くデータもあります。
→ ニューロンネットワークの規模や最適化の方法の検討が必要になります。