スタートページ>
JavaScript>
他言語>
Python 目次
scikit learn(sklearn)の紹介
scikit learn(sklearn)
Python は、機械学習など高度な統計処理に広く用いられている言語ですが、scikit learn は代表的なオープンソースの機械学習ライブラリです。scikit learn はライブラリの名称で、PCなどにインストールするときの名称です。Python のコーディングで用いるときは、略称としての sklearn が用いられ、
from sklearn import xxxx
のように記述します。xxxx は、ライブラリにあるモジュールです。
scikit-learn の機械学習のアルゴリズム体系の紹介(0.24.2)
Choosing the right estimator(https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
 拡大表示
拡大表示
次のサイトでは、この紹介およびアルゴリズムの概要、実例などを日本語で説明しています。
Quita「【機械学習初心者向け】scikit-learn「アルゴリズム・チートシート」の全手法を実装・解説してみた」
(
https://qiita.com/sugulu_Ogawa_ISID/items/e3fc39f2e552f2355209)
私には到底理解できません。ここでは「scikit learn には多様な機械学習のツールがある」ことを紹介するだけです。それにより、「Python には科のようなライブラリが存在する」ので、「私たちにも機械学習のモデルを作成することができる」こと、しかし、それには「多様なライブラリの存在を知り、その機能をりかいすることが重要」なことを示したいと思います。
scikit-learn による機械学習の区分
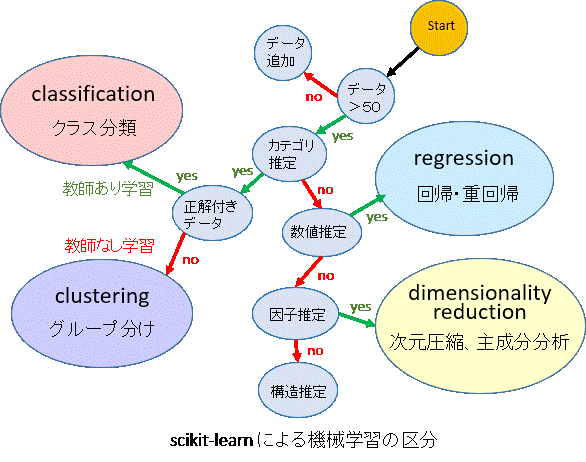
機械学習を目的や入力データで分類すると、次のようになります。
・classification(クラス分類、判別)
・clustering(クラスタリング、グループ分け、パターン認識)
・regression(回帰、相関)
・dimensionality reduction(次元圧縮、主成分分析)
上図とはやや異なりますが、教師あり/なしの区分から区分することもあります。
・教師あり学習 classification, regression
・教師なし学習 clustering, dimensionality reduction
classification(クラス分類)
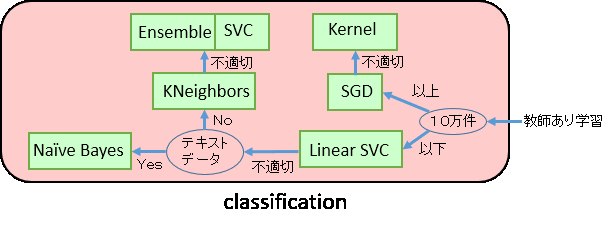
- SGD(stochastic gradient descent)確率的勾配降下法
(from sklearn import linear_model, metrics, preprocessing, cross_validation)
SD(gradient descent,最急降下法、最急勾配法)は、関数の勾配が最も急な方向に降下することにより関数の最小値を探索するアルゴリズムで、SGD はそれを拡大したものです。
基本的なクラス分類アルゴリズムで、直線で分割できる場合に適用できます。シンプルなアルゴリズムなので Linear SVC よりも高速であり、データ量が大きいときに適用されます。
直線で分割できるかどうかは実行した結果の図を見て判断することになります。すなわち、まずSGDでやってみて、それで満足すれば打切り、不満足(不適切)なら他の方法を試みることになります。
- kernel-approximation(カーネル近似)
(from sklearn import linear_model, metrics, preprocessing, cross_validation)
カーネル法とは生データに曲線(非線形)を当てはめて、それを新しいデータとみなして線形な手法を適用する方法です。
SGDの結果、直線では分離できないが曲線ならばかなり改善できそうだというときに適用できます。
多くの場合、XY軸で4象限に分割したとき対角線方向に集まるのですが、それを XOR のデータが多いといいます。そのような場合に非線形になります。
- Kernel SVC
(from sklearn import neighbors, metrics, preprocessing, cross_validation
from sklearn.kernel_approximation import RBFSampler)
SVM(Support Vector Machine)とは、分類・回帰に用いる教師あり学習アルゴリズムです。非線形の識別能力が高く、精度が良い分析結果が得られるといわれています。SVCはSVMアルゴリズムを分類に適用したものです。
- Linear SVC
(from sklearn import svm, metrics, preprocessing, cross_validation)
SVMに線形であるとの制約を付けることにより、簡素で精度のよい結果が得られるようにしたものです。一般にデータ量が少ないと精度が低くなりますが、Linear SVC は SGD に比べてよい結果が得られます。
- KNeighbors Classifier(K近傍法)
(from sklearn import neighbors, metrics, preprocessing, cross_validation
from sklearn.kernel_approximation import RBFSampler)
識別平面の式を生成しないタイプ(ノンパラパラメトリックモデル)のクラス分類手法です。カーネル近似と同じくXORの分類データに向いています。
- Ensemble Classification(ランダムフォレスト)
(from sklearn import ensemble, metrics, preprocessing, cross_validation)
決定木を複数用意して多数決で識別する、クラス分類手法です。
各決定木を作成する計算は並列化できるので、高速な計算が可能ですし、出力結果の説明が比較的しやすいなどの長所があります。
- Naive Bayes
(from sklearn import naive_bayes, metrics, preprocessing, cross_validation)
多数のテキストデータからキーワードの発生頻度を分析してデータがどの分類に属するかを求めるものです。迷惑メールの識別などで有名になりました。
本シリーズでの例:ナイーブベイズ分類器
regression
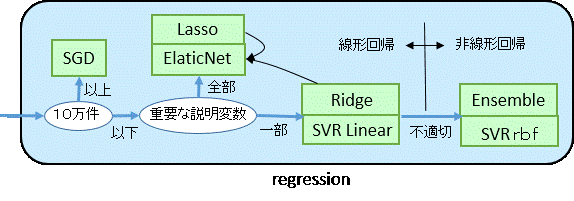
- (線形回帰 y=a + ax1 + ax2 + … + axn)
- SGD回帰(stochastic gradient descent Regressor)
(from sklearn import cross_validation, preprocessing, linear_model)
classification での SGD を回帰分析でも用います。
もっとも基本的なアルゴリズムです。高速で、データ量が大きいときは、これを用いることになります。
本シリーズでの例:回帰直線・信頼区間
- (説明変数の扱い)
全部:すべての説明変数が目的変数に影響する度合いを調べる
一部:少数の主要説明変数で目的関数の値を近似する
- Lasso 回帰
(from sklearn import cross_validation, preprocessing, linear_model)
回帰直線とデータの誤差に加えて、「係数w, bの絶対値」の絶対値を誤差に加えるというペナルティ手法で、多くの説明変数の係数を0にします。説明変数のどの特徴が重要なのかを考察することができます。
- Ridge 回帰
(from sklearn import cross_validation, preprocessing, linear_model)
回帰直線とデータの誤差に加えて、「係数w, bの2乗和」を誤差に加えるというペナルティ手法で、Lasso 回帰とは逆に全ての説明係数の係数を0にならならないようにします。つまりどの特徴も重要視しようとします。
- ElaticNet 回帰
(from sklearn import cross_validation, preprocessing, linear_model)
LassoとRidgeの組み合わせになります。
- SVR(Support Vector Regression)Linear 回帰
(from sklearn import cross_validation, preprocessing, linear_model, svm)
classification での SVC は SVM アルゴリズムを用いていますが、SVR はそれを回帰分析に用いたものです。
SVC と同様に線形と非線形があります。
- (非線形回帰)
- SVR rbf 回帰
(from sklearn import cross_validation, preprocessing, linear_model, svm)
SVR の非線形版です。rbf(Radial basis function)カーネルという方法を用いています。
- Ensemble 回帰
(from sklearn import cross_validation, preprocessing, ensemble, tree)
ランダムフォレストと同様にEnsemble(アンサンブル)を用いた回帰です。
clustering
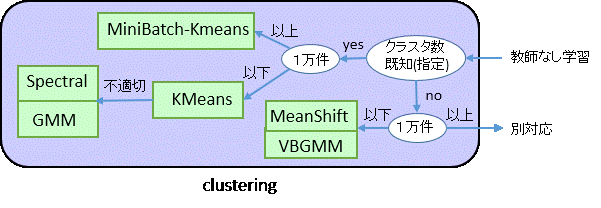
- KMeans
(from sklearn import cluster, preprocessing)
非階層型クラスタリングの基本的なアルゴリズムです。
Kはクラスタの数を示すパラメータ、Meanは平均です。
ランダムな位置にクラスタの重心(中心点)を定め、それぞれのクラスタの重心と各点の距離を計算、各点を一番近いクラスタに割り当てる手段を繰り返します。
実行速度が速く拡張性があるという特徴がありますが、初期値によって局所最適解に陥ることがあります。
本シリーズでの例:クラスター分析
- MiniBatch-Kmeans
(from sklearn import cluster, preprocessing)
Kmeans は高速だといってもデータ量が大きいと時間がかかります。
MiniBatchKMeansは、全データでなくbatch_size分のデータごとに更新する手法で、小規模モデルの繰り返しに変更することにより高速したものです。
- Spectral Clustering
(from sklearn import cluster, preprocessing, mixture)
データをサンプル間の類似度に基づいてグラフ表現し,そのスペクトル(固有値)分解したものをクラスタリングする手法です。
- MeanShift
(from sklearn import cluster, preprocessing, mixture)
半径 h の円を考え、初期点からその円内にある点の平均を求めて、そこに円の中心を移動する操作を繰り返して、極大点を見つけます。その計算にはKMeansを用いますが、クラスター数を仮定せずに行ないます。
- GMM(Gaussian mixture models)混合ガウス分布
(from sklearn import cluster, preprocessing, mixture)
EM(expectation–maximization)アルゴリズムは,潜在変数が存在する時の尤度関数を最大化するアルゴリズムです。
GMM は、EMアルゴリズムに従い、分布の平均値と分散の値を最尤推定して、それを基にしてクラスタリングします。
- VBGMM(Variational Bayesian Gaussian Mixture)変分混合ガウス分布
(from sklearn import cluster, preprocessing, mixture)
ベイズ推定に基づき確率分布を計算しながらクラスター数や分布の形状を求めます。
dimensionality reduction
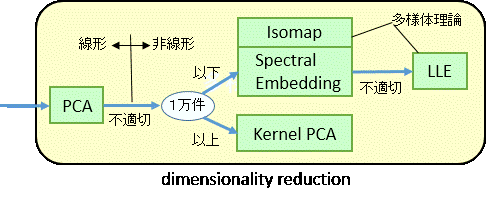
主成分分析、因子分析などの分野です。
- PCA(Princial Component Analysis)主成分分析
(from sklearn import cross_validation, preprocessing, decomposition)
次元圧縮で最も基本的な主成分分析アルゴリズムです。固有値展開を使って、分散が大きな方向の軸(主成分)を数軸(通常は2軸)を求めます。
本シリーズでの例:主成分分析
PCA は処理効率がよいので、大きなデータにも利用できます。しかし線形モデルですので、無理(うまく説明できない)があります。そのときは以降の非線形モデルを試みます。
- Kernel PCA
(from sklearn import cross_validation, preprocessing, decomposition)
Kernel は classification でのカーネル法と同じです。生データに曲線(非線形)を当てはめて、それを新しいデータとみなして主成分分析を行います。
- SpectralEmbedding
(from sklearn import cross_validation, preprocessing, decomposition, manifold)
clustering での Spectralと同じアルゴリズムを用い、Kernel PCA よりも適切な軸が得られるといわれています。
- Isomap
(from sklearn import cross_validation, preprocessing, decomposition, manifold)
多様体とは、データ点どうしの繋がりから形成されるデータの形です。多様体上の距離を測定し、多次元尺度構成法で表現した次元圧縮手法で、測地線距離行列が似ているものは近くに、似ていないものは遠くに配置する方法です。
Isomap は大域的なアプローチで、データ全体を多様体と捉えます。
- LLE(Locally Linear Embedding)
(from sklearn import cross_validation, preprocessing, decomposition, manifold)
小域的なアプローチでづ。多様体上で近くのデータ同士は線形な関係で表されるということに着眼して、それぞれの多様体の次元を圧縮します。かなり複雑になるので、Isomap でも不適切なときに用いられます。