スタートページ> JavaScript> 他言語> Python 目次> ←判別分析
キーワード:クラスター分析、k-means法、ウォード法、行列式の値、逆行列、固有値、固有ベクトル、連立方程式
sklearn.cluster, KMeans, scipy.cluster.hierarchy, linkage, dendrogram, fcluster
下記の青線の部分をGoogle Colaboratryの「コード」部分にコピーアンドペースト(ペーストは Cntl+V)して実行すれば、右図の画像が表示されます。
クラスター分析とは「似たもの集め」です。多くの手法がありますが、ここでは
非階層型クラスタリングの「k-means法」
from sklearn.cluster import KMeans
階層型クラスタリングの「ウォード法」
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
を取り上げます。このような特定の分野では、専用のライブラリがあります
これらの機能を目立たたせるために、ここでは変数名を日本語にしています。
from sklearn.cluster import KMeans KMeans(n_clusters = 指定クラス数)
下のDataFrameを3つのグループにクラス分けします。
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
# ============ データ入力
df = pd.DataFrame([
[3, 4, 4, 5, 4, 4],
[6, 6, 7, 8, 7, 7],
[6, 5, 7, 5, 5, 6],
[6, 7, 5, 4, 6, 5],
[5, 7, 6, 5, 5, 5],
[4, 5, 5, 5, 6, 6],
[6, 6, 7, 6, 4, 4],
[5, 5, 4, 5, 5, 6],
[6, 6, 6, 7, 7, 6],
[6, 5, 6, 6, 5, 5],
[5, 4, 4, 5, 5, 5],
[5, 5, 6, 5, 4, 5],
[6, 6, 5, 5, 6, 5],
[5, 5, 4, 4, 5, 3],
[5, 6, 4, 5, 6, 6],
[6, 6, 6, 4, 4, 5],
[4, 4, 3, 6, 5, 6],
[6, 6, 7, 4, 5, 5],
[5, 3, 4, 3, 5, 4],
[4, 6, 6, 3, 5, 4]],
columns = ['c0','c1','c2','c3','c4','c5'])
指定クラス数 = 3 # 区分のクラス数
# ============ クラスタリング
計算方法 = KMeans(n_clusters = 指定クラス数) # 計算方法の指定
計算方法.fit(df) # 計算方法を df に適用
# この結果,計算方法.labels_に各行の帰属クラスのベクトルになる。
# array([1, 2, 0, 0, 0, 1, …, 1, 0, 1, 0], dtype=int32)
df['class'] = 計算方法.labels_ # df の新列 class に帰属クラスを入れる
df.sort_values('class') # class別にソートして一覧表表示
print(df.sort_values('class'))
# ============ クラスタリングとしてはこれで完了です。以下は散布図を描くため
# ============= プロット図にするには主成分分析により2軸にする必要があります。
# 主成分分析
from sklearn.decomposition import FactorAnalysis as FA
corr = df.corr() # 共分散行列
eig, eigv = np.linalg.eig(corr) # eig 固有値
eign = len(eig[np.where(eig > 1)]) # 1より大の固有値の個数 2
fa = FA(n_components=eign, max_iter=500)
fa.fit(df)
df['f1'] = fa.fit_transform(df)[:,0] # 第1因子の値
df['f2'] = fa.fit_transform(df)[:,1] # 第2因子の値
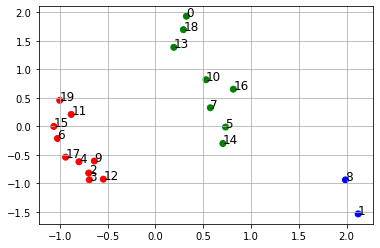
# 散布図作成
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
df.loc[df['class'] == 0, 'color'] = 'r' # クラスの色
df.loc[df['class'] == 1, 'color'] = 'g'
df.loc[df['class'] == 2, 'color'] = 'b'
df.loc[df['class'] > 2, 'color'] = 'm' # 存在しないことはわかっているが
ax.scatter(df.f1, df.f2, color=df.color)
for i, txt in enumerate(df.index): # 各点の名称表示
ax.annotate(txt, (df.f1[i], df.f2[i]), size=12) # 点の右上に表示されます。
ax.grid()
fig.show()
c0 c1 c2 c3 c4 c5 class 9 6 5 6 6 5 5 0 17 6 6 7 4 5 5 0 15 6 6 6 4 4 5 0 12 6 6 5 5 6 5 0 11 5 5 6 5 4 5 0 6 6 6 7 6 4 4 0 19 4 6 6 3 5 4 0 4 5 7 6 5 5 5 0 3 6 7 5 4 6 5 0 2 6 5 7 5 5 6 0 7 5 5 4 5 5 6 1 18 5 3 4 3 5 4 1 10 5 4 4 5 5 5 1 13 5 5 4 4 5 3 1 14 5 6 4 5 6 6 1 16 4 4 3 6 5 6 1 5 4 5 5 5 6 6 1 0 3 4 4 5 4 4 1 8 6 6 6 7 7 6 2 1 6 6 7 8 7 7 2
ウオード(Ward)法×ユークリッド
・ユークリッド距離で最も近い点を一つのクラスにする。
・そのクラスの重心を基準として、重心が近い順にさらにクラスにまとめる
・クラス数が指定クラスになるまで繰り返す。
ライブラリ scipy にそのものズバリの機能があります。
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
リンク表 = linkage(df, method='ward', metric='euclidean') # ウオード法×ユークリッドで計算せよ
次の表が得られます。
A B C D
[[ 7. 10. 1.414 2.]
[15. 17. 1.414 2.]
[ 3. 12. 1.414 2.]
[ 9. 11. 1.732 2.]
:
[32. 33. 5.210 8.]
[24. 35. 7.103 12.]
[36. 37. 8.915 20.]]
かなり加工をした後なので複雑です。下はイメージで不正確です。
A:行番号
B:同じクラスに属する行番号(複数あるので数字を増やししている)
C:A・B間のユーグリッド距離
D:グループ化されたデータの集合
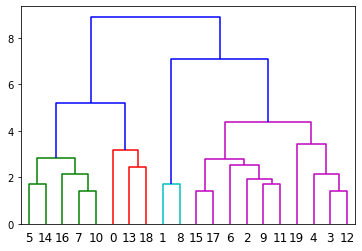
dendrogram(df, ~) リンク表を利用して図表を作成
・各行が集まってクラスになり、クラスが更に大きいクラスにまとめている状況がわかります。
・指定閾値により打切りになり、各クラスに色を付けます。
・Y軸は横線につながっている2点のユーグリッド距離。短いほど近い関係にあります。
fcluster() リンク表を利用して、df の各行の帰属クラスを取得します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
# ============ データ入力
df = pd.DataFrame([
[3, 4, 4, 5, 4, 4],
[6, 6, 7, 8, 7, 7],
[6, 5, 7, 5, 5, 6],
[6, 7, 5, 4, 6, 5],
[5, 7, 6, 5, 5, 5],
[4, 5, 5, 5, 6, 6],
[6, 6, 7, 6, 4, 4],
[5, 5, 4, 5, 5, 6],
[6, 6, 6, 7, 7, 6],
[6, 5, 6, 6, 5, 5],
[5, 4, 4, 5, 5, 5],
[5, 5, 6, 5, 4, 5],
[6, 6, 5, 5, 6, 5],
[5, 5, 4, 4, 5, 3],
[5, 6, 4, 5, 6, 6],
[6, 6, 6, 4, 4, 5],
[4, 4, 3, 6, 5, 6],
[6, 6, 7, 4, 5, 5],
[5, 3, 4, 3, 5, 4],
[4, 6, 6, 3, 5, 4]],
columns = ['c0','c1','c2','c3','c4','c5'])
行番号 = df.index # 行番号 0, 1, …, 19
指定閾値 = 0.5 # 大にするとグループ区分数が小になる
# ============ 計算
# 階層型クラスタリングの実施
# ウォード法 x ユークリッド距離
リンク表 = linkage(df, method='ward', metric='euclidean')
print('リンク表\n', リンク表) #
閾値 = 指定閾値 * np.max(リンク表[:, 2])
# 図表(デンドログラム)の出力
dendrogram(リンク表, labels=行番号, color_threshold=閾値)
plt.show()
# クラスタリング結果をdf['class']に入れる
帰属クラス = fcluster(リンク表, 閾値, criterion='distance')
# dfの各行におけるクラスからなるベクトルになります。
df['class'] = 帰属クラス
print('クラス分けした結果')
df.sort_values('class') # クラス順にソート
リンク表 ノード 距離(縦軸) 個数 [[ 7. 10. 1.414 2. ] [15. 17. 1.414 2. ] [ 3. 12. 1.414 2. ] [ 9. 11. 1.732 2. ] [ 1. 8. 1.732 2. ] [ 5. 14. 1.732 2. ] [ 2. 23. 1.914 3. ] [16. 20. 2.160 3. ] [ 4. 22. 2.160 3. ] [13. 18. 2.449 2. ] [ 6. 26. 2.516 4. ] [21. 30. 2.768 6. ] [25. 27. 2.816 5. ] [ 0. 29. 3.162 3. ] [19. 28. 3.439 4. ] [31. 34. 4.362 10. ] [32. 33. 5.210 8. ] [24. 35. 7.103 12. ] [36. 37. 8.915 20. ]] クラス分けした結果 c0 c1 c2 c3 c4 c5 class 16 4 4 3 6 5 6 1 緑 5 4 5 5 5 6 6 1 14 5 6 4 5 6 6 1 7 5 5 4 5 5 6 1 10 5 4 4 5 5 5 1 0 3 4 4 5 4 4 2 赤 18 5 3 4 3 5 4 2 13 5 5 4 4 5 3 2 1 6 6 7 8 7 7 3 青 8 6 6 6 7 7 6 3 17 6 6 7 4 5 5 4 紫 15 6 6 6 4 4 5 4 9 6 5 6 6 5 5 4 11 5 5 6 5 4 5 4 6 6 6 7 6 4 4 4 4 5 7 6 5 5 5 4 3 6 7 5 4 6 5 4 2 6 5 7 5 5 6 4 12 6 6 5 5 6 5 4 19 4 6 6 3 5 4 4