μ、σを省略すると、μ=0、σ=1の標準正規分布になります。
確率密度
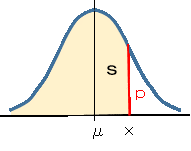
平均μ、分散σ2の正規分布において、値xの確率密度関数の値pは次式で計算できます。
p = 1/√(2πσ2) * e(-(x-μ)2/2σ2)
累積確率
-∞~xの累積確率の値sを戻します。
確率密度 を数値積分 sFx() で計算するより、近似式が知られています。
ここではHastingsの式を使いました。(引用先:http://qiita.com/gigamori/items/e17e6f9faffb78822c56 by Yanai Takamichi)
累積確率の逆関数
累積確率 s を与えたときの x を戻します。
次の近似式を参考にさせていただきました
「https://potatodigger.wordpress.com/2013/06/30/正規分布の確率密度関数pdf、累積分布関数cdf、逆累/ by potatodigger」
n :必要な標本数 n1:有意水準5%, n1:有意水準1%
p :母集団での想定発生確率
pe:許容確率誤差 = 標本での発生確率と母集団での想定発生確率の差 pe1:有意水準5%, n1:有意水準1%
pt:有意水準(= 0.05, 0.01)(Z;正規分布の変位。 両側有意水準 pt = 0.05 のとき Z = 1.96、 pt = 0.01 のとき Z = 2.58)
中心極限定理:母集団の分布に関係なく、標本数 n が非常に大きくなると,標本平均の分布は平均μ,分散 σ2/n の正規分布に近づく。
標本の大きさ n が大であれば標本比率 p0 は近似的に正規分布 (p, p(1-p)/n) に従う。
必要な標本数 n = (Z/pe)2 * p(1-p)
nを与えたときの確率誤差 pe = Z*√(p(1-p)/n)
(Z;正規分布の変位。 両側有意水準 pt = 0.05 のとき Z = 1.96、 pt = 0.01 のとき Z = 2.58)
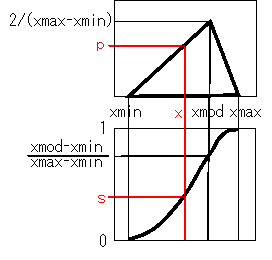
右図のように、3点 a(xmin,0), b(xmax,0), c(xmod, h) を結ぶ三角形となる分布。
平均:(a+b+c)/3、 分散:(a2+b2+c2-ab-bc-ca)/18
参照:「三角分布」
上の xmin, xmax, xmod を与えたとき、x=xmin~xmax における p と s のリストを表示します。
平均:np 分散:np(1-p)
発生確率がpの事象が、n回の試行でx回発生する確率
確率密度: x回発生する確率 P(x) = nCx・px(1-p)n-x
累積密度: 0~x回発生する確率 S(≦x) = ΣP(x)
nCx = n!/x!(n-x)! = nCx(n, x) 二項係数(n個からx個を取り出す場合の数(場合の数))
参照:「離散型統計分布」
二項分布の計算は計算量が大きく、大きい数と小さい数の計算が必要になるので誤差が生じます。計算を容易にするために、
・np > 5 かつ n(1-p) > 5 ならば、平均μ=np、標準偏差σ=√np(1-p) の正規分布で近似できる。
確率密度:区間 x-0.5~x+0.5 の正規分布累積確率 distNormalCumMinmax(x-0.5, x+0.5, μ, σ)
累積密度:≦x+0.5 の累積確率 distNormalCum(x+0.5, μ, σ)
・n>50, np≦5 ならば、平均λ=np のポアソン分布で近似できる。
などの方法がありますが、ここでは用いていません。
上の n,p を与えたとき、x=0~n における Px と s のリストを表示します。
平均:x(1-p)/p 分散:x(1-p)/p2
ある事象が起こる確率がpのとき、n回試行したときに、その事象がはじめてx回になる確率P(n)の確率分布。
P(n) = n-1Cx-1・px(1-p)n-x
参照:「離散型統計分布」
x=1 のときは、幾何分布 distGeoDen と一致します。
上の n,p を与えたとき、x=1~n における Pn と s のリストを表示します。
平均:(1-p)/p 分散:2*平均2
発生確率pの事象がはじめて発生したときの試行回数nの確率分布(負の二項分布で、x=1とおくと、幾何分布に一致)
確率密度: Pn = (1-p)n-1*p
累積確率: s = 1-(1-p)n
逆関数: n = log(1-s) / log(1-p)
参照:「離散型統計分布」
平均・分散
a+b 個から α個取り出すとき、白玉(a) がαである確率 P(α) の平均・分散
平均 = x*a/n; 分散 = (a*(a-1) * x*(x-1)) / (n*(n-1));
確率密度
袋の中にAがa個、Bがb個入っている。α+β個を取り出したとき、Aがα個、Bがβ個である確率
p = aCα・bCβ/a+bCα+β
で計算できる(参照:「離散型統計分布」)。
確率密度:αが0~α個である確率。
「α以上である確率」は distHyperGeoCum(a, b, α-1, β+1) になる。
超幾何分布では、CやDなど多数の系列も対象にするが、複雑になるので、ここでは2系列に限定する。
平均 = 1/λ; 分散 = 1/λ2;
| 関数一般形式 | 機能 | 計算式 |
| distExpDen(t, λ) | t=t における確率密度 | p = λ*e(-λ*t) |
| distExpCum(t, λ) | 区間 t=0~t の累積確率 | s = 1-e(-λ*t) |
| distExpInv(p, λ) | 累積確率が p となる t の値 | t = -(1/λ)log(1-p) |
上の λ を与えたとき、t を変化させたときの p と s のリストを表示します。
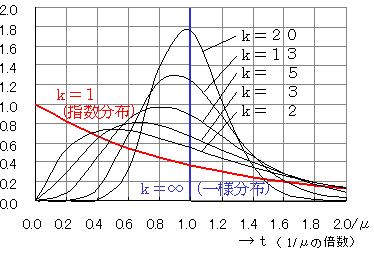
平均 = k/λ; 分散 = k/λ2;
アーラン分布は、指数分布と一様分布の中間的な分布。
k=1なら指数分布、k=大なら正規分布、k=∞なら一様分布
p = (λ*t)k-1/(k-1)! * λe(-λ*t)
s = 区間 t=0~t の累積確率
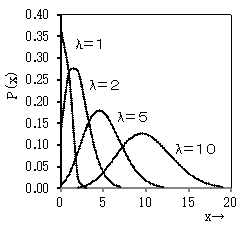
平均 = λ; 分散 = λ2;
一定(微小)時間内にある事象が発生する回数が平均λであるとき、発生回数がxとなる確率pは、
p(x) = (λx/x!)*e-λ ← distPoissonDen(x,λ)
のポアソン分布に従う。
(参照:「ポアソン分布と指数分布」、「離散型統計分布」
累積確率は、単純に s(x) = s(x-1) + p(x) で求めた。
逆関数は、x=0, 1, 2, ... として累積確率 s(x) を計算し、s(x) ≦ p である最大のxを戻している。
すなわち「確率pでx回以下だといえる」こととした。
作表1:λを固定し、xを0, 1, 2, ... と変化させたときの p と s を求める
作表2:λを固定し、pを変化させたときの x を求める
c は正のスカラーです。
x, y, d は、右辺をスカラーに与えればスカラー、ベクトルならベクトルを戻します。
シグモイド関数とは、時刻 x における普及率 y の関係は、微分方程式
dy/dx = c * y * (1-y) cは定数
で表される関数であり。その解は
y = 1/(1+e-cx)
になります。
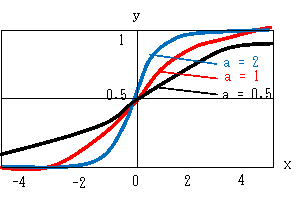
シグモイド関数は右図のようになります。次の特徴があります。
・原点(0,0.5) に対して対称
・x→-∞のとき y→0. x→∞のとき y→1. いつかは全体に普及する。
・定数 c が大になると傾きが大になる。 短時間で y≒1 に達する
参照:「シグモイド関数」
定数 c が与えられたとき、時刻 x における微分係数 d を、次式により求めます。
d = c*y*(1-y) = c*(1-1/(1+e-cx))*(1/(1+e-cx))
入力
var x = 1; // スカラー
var c = 0.5;
var d = distSigmoidDen(x, c);
出力
d = 0.118
定数 c が与えられたとき、時刻 x におけるシグモイド関数の値を求めます。
y = 1/(1+e-cx)
入力
var x = [-1, 0. 1]; // ベクトル
var c = 0.5;
var y = distSigmoidCum(x, c);
出力
y[0] = 0.378, y[1] = 0.5 y[2] = 0.622 // ベクトル
定数 c が与えられたとき、シグモイド関数の値 y に相当する x の値を、
distSigmoidCum の逆関数
x = (1/c)log(y/(1-y))
で求めます。
入力
var y = 0.9; // スカラー
var c = 0.5;
var x = distSigmoidInv(y, c);
出力
x = 4.394
k, b, c は正のスカラーです。
x, y, d は、右辺をスカラーに与えればスカラー、ベクトルならベクトルを戻します。
ロジスティック関数は、シグモイド関数を汎用化した関数です。
時刻 x における普及率 y の関係は、微分方程式
dy/dx = (c/k)*y*(k-y) c,kは定数
で表される関数です。k=1 とするとシグモイド関数の微分方程式と一致します。
その解は
y = k/(1+b*e-cx)
になります。
シグモイド関数での y の存在範囲は 0~1 ですが、ロジスティック関数では 0~k になります。
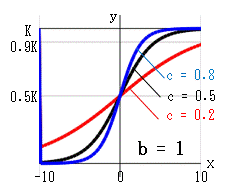
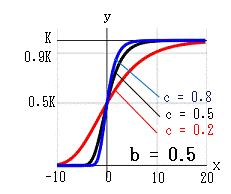
c の影響(右上図)
K=1,b=1 とすると、シグモイド関数と一致します。
c は傾き、c が大だと早く上限に達します。
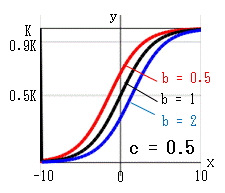
bの影響(右下図)
x=0 のときの状態を変化させます。
b=0 では y=k、b=∞ では y=0 になります。
参照:「ロジスティック曲線」
定数 k,b,c が与えられたとき、時刻 x における微分係数 d を、次式により求めます。
d = (c/k)*y*(k-y)
入力
var x = [-1, 0, 1]; // ベクトル]
var k = 2;
var b = 0.5: // y を計算するために必要
var c = 0.5;
var d = distLogisticDen(x, k, b, c);
出力
d[0] = 0.248, d[1] = 0.222, d[1] = 0.179
定数 k,b,c が与えられたとき、時刻 x におけるロジスティック関数 y を、次式により求めます。
y = k/(1+b*e-cx)
入力
var x = [-2, 0, 2, 5, 10];
var k = 2;
var b = 0.5;
var c = 0.5;
var y = distLogisticCum(x, k, b, c);
出力
y[0] = 0.848, y[1] = 1.333, y[2] = 1.689, y[3] = 1.921, y[4] = 1.993
定数 k,b,c が与えられたとき、ロジスティック関数 y となる時刻 x を次式により求めます。
x = -(1/c)log((k-y)/(b*y))
実務対応
ロジスティック関数では、折返点が x=0 になっています。しかし実務では最初に観測した点を t=0 とするのが通常であり、そのときの y0 の値は既知のはずです。
x0 = -(1/c)log((k-y0)/(b*y0))
を計算して、t = x + x0 とすることで解決します。
入力
var y = [0.5, 1, 1.9, 1.99];
var k = 2;
var b = 0.5;
var c = 0.5;
var x = distLogisticInv(y, k, b, c);
出力
x[0] = -3.583, x[1] = -1.386, x[2] = 4.503, x[3] = 9.200,
ゴンペルツ曲線は、成長の変化 dy/dx を
・現在の個数に比例して増大する
・時間が経過するのに伴い指数的に減少する
の積として捉えます。
dy/dx = A*y*e-cx A。cは定数
これを -∞ ~ x まで累積した曲線がゴンペルツ曲線です。(A = -c*log(b)と変形)
y = Kbe-cx k.b,c は定数
ゴンペルツ曲線は、次の特徴があります。
x→∞ のとき:e-cx→0、b0=1、y→K
x→-∞のとき:e-cx→∞、y→b∞→0
x=0 のとき:e-cx=1、y=Kb
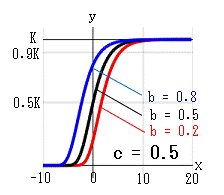
b, c を変化させたときの曲線の変化を示します。
b:x=0 のときの y を y0 とすれば、y0 = Kb になります。
c:曲線の傾きを示します。 c→大 になると傾きが大になります。
x = 0 は曲線の変曲点でもあります。
b→小、c→小 になると、K値に近ずくまでの時間 x が長くなります。
参照:「ゴンペルツ曲線」
時刻 x におけるゴンペルツ曲線の微分係数(個体数の増減)を求めます。
dy/dx = d = -c*log(b)*y*e-cx
入力
var x = [-2, 0, 2, 10]; // ベクトル]
var k = 2;
var b = 0.5;
var c = 0.5;
var d = distGompertzDen(x, k, b, c);
出力
d[0] = 0.286, d[1] = 0.347,,d[2] = 0.198, d[3]=0.005
時刻 x におけるゴンペルツツ関数 y の値
y = Kbe-cx
入力
var x = [-2, 0, 2, 5, 10];
var k = 2;
var b = 0.5;
var c = 0.5;
var y = distGompertzCum(x, k, b, c);
出力
y[0] = 0.3034 y[1] = 1.000, y[2] = 1.550. y[4] = 1.889, y[4] = 1.991/p>
ゴンペルツツ関数の値が y となる時刻 x
x = -(1/c)log(log(k/y)/|log(b)|)
実務対応
ゴンペルツツ関数では、折返点が x=0 になっています。しかし実務では最初に観測した点を t=0 とするのが通常であり、そのときの y0 の値は既知のはずです。
x0 = -(1/c)log(log(k/y0)/|log(b)|)
を計算して、t = x + x0 とすることで解決します。
入力
var y = [0.5, 1, 1.9, 1.99];
var k = 2;
var b = 0.5;
var c = 0.5;
var x = distGompertzInv(y, k, b, c);
出力
x[0] = -1.386, x[1] = 0, x[2] = 5.207, x[3] = 9.858
p は 0~1 で、スカラーでもベクトルでも構いません。それに応じて、
x, y, d は、右辺をスカラーに与えればスカラー、ベクトルならベクトルを戻します。
シグモイド関数 y = 1/(1+e-cx で c=1 とした y = 1/(1+e-x) を標準シグモイド関数といいます。その逆関数は x = log(y/(1-y)) になります。
ここで、y は、時刻 x における発生確率だといえmす。それで x→t、y→p と書き直すと、
t = log(p/(1-p)) = ロジット
になります。
参照:「ロジスティック回帰分析の前提概念」
var Odss = distOdss(0.6); // スカラー
// Odss = 1.5
var Logit = distLogit([0.6, 0.8]); // ベクトル
// Logit[0] = 0.405, Logiit[1] = 1.386
下表の n00, n01, n10, n11 を与えて、OdssRatio を計算します。
事象あり 事象なし 合計 p オッズ
群A n00 n01 s0=n00+n01 p0=n00/s0 Odss0=p0/(1-p0)
群B n10 n11 s1=n10+n11 p1=n10/s1 Odss1=p1/(1-p1)
オッズ比 OddsRatio = Odss0/Odds1
var OdssRatio = distOdssRatio(n00, n01, n10, n11);
具体例
喫煙と肺がんの関係で、次のデータがあるとします。
喫煙者 非喫煙者 合計 肺がん確率
肺がんの人 40 10 50 p0 = 40/50 = 0.8
健康な人 20 80 100 p1 = 20/100 = 0.2
オッズ比 = (p0/(1-p0)) / (p1/(1-p1)) = (0.8/0.2)/(0.2/0.8) = 16
→健康な人と比べて、肺がんの人では喫煙者が肺がんである可能性が非喫煙者の16倍になる。