スタートページ> JavaScript> 他言語> Python 目次> ← 機械学習 二値分類モデル
パターン認識は、写真を読み込んで花の名称を特定したり、監視カメラにより特定の人物を識別するなど、AI(人工知能)の応用分野の主流の一つになっています。パターン認識の主要な方法は、多くの写真とその名称を与えて、コンピュータにルールを発見させる「教師あり機械学習」であり、ニューロンネットワークモデルを用いています。
ニューロンネットワークモデルの概要は、「機械学習 二値分類モデル」で扱いましたので、ここでは省略します。同じ章立てにしています。
パターン認識では、膨大なデータ組が必要で、モデル構築の大部分、コンピュータ資源の大部分は、データの収集と整理に費やされます。
多くの分野でラージデータが公開・提供されています。スマートフォンで花の写真を送ると直ちにその名称を教えてくれるアプリのように、既に最適化まで済んだサービスもあります。
ここでは、「手書き数字の判別」を取り上げます。手書き数字をビット列に表現したデータを入力して、0~9のどれであるかを識別するのが目的です。
手書き数字の画像のデータベースでは、mnist が有名です。
「MNISTデータベース 手書き数字」http://yann.lecun.com/exdb/mnist/
学習用(train)に6万枚、テスト用(test)に1万枚あり、画像とラベルがセットになっています。個々の画像は、28x28 のグレースケールで各画素は 0~255 の値をもっています。
次の資料からほぼコピー&ペーストでモデルを作成しました。
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 〓〓〓 入力データの確認
# x_train の形状
print(x_train.shape)
# (60000, 28, 28) 3次元配列 x_train[ページ, 画像縦, 画像横]
# x_train[0] の画像
import matplotlib.pylab as plt
fig = plt.figure()
plt.figure(figsize=(5,5))
plt.imshow(x_train[0], cmap="Greys")
plt.show()

# x_train[0] の配列データ(光の強さ0~255を0~1に正規化しています) import pandas as pd display(pd.DataFrame(x_train[0]))
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
# 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 5 0 0 0 0 0 0 0 0 0 0 0 0 0.01 0.07 0.07 0.07 0.49 0.53 0.69 0.10 0.65 1.00 0.97 0.50 0 0 0 0
# 6 0 0 0 0 0 0 0 0 0.12 0.14 0.37 0.60 0.67 0.99 0.99 0.99 0.99 0.99 0.88 0.67 0.99 0.95 0.76 0.25 0 0 0 0
# 7 0 0 0 0 0 0 0 0.19 0.93 0.99 0.99 0.99 0.99 0.99 0.99 0.99 0.99 0.98 0.36 0.32 0.32 0.22 0.15 0 0 0 0 0
# 8 0 0 0 0 0 0 0 0.07 0.86 0.99 0.99 0.99 0.99 0.99 0.78 0.71 0.97 0.95 0 0 0 0 0 0 0 0 0 0
# 9 0 0 0 0 0 0 0 0 0.31 0.61 0.42 0.99 0.99 0.80 0.04 0 0.17 0.60 0 0 0 0 0 0 0 0 0 0
# 10 0 0 0 0 0 0 0 0 0 0.05 0 0.60 0.99 0.35 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 11 0 0 0 0 0 0 0 0 0 0 0 0.55 0.99 0.75 0.01 0 0 0 0 0 0 0 0 0 0 0 0 0
# 12 0 0 0 0 0 0 0 0 0 0 0 0.04 0.75 0.99 0.27 0 0 0 0 0 0 0 0 0 0 0 0 0
# 13 0 0 0 0 0 0 0 0 0 0 0 0 0.14 0.95 0.88 0.63 0.42 0 0 0 0 0 0 0 0 0 0 0
# 14 0 0 0 0 0 0 0 0 0 0 0 0 0 0.32 0.94 0.99 0.99 0.47 0.10 0 0 0 0 0 0 0 0 0
# 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.18 0.73 0.99 0.99 0.59 0.11 0 0 0 0 0 0 0 0
# 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.06 0.36 0.99 0.99 0.73 0 0 0 0 0 0 0 0
# 17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.98 0.99 0.98 0.25 0 0 0 0 0 0 0
# 18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.18 0.51 0.72 0.99 0.99 0.81 0.01 0 0 0 0 0 0 0
# 19 0 0 0 0 0 0 0 0 0 0 0 0 0.15 0.58 0.90 0.99 0.99 0.99 0.98 0.71 0 0 0 0 0 0 0 0
# 20 0 0 0 0 0 0 0 0 0 0 0.09 0.45 0.87 0.99 0.99 0.99 0.99 0.79 0.31 0 0 0 0 0 0 0 0 0
# 21 0 0 0 0 0 0 0 0 0.09 0.26 0.84 0.99 0.99 0.99 0.99 0.78 0.32 0.01 0 0 0 0 0 0 0 0 0 0
# 22 0 0 0 0 0 0 0.07 0.67 0.86 0.99 0.99 0.99 0.99 0.76 0.31 0.04 0 0 0 0 0 0 0 0 0 0 0 0
# 23 0 0 0 0 0.22 0.67 0.89 0.99 0.99 0.99 0.99 0.96 0.52 0.04 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 24 0 0 0 0 0.53 0.99 0.99 0.99 0.83 0.53 0.52 0.06 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 25 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 26 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 27 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 〓〓〓 モデルの定義 ここでは、mnist にある例示をそのまま使いました。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
#入力層 入力データ 28x28 を1組とする
tf.keras.layers.Dense(128, activation='relu'),
# 通常の隠れ層 # ニューロン数128
# relu:正規化線形関数 x<0 のとき0, x>=0 ならそのまま
tf.keras.layers.Dropout(0.2),
# ドロップアウト 後述
tf.keras.layers.Dense(10, activation='softmax')
# 出力層 # 数字0~9に対応したニューロンを設置
# softmax クラス分け。「提示画像がその数字である確率」を示す。
])
# 〓〓〓 モデルの表示
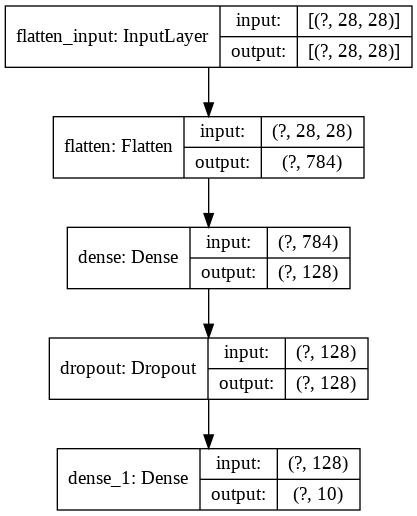
print(model.summary())
tf.keras.utils.plot_model(
model,
show_shapes=True,
show_layer_names=True,
to_file='mnist-model.png')
from IPython.display import Image
Image(retina=False, filename='mnist-model.png')
# Model: "sequential_2"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# flatten_1 (Flatten) (None, 784) 0
# _________________________________________________________________
# dense_2 (Dense) (None, 128) 100480
# _________________________________________________________________
# dropout_1 (Dropout) (None, 128) 0
# _________________________________________________________________
# dense_3 (Dense) (None, 10) 1290
# =================================================================
# Total params: 101,770
# Trainable params: 101,770
# Non-trainable params: 0
# _________________________________________________________________
特に特徴量/ニューロンの数が多い複雑なネットワークの場合は、本来は不要なニューロン(いわばノイズ)も数多く含まれています。そのノイズを学習してしまうことで学習が安定しなかったり過学習が起きたりします。
これを回避するために、エポックごとに、一定割合のニューロンをランダムにドロップして学習します。
model.compile(optimizer='adam', # 最適化:確率的勾配降下法の一つ。大規模モデルに適する
loss='sparse_categorical_crossentropy', # 損失関数:x_trainが配列でy_trainが整数の場合によく用いられる
metrics=['accuracy']) # 評価尺度:正答率
hist = model.fit(x_train, y_train, epochs=5)
# 〓〓〓 グラフ表示
import matplotlib.pyplot as plt
plt.figure()
train_loss = hist.history['loss']
train_acc = hist.history['accuracy']
epochs = len(train_loss)
plt.plot(range(epochs), train_loss, marker='.', label='loss (train)')
plt.plot(range(epochs), train_acc, marker='.', label='accuracy (train)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss / accuracy')
plt.show()
# Epoch 1/5 1875/1875 [==================] - 4s 2ms/step - loss: 0.297 - accuracy: 0.914
# Epoch 2/5 1875/1875 [==================] - 3s 2ms/step - loss: 0.143 - accuracy: 0.958
# Epoch 3/5 1875/1875 [==================] - 3s 2ms/step - loss: 0.106 - accuracy: 0.968
# Epoch 4/5 1875/1875 [==================] - 3s 2ms/step - loss: 0.088 - accuracy: 0.973
# Epoch 5/5 1875/1875 [==================] - 3s 2ms/step - loss: 0.073 - accuracy: 0.977
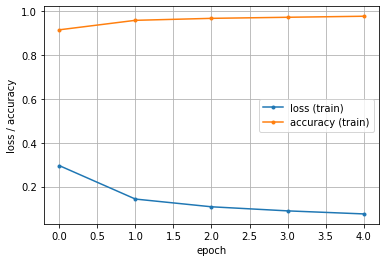
5回のエポックで、正解率97.7%になり、誤差も右下がりで7.7%になりました。かなり安定したモデルです。
mnist では、約1万組の評価用データ(x_test, y_test)があります。このデータを作成したモデルに投入して、結果を検討します、
model.evaluate(x_test, y_test, verbose=2)
probability_model = tf.keras.Sequential([
model,
tf.keras.layers.Softmax()
# 〓〓〓 最初の10件の組の結果表示
y_test[:10] # 正解
probability_model(x_test[:10]) # 確率表示
# loss: 0.0783 - accuracy: 0.9751 誤差率=7.9% 正解率=97.5%
#
# 確率が最大のもの(*) が推定した数字だといえる。全てy_testと一致している。
# 0 1 2 3 4 5 6 7 8 9 y_test
# 0 0.085 0.085 0.085 0.085 0.085 0.085 0.085 *0.231 0.085 0.085 7
# 1 0.085 0.085 *0.231 0.085 0.085 0.085 0.085 0.085 0.085 0.085 2
# 2 0.085 *0.231 0.085 0.085 0.085 0.085 0.085 0.085 0.085 0.085 1
# 3 *0.231 0.085 0.085 0.085 0.085 0.085 0.085 0.085 0.085 0.085 0
# 4 0.085 0.085 0.085 0.085 *0.231 0.085 0.085 0.085 0.085 0.085 4
# 5 0.085 *0.231 0.085 0.085 0.085 0.085 0.085 0.085 0.085 0.085 1
# 6 0.085 0.085 0.085 0.085 *0.231 0.085 0.085 0.085 0.085 0.085 4
# 7 0.085 0.085 0.085 0.085 0.088 0.085 0.085 0.085 0.085 *0.225 9
# 8 0.088 0.088 0.088 0.088 0.088 *0.172 0.121 0.088 0.088 0.088 5
# 9 0.085 0.085 0.085 0.085 0.085 0.085 0.085 0.085 0.085 *0.230 9
既に(6)までが完成しているとします。サンプルデータでの(6)まで(「# 〓〓〓」以下の部分は不要)が提供されているとします。
それを実行した後に、下記の部分を追加すれば、認識した数字が示されます。
# 〓〓〓 自作画像の指定
# mnist の x_test に合わせて3次元配列で与えます。本来は濃淡を0~256で与えるのですが、ここでは正規化を行った後だとして0/1で与えました。
import numpy as np
自作画像 = np.array([[
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,1,1,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,0,0],
[0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0],
[0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0],
[0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
]], dtype=float)
# 〓〓〓 入力データの確認
print(自作画像.shape) # 多次元配列の形状: (1, 28, 28)
import matplotlib.pyplot as plt # 画像表示
plt.imshow(
自作画像[0], # 1つの訓練用入力データ(28行×28列)
cmap=plt.cm.binary) # 白黒(2値:バイナリ)の配色
plt.xlabel('jisaku-hairetu') # X軸のラベルに分類名を表示
plt.show()
# 多次元配列の形状(1, 28, 28)

# 〓〓〓 推論(認識結果) predictions = model.predict(自作画像) print(predictions) # 数値が最大のインデックス番号を取得(=分類を決定する) pred_class = np.argmax(predictions, axis=-1) print(pred_class)
# 0 1 2(最大) 3 4 5 6 7 8 9
# [[1.44e-11 4.24e-08 9.99e-01 1.30e-08 5.51e-23 9.66e-08 3.71e-11 2.95e-16 2.49e-11 3.90e-17]]
# [2] 2だと認識しました。
実際には画像を配列ではなく、画像そのもので与えるのが当然でしょう。そのため、別途に画像→配列のプログラムを用意することになります。
次のプログラムを参考にしてください。実行