侾丂僨乕僞僂僃傾僴僂僗偺奣梫
侾丏侾丂僨乕僞僂僃傾僴僂僗偺掕媊
丂僨乕僞僂僃傾僴僂僗偲偼丄暥帤捠傝偵偼僨乕僞偺憅屔偺偙偲偱偁傞偑丄W.H.Inmon(1992)偼丄僨乕僞僂僃傾僴僂僗傪乽僒僽僕僃僋僩巜岦乮subject-oriented乯丄摑崌壔乮integrated乯丄峆忢揑乮non-volatile乯丄帪宯楍乮time-variant乯偺摿惈傪帩偮儅僱僕儊儞僩偺堄巚寛掕傪巟墖偡傞僨乕僞偺廤崌偱偁傞乿偲掕媊偟偨1)丅
丂婇嬈傪庢傝姫偔娐嫬偼寖曄偟偰偄傞丅偦傟偵懳墳偡傞偵偼丄忣曬偺棙妶梡偵傛傝揔愗側堄巚寛掕傪偡傞偙偲偑昁梫偱偁傞丅偦偺偨傔偵丄斕攧僔僗僥儉傗宱棟僔僗僥儉側偳偺偄傢備傞婎姴嬈柋宯僔僗僥儉偱廂廤拁愊偟偨僨乕僞傪丄棙梡幰偑巊偄傗偡偄傛偆偵惍棟偟偰丄擟堄偵専嶕壛岺偱偒傞傛偆偵偡傞棙梡宍懺偑廳帇偝傟偰偒偨丅偙偺棙梡宍懺傪忣曬専嶕宯僔僗僥儉偲偄偆偑丄侾俋俈侽擭戙偺俢俽俽乮Decision Support System乯傗侾俋俉侽擭戙偺俤倀俠乮End-User Computing乯偺晛媦傪捠偟偰妋棫偟偰偒偨丅
丂偡側傢偪丄僨乕僞僂僃傾僴僂僗偺奣擮偼栚怴偟偄傕偺偱偼側偔丄埲慜偐傜懚嵼偟偰偄偨偺偱偁傞丅偟偐偟丄摉帪偺僐儞僺儏乕僞娐嫬偱偼丄戝検偺僨乕僞傪曐娗偟偰抁帪娫偱専嶕壛岺偡傞偵偼尷奅偑偁偭偨丅偦傟偑侾俋俋侽擭戙偺弶摢偵偍偗傞僟僂儞僒僀僕儞僌偺晛媦丄暲楍張棟媄弍偺恑曕丄僨傿僗僋偺戝梕検壔丄僨乕僞儀乕僗媄弍偺敪揥側偳偵傛傝丄偦偺暻偑戝偒偔庢傝奜偝傟傞傛偆偵側傝丄夵傔偰廳帇偝傟傞傛偆偵側偭偨偺偱偁傞丅
侾丏俀丂僨乕僞僂僃傾僴僂僗偺岠壥
丂僨乕僞僂僃傾僴僂僗偼丄忣曬専嶕宯僔僗僥儉偺敪揥宍懺偱偁傞偲偲傕偵丄嵟嬤偺忣曬棙梡摦岦偺婎杮偲傕側傞傕偺偱偁傞丅
丂僔僗僥儉奐敪偱偼丄俤俼俹乮Enterprise Resourse Planning乯僷僢働乕僕偵傛傞奐敪偑拲栚偝傟偰偄傞偑丄堦斒偵俤俼俹僷僢働乕僕偱偼丄帪宯楍揑側僨乕僞傪懡條偵壛岺偡傞婡擻傪廫暘偵偼帩偭偰偄側偄丅偦傟傪慻傒崬傕偆偲偡傞偲丄偄傢備傞僇僗僞儅僀僘傗傾僪僆儞偑懡偔側傝丄旓梡傕帪娫傕偐偐傝彨棃偺夵掶傕斚嶨偵側傞側偳丄俤俼俹僷僢働乕僕偺棙揰傪嫕庴偡傞偙偲偑偱偒側偄丅偦傟傜偺婡擻傪僨乕僞僂僃傾僴僂僗偱庴偗帩偮偙偲偵傛傝丄俤俼俹僷僢働乕僕傊偺巇條傪娙慺壔偡傞偙偲偑偱偒傞丅
丂忣曬媄弍偵傛傞塩嬈妶摦傪巟墖偡傞俽俥俙乮Sales Force Automation乯偱偼丄屭媞忣曬偺惍旛偲偦傟偺懡妏揑側専嶕壛岺偑億僀儞僩偵側傞偑丄偦傟偼僨乕僞僂僃傾僴僂僗偺婡擻偦偺傕偺偱偁傞丅
丂僫儗僢僕丒儅僱僕儊儞僩偼丄尰嵼偱偼丄偦偺懳徾傪僐儈儏僯働乕僔儑儞暘栰偵媮傔偰偄傞偑丄婇嬈忣曬偱偼悢抣揑側忣曬偑廳梫偱偁傝丄偄偢傟偦偺暘栰傊傕攇媦偟傛偆丅偦偆側傞偲丄僨乕僞僂僃傾僴僂僗傕僫儗僢僕丒儅僱僕儊儞僩偺戝偒側梫慺偲側傞丅
丂偙偺傛偆側棟桼偵傛傝丄僨乕僞僂僃傾僴僂僗偼拝幚偵晛媦偟偰偒偨丅侾俋俋俉擭係寧偵偍偗傞乽擔宱僐儞僺儏乕僞乿帍偺傾儞働乕僩挷嵏2)偵傛傟偽丄崙撪偺忋応乛揦摢岞奐婇嬈偲偦傟偵弨偢傞婇嬈偺慡懱偱偼丄僨乕僞僂僃傾僴僂僗傪婛偵峔抸偟偰偄傞婇嬈偼侾俋.侾亾丄峔抸梊掕偑偁傞婇嬈偼俁係.俈亾偱偁傝丄廬嬈堳俆侽侽侽恖埲忋偺婇嬈偱偼丄偦傟偧傟俁俇.俈亾丄係係.俋亾偵側傞偲偄偆乮拲侾乯丅僨乕僞僂僃傾僴僂僗偼丄傕偼傗丄捠忢偺棙梡宍懺偵側偭偰偒偨偺偱偁傞丅
侾丏俁丂俷俴俙俹偲俵俢俢俛
丂E.F.Codd(1993)偼丄僨乕僞僂僃傾僴僂僗偺傛偆側暘愅傪拞怱偲偡傞棙梡宍懺傪俷俴俙俹乮Online Analytical Processing乯偲柦柤偟丄俷俴俙俹偱偺僨乕僞偺摿惈偲偟偰乽侾俀偺儖乕儖乿3)傪帵偟丄俵俢俢俛(Multi-dimensional Database丗懡師尦僨乕僞儀乕僗乯偑揔愗偱偁傞偲偟偨乮拲俀乯丅
丂俵俢俢俛偺峔憿偼師偺傛偆側傕偺偱偁傞丅搶嫗巟揦偺攧忋幚愌傪丄廲偵彜昳丄墶偵寧傪偲傟偽俀師尦偺昞偵側傞丅摨條偵戝嶃巟揦丄柤屆壆巟揦偺昞傪嶌傝丄偦傟傜偺昞傪廳偹傟偽俁師尦偵側傞乮恾侾乮侾乯乯丅偝傜偵攧忋丄尨壙丄棙塿偺傛偆側夛寁嬫暘傪壛偊傟偽係師尦偵側傞偲偄偆傛偆偵昞偺師尦偼憹戝偡傞丅俵俢俢俛偺婎杮憖嶌偵偼丄僷儞傪僗儔僀僗偡傞傛偆偵尰嵼偺抐柺偲暯峴偟偨抐柺傪昞帵偡傞僗儔僀僔儞僌乮俀乯丄僒僀僐儘傪揮偑偡傛偆偵懠偺抐柺傪昞帵偡傞僟僀僕儞僌乮俁乯乮係乯丄徻嵶偵揥奐偟偨傝廤栺偟偨傝偡傞僪儕儕儞僌乮俆乯偑偁傞丅巗斕偝傟偰偄傞俵俢俢俛偺僜僼僩僂僃傾偱偼丄偙傟傜偺憖嶌偼丄昞偺晹暘傪僋儕僢僋偟偨傝丄僾儖僟僂儞偟偨崁栚傪僋儕僢僋偡傞偲偄偆傛偆偵夋柺憖嶌偩偗偱峴偊傞傛偆偵側偭偰偄傞丅傑偨丄昞帵偝傟偰偄傞悢昞傪丄懡條側僌儔僼偵偡傞偙偲傕娙扨偵偱偒傞傛偆偵岺晇偝傟偰偄傞丅
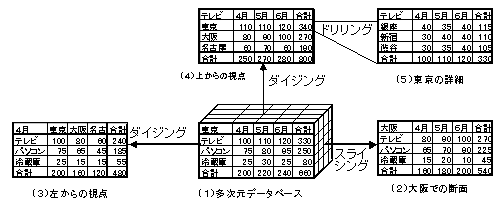
恾侾丂俵俢俢俛偺婎杮憖嶌
侾丏係丂倁俴俢俛偲僨乕僞儅僀僯儞僌
丂徚旓宱嵪偺惉弉壔偵敽偄丄屭媞僯乕僘偼懡條壔偟偰偄傞丅崙嵺壔偺敪揥傗徚旓偺掅柪偵傛傝嫞憟偼寖壔偟偰偄傞丅偙偺傛偆側娐嫬偵偍偄偰偼丄儅僗偲偟偰偺巗応偱偼側偔丄屄乆偺屭媞乮屄媞乯偺僯乕僘傪揑妋偵偲傜偊偨惢昳偺奐敪丄斕攧惌嶔丄揦曑娗棟側偳偑廳梫偵側傞丅偦傟偵偼丄屄媞偺峸攦僨乕僞傪僨乕僞儀乕僗偲偟偰娗棟偟偰暘愅偡傞偙偲偵傛傝丄桳梡側忣曬傪摼偰丄惌嶔偵妶偐偡偙偲偑廳梫偵側傞丅偙偺傛偆偵僨乕僞儀乕僗傪嬱巊偟偨儅乕働僥傿儞僌傪僨乕僞儀乕僗丒儅乕働僥傿儞僌偲偄偆丅
丂僨乕僞儀乕僗丒儅乕働僥傿儞僌傪桳岠偵峴偆偵偼丄屄乆偺斕攧偺僨傿僥乕儖僨乕僞傪挿婜偵傢偨傝帪宯楍偵帩偮昁梫偑偁傞丅偦偺偨傔偵丄偦偺僨乕僞検偼朿戝偵側傝丄悢廫俧俛乮僊僈僶僀僩亖侾侽壄僶僀僩乯偐傜悢俿俛乮僥儔僶僀僩亖侾挍僶僀僩乯偵傕側傞丅偙偺傛偆側嫄戝側僨乕僞儀乕僗傪倁俴俢俛乮Very Large Database乯偲偄偆丅
丂倁俴俢俛傪暘愅偟偰桳梡側忣曬傪摼傞偙偲傪丄扵峼偵側偧傜偊偰僨乕僞儅僀僯儞僌偲偄偆偑丄偙傟偵偼扨側傞暘椶張棟傗廤寁張棟偩偗偱偼側偔丄懡曄検夝愅側偳偺摑寁夝愅偑昁梫偱偁傝丄恖岺抦擻傗僯儏乕儘側偳偺媄弍傕墳梡偟偨暘愅僣乕儖偑奐敪偝傟偰偄傞丅
侾丏俆丂僨乕僞僂僃傾僴僂僗偲僨乕僞儅乕僩
丂僨乕僞僂僃傾僴僂僗偺愢柧偱偼丄倁俴俢俛傪僨乕僞儅僀僯儞僌偡傞偙偲偲丄俵俢俢俛偵傛傞俷俴俙俹傪崿摨偟偰愢柧偟偰偄傞偙偲偑懡偄丅偦偺偨傔偵丄悢僥儔僶僀僩偵偍傛傇倁俴俢俛傪俵俢俢俛偵偟偰僗儔僀僔儞僌傗僪儕儖僟僂儞偑娙扨偵偱偒傞偐偺傛偆側岆夝傪彽偔偙偲傕偁傞丅
丂偲偙傠偑丄尰幚偵棙梡晹栧偵愝抲偝傟傞僒乕僶偺梕検偼偣偄偤偄悢廫俧俛偱偁傝丄倁俴俢俛傪偙傟偵奿擺偡傞偙偲偼崲擄偱偁傞丅傑偨丄俵俢俢俛偑尰幚偵庢傝埖偊傞僨乕僞検偼悢俧俛掱搙偱偁傞乮拲俁乯丅
丂偦偺傛偆側帠忣偵傛傝丄僨乕僞僂僃傾僴僂僗偲僨乕僞儅乕僩偵嬫暘偡傞偙偲偑懡偄丅偙偺偲偒丄僨乕僞僂僃傾僴僂僗偲偼丄慡幮揑側僨乕僞偺曐娗屔偲偟偰丄挻暲楍僾儘僙僒傗戝婯柾側倀俶俬倃僒乕僶傪梡偄偰丄偦傟偵倁俴俢俛傪峔抸偡傞丅偦傟偵懳偟偰丄僨乕僞儅乕僩偱偼丄棙梡幰偑巊偄傗偡偄傛偆偵丄偦偺晹栧偑昁梫偲偡傞僨乕僞偩偗傪丄棙梡晹栧偵愝抲偝傟偨斾妑揑彫婯柾側僒乕僶偵丄俵俢俢俛偺傛偆側棙梡幰偵巊偄傗偡偄宍幃偱曐娗偡傞丅偡側傢偪丄斾歡揑偵偼僨乕僞僂僃傾僴僂僗偼拞墰壍攧巗応偺傛偆側傕偺偱偁傝丄僨乕僞儅乕僩偼嬤強偺僐儞價僯僄儞僗僗僩傾偺傛偆側傕偺偩偲偄偊傞丅
丂偙偺傛偆偵丄僨乕僞僂僃傾僴僂僗偲僨乕僞儅乕僩偲偼弒暿偡傋偒傕偺側偺偱偁傞偑丄偙傟傜傪傑偲傔偰僨乕僞僂僃傾僴僂僗偲偄偆応崌傕偁傞偟丄僨乕僞儅乕僩偺偙偲傪僨乕僞僂僃傾僴僂僗偲偄偆偙偲傕偁傝丄偦傟偑岆夝傪梌偊偰偄傞偙偲傕偁傞丅偨偲偊偽丄慜弎偟偨W.H.Inmon偺掕媊偼丄僨乕僞僂僃傾僴僂僗傛傝傕僨乕僞儅乕僩偲偟偰偺掕媊偲峫偊傞傎偆偑揔愗偱偁傞丅
俀丂僨乕僞僂僃傾僴僂僗塣塩偵偍偗傞棷堄揰
丂僨乕僞僂僃傾僴僂僗偺塣塩偵娭偟偰偼丄乽栚揑傪柧妋偵偡傞偙偲乿偲偐乽彫偝偔巒傔偰戝偒偔揥奐偡傞偙偲乿側偳偑巜揈偝傟偰偄傞丅偟偐偟丄昅幰偼俤倀俠傗忣曬専嶕宯僔僗僥儉偺晛媦偵廬帠偟偰偒偨宱尡偐傜丄偦傟偵傕傑偟偰廳梫偱偁傞偲擣幆偟偰偄傞棷堄揰偵偮偄偰巜揈偡傞丅
俀丏侾丂晹栧僙僋僔儑僫儕僘儉偵傛傞慾奞
丂揹巕儊乕儖傗揹巕宖帵斅側偳偺僐儈儏僯働乕僔儑儞宯僔僗僥儉偱偺塣梡偱偼丄僙僋僔儑僫儕僘儉偺嫮偄僋儘乕僘側慻怐暥壔偱偼墌妸側敪揥偑慾奞偝傟傞偙偲偼傛偔巜揈偝傟偰偄傞丅僨乕僞僂僃傾僴僂僗偵偍偄偰偼丄偦偺僨乕僞偼婎姴嬈柋宯僔僗僥儉偱廂廤偝傟偨傕偺偱偁傞偐傜丄僨乕僞偺採嫙偱偼偙偺傛偆側栤戣偼側偄偑丄僨乕僞偺岞奐偵偁偨偭偰偼丄棙梡晹栧偺斀懳偵傛傞慾奞偑敪惗偡傞偙偲偑偁傞4)丅
丂偨偲偊偽丄偁傞晹栧偑抣壓偘斕攧傪偟偨偺傪懠晹栧偵抦傜偣偨偔側偄側偳偺棟桼偵傛傝丄乽悢検偼岞奐偟偰傕傛偄偑扨壙偼岞奐偡傞側乿偲偐乽廤栺偟偨僨乕僞偼岞奐偟偰傕傛偄偑僨傿僥乕儖僨乕僞偼岞奐偡傞側乿側偳偺埑椡偑偐偐傞偙偲偑偁傞丅偙傟偵傛傝丄岞奐偡傞僨乕僞儀乕僗偺峔憿偼暋嶨偵側傝丄暋嶨側傾僋僙僗惂尷傪愝偗傞偙偲偵側傝丄巊偄偵偔偄僔僗僥儉偵側偭偰偟傑偆丅
俀丏俀丂棙梡幰庯枴偵傛傞暰奞
丂僨乕僞僂僃傾僴僂僗偼棙梡幰偑巊偆偙偲偵傛傝岠壥偑摼傜傟傞偺偱偁傞偐傜丄棙梡幰偺梫媮偵崌傢偣偨憖嶌曽朄傗弌椡懱嵸偵偡傞偺偼朷傑偟偄偙偲偱偁傞丅偟偐偟丄傗傗傕偡傞偲丄棙梡幰偺夁搙側梫媮偺偨傔偵丄偦偺峔抸傗堐帩偵懡戝側楯椡偑偐偐傝丄偐偊偭偰敪揥傪慾奞偡傞婋尟傕偁傞丅
丂堦斒偵丄帺桼搙傪崅偔偟偰懡條側忣曬偑摼傜傟傞傛偆偵偡傞偙偲偲丄憖嶌傪娙曋偵偡傞偙偲偲偼僩儗乕僪僆僼偺娭學偑偁傞丅棙梡幰偼丄乽侾傪僋儕僢僋偡傟偽仜仜廤寁昞丄俀傪僋儕僢僋偡傟偽亊亊暘愅昞乿偲偄偆傛偆側屄暿張棟儊僯儏乕採嫙曽幃傪梫媮偡傞丅偙偺傛偆側曽幃偼曋棙偱偁傞偑丄棙梡幰偑懡偔梫媮偡傞挔昜傕懡條偵側傞偲丄偦偺傛偆側娐嫬傪惍旛偡傞偙偲偑帠幚忋晄壜擻偵側傞丅偟偐傕丄偄偭偨傫偙偺傛偆側屄暿張棟儊僯儏乕採嫙傪峴偆偲丄屻偵側偭偰俵俢俢俛僣乕儖傪晛媦偝偣傛偆偲偟偰傕丄棙梡幰偼晄曋偵側傞偙偲傪棟桼偵偟偰丄偦偺棙梡偵斀懳偡傞丅
丂傑偨丄棙梡幰偑昁梫埲忋偵懱嵸偵嬅傞偙偲偑偁傞丅俵俢俢俛僣乕儖偱偼丄廲偵摼堄愭丄墶偵擭寧傪偲偭偨偲偒傕丄廲偵彜昳丄墶偵巟揦傪偲偭偨偲偒傕摨偠僨僓僀儞偵側傞丅偲偙傠偑棙梡幰偼丄偦傟偧傟堎側傞僨僓僀儞偵偟偨偑傞丅摿偵丄偳偙偵宺慄傪堷偔偐偲偐丄僼僅儞僩傪曄偊傞側偳偺丄忣曬偲偟偰偺杮幙偱偼側偔丄懱嵸傪廳帇偟偨梫媮偵側傞偙偲偑懡偄丅偦偆側傞偲丄屄暿偺弌椡挔昜偛偲偵摿暿側慻崬張棟傪嶌傞偙偲偵側傝丄僨乕僞儀乕僗傪峔抸偡傞傛傝傕丄偙傟傊偺懳張偺傎偆偵楯椡傗帪娫傪旓傗偡傛偆側杮枛揮搢側帠懺偵側傞丅
丂偙傟傪旔偗傞偨傔偵丄俵俢俢俛僣乕儖偱嶌惉偟偨昞傪僷僜僐儞偺僗僾儗僢僪僔乕僩偵曄姺偟偰丄僷僜僐儞偱曇廤偡傞偙偲偑峫偊傜傟傞偟丄懡偔偺僣乕儖偑偦偺婡擻傪帩偭偰偄傞丅偲偙傠偑丄棙梡幰偺側偐偵偼僗僾儗僢僪僔乕僩偺棙梡傪廗摼偟側偄幰傕偄傞偟丄廗摼偟偰傕柺搢偑偭偰丄帺摦揑偵峴偊傞婡擻傪慻傒崬傓偙偲傪梫媮偟偨傝偡傞丅媡偵丄僗僾儗僢僪僔乕僩偵廗弉偟偨棙梡幰偼丄懡條側僥僋僯僢僋傪嬱巊偟偰懱嵸傪傛偔偡傞偩偗偺偙偲偵懡戝側帪娫傪巊偄丄惗嶻惈偺岦忋傗憂憿惈偺岦忋偁傞偄偼寢壥偺幚柋傊偺斀塮偲偄偭偨杮棃偺栚揑偵斀偟偨嶌嬈傪偡傞偙偲傕偁傞丅
丂偙偺傛偆側棙梡幰偺庯枴偵傛傞暰奞偼僨乕僞僂僃傾僴僂僗偵尷偭偨偙偲偱偼側偔丄俤倀俠慡斒偵偄偊傞偙偲偱偁傞偑丄摿偵僨乕僞僂僃傾僴僂僗偺塣塩偵偁偨偭偰偼丄偙傟偑旓梡懳岠壥偵戝偒側塭嬁傪梌偊傞偙偲偵棷堄偟偨偄丅
俀丏俁丂儊僞僨乕僞偺廳梫惈
丂棙梡偑晛媦偟側偄尨場偲偟偰偼丄憖嶌偑擄偟偄偲偄偆傛傝傕丄僨乕僞偺撪梕傗崁栚偺堄枴偑晄柧妋側偙偲偵傛傝丄偳傟傪梡偄偰傛偄偺偐傢偐傜側偄偲偐丄弌椡偟偨寢壥偑帺暘偺婜懸偟偨抣偲堘偄崲榝偡傞偙偲偑偁偘傜傟傞丅棙梡幰偵偲偭偰偼丄偨偲偊偽乽嵼屔乿偺崁栚偱偼堷摉嵼屔偺庢傝埖偄偼偳偆側偭偰偄傞偺偐丄乽攧忋僼傽僀儖乿偱偼丄曉昳張棟偼僨乕僞偲偟偰擖偭偰偄傞偺偐丄偁傞偄偼攧忋偐傜曉昳暘傪嵎偟堷偄偰偁傞偺偐側偳偺嬈柋偲偟偰偺忣曬偑傎偟偄偺偱偁傞丅
丂傎偲傫偳偺俵俢俢俛僣乕儖偼丄儊僞僨乕僞傪帩偭偰偄傞丅儊僞僨乕僞偲偼丄僨乕僞偵偮偄偰偺僨乕僞偱偁傝丄僨乕僞偵娭偡傞偄偭偝偄偺忣曬傪擖傟偨傕偺偱偁傞丅偲偙傠偑丄捠忢偺俵俢俢俛僣乕儖偱偼崁栚偺堦棗傗懏惈側偳偑拞怱偱偁傝丄崁栚柤傗僥乕僽儖偺愢柧偺婰弎棑偼偁傞偵偟偰傕丄偣偄偤偄侾峴懌傜偢偺傕偺偱偟偐側偄丅偙傟偱偼棙梡幰偵偼偁傑傝栶偵棫偨側偄丅偦傟傪僇僶乕偡傞偨傔偵偼丄俵俢俢俛僣乕儖偲偼暿偵夝愢彂僼傽僀儖傪嶌偭偰嶲徠偝偣傞偙偲偑昁梫偵側傞偑丄偦偺婡擻偑僣乕儖偵昗弨憰旛偝傟偰偄側偄乮拲係乯丅
丂傑偨丄懡偔偺棙梡幰偑丄尦偺僨乕僞儀乕僗傪壛岺偟偰怴偟偄僨乕僞儀乕僗傪嶌傞偙偲偑懡偄丅偙偺偲偒偵丄偦偺壛岺僾儘僙僗傪怴偟偄僨乕僞儀乕僗偺儊僞僨乕僞偵宲彸偡傞偙偲偑偱偒傟偽丄棙梡幰偼懠偺棙梡幰偑拪弌偟偨僨乕僞儀乕僗傪棙梡偡傞偙偲偵傛傝丄廳暋嶌嬈偑杊偘傞偺偱偁傞偑丄偦偺傛偆側婡擻傪帩偮俵俢俢俛僣乕儖偼枹偩懚嵼偟偰偄側偄丅
俀丏係丂僨乕僞僂僃傾僴僂僗偺昁梫惈偲僨乕僞偺帩偪曽
丂僨乕僞儅乕僩偵抲偔偙偲偺偱偒傞僨乕僞検偼彫偝偄偺偱丄棙梡幰偺懡條側僯乕僘偵墳偊傞偵偼丄僨乕僞偺擖傟懼偊傕昁梫偵側傞丅傑偨丄棙梡幰偺僯乕僘偺曄壔偵墳偠偰僨乕僞儅乕僩偵帩偮僨乕僞傕偦傟偵崌傢偣偰曄偊偰偄偔昁梫偑偁傞丅
丂僨乕僞儅乕僩偺僨乕僞偼僨乕僞僂僃傾僴僂僗偐傜庢傝弌偡偺偱偁傝丄僨乕僞僂僃傾僴僂僗偑帩偮僨乕僞偺戝晹暘偼婎姴嬈柋宯僔僗僥儉偱廂廤偟儊僀儞僼儗乕儉偵曐娗偝傟偰偄傞丅偦傟側傜偽丄儊僀儞僼儗乕儉偐傜捈愙偵僨乕僞儅乕僩偵僟僂儞儘乕僪偡傟偽傛偄偺偱丄僨乕僞僂僃傾僴僂僗偼晄梫偱偼側偄偐偲傕峫偊傜傟傞丅
丂偲偙傠偑丄尰幚偵偼偦傟偱偼晄曋側偺偱偁傞丅W.H.Inmon傜(1994)傕丄婎姴嬈柋宯僔僗僥儉偱偺摑崌壔偝傟偨僨乕僞儀乕僗偱偁傞俷俢俽乮Operational Data Store乯偲僨乕僞僂僃傾僴僂僗偲偼堎側偭偨奣擮偲偟偰暘愅偡傞偙偲偑昁梫偩偲偟偰偄傞5)丅斵偼丄俷俢俽偺僨乕僞偼帪宯楍僨乕僞偱偼側偔丄僨傿僥乕儖僨乕僞偩偗偱廤栺壔傪偟偰偄側偄偙偲傪棟桼偵偟偰偄傞偑丄婎姴嬈柋宯僔僗僥儉偱偼丄惓妋惈丒恦懍惈偑廳帇偝傟傞偲偄偆杮幙揑側堄枴偱丄婎姴嬈柋宯僔僗僥儉偱偺僨乕僞傪偦偺傑傑僨乕僞僂僃傾僴僂僗偱梡偄傞偙偲偼偱偒側偄偺偱偁傞丅
丂婎姴嬈柋宯僔僗僥儉偱偼丄惓妋惈丒婰榐惈偑廳梫偱偁傞丅僨乕僞傪擖椡偟偨屻偱岆傝傪敪尒偟偨偲偒偵偼丄岆傝僨乕僞傪扨弮偵徚嫀偡傞偺偱偼側偔丄岆傝偺僨乕僞丄嶍彍偺偨傔偺僨乕僞丄廋惓偟偨僨乕僞傪曐娗偡傞昁梫偑偁傞丅偦傟偵懳偟偰僨乕僞僂僃傾僴僂僗偱偼丄寢壥偺忬嫷偑廳梫側偺偱偁傝丄岆傝廋惓棜楌偼庢傝埖偄傪柺搢偵偡傞偩偗偱偁傞丅
丂婎姴嬈柋宯僔僗僥儉偼乽斕攧僔僗僥儉乿傗乽宱棟僔僗僥儉乿側偳偺傛偆偵丄廲妱傝嬈柋偱峔抸偝傟偰偄傞丅僔僗僥儉偺岠棪惈傪廳帇偡傟偽丄偦偺嬈柋偵摿壔偟偨張棟宍懺傗僨乕僞偺帩偪曽偵偡傞昁梫偑偁傞丅偲偔偵戝検偺僨乕僞傪埖偆俷俴俿俹偱偼偦偆偱偁傞丅偦傟偵懳偟偰丄僨乕僞僂僃傾僴僂僗偱偼懡嬈柋偵傑偨偑偭偨僨乕僞傪摑崌揑偵偲傜偊傞偙偲偑廳梫偱偁傝丄屄暿嬈柋偵摿壔偟偨僨乕僞偱偼庢傝埖偄偵偔偄丅
丂偙偺傛偆偵丄婎姴嬈柋宯僔僗僥儉偺僨乕僞傪僨乕僞儅乕僩偵揮憲偡傞偵偼丄扨弮側僐僺乕偱偼側偔丄暋嶨側曄姺張棟偑昁梫側偺偱偁傞丅僨乕僞儅乕僩偱梫媮偝傟傞僨乕僞偼昿斏偵曄壔偡傞偺偱丄偦偺偨傃偵暋嶨側曄姺傪峴偆偙偲偼塣梡忋戝偒側栤戣偵側傞丅
丂偦傟傪旔偗傞偨傔偵偼丄婎姴嬈柋宯僔僗僥儉偲僨乕僞儅乕僩偱偺俷俴俙俹僨乕僞偲偺娫偵惓婯壔偟偨僨乕僞儀乕僗傪峔抸偟丄偦傟傪僨乕僞僂僃傾僴僂僗偲偟偰曐娗偡傞偺偑傛偄6)丅偦傟偵傛傝丄婎姴嬈柋宯僔僗僥儉偐傜僨乕僞僂僃傾僴僂僗傊偺曄姺丄僨乕僞僂僃傾僴僂僗偐傜僨乕僞儅乕僩傊偺曄姺偑梕堈偵側傞偺偱偁傞丅
俀丏俆丂倁俴俢俛偺僨乕僞儅僀僯儞僌
丂愭偵丄僨乕僞僂僃傾僴僂僗偲僨乕僞儅乕僩偲傪嬫暿偡傋偒偙偲傪弎傋偨偑丄俵俢俢俛僣乕儖偲僨乕僞儅僀僯儞僌傕嬫暿偟偰偲傜偊傞偺偑揔愗偱偁傞丅椉幰偲傕僨乕僞傪懡妏揑偵暘愅偡傞偙偲偵傛傝栤戣傪敪尒偡傞偙偲偑栚揑偱偁傞偑丄俵俢俢俛僣乕儖偱偼扨弮側廤寁寁嶼傪庤寉偵偱偒傞偙偲傪栚揑偲偟偰偄傞偺偵懳偟偰丄僨乕僞儅僀僯儞僌偼摑寁揑曽朄偵傛傝丄傛傝崅搙側暘愅傪栚揑偲偟偰偄傞偺偱偁傝丄偦傟偧傟偵揔偟偨僣乕儖偑偁傞丅
丂傑偨丄僨乕僞儅僀僯儞僌偺懳徾偑倁俴俢俛偱偁傞偐偺傛偆偵偄傢傟傞偙偲偑懡偄偑偦傟傕揔愗偱偼側偄丅摉慠側偑傜丄僨乕僞儅僀僯儞僌偺僣乕儖傕僨乕僞検偑彫偝偄傎偳張棟岠棪偼傛偄丅専摙偡傞帠徾偺敪惗妋棪偑斾妑揑戝偒偄応崌偵偼丄彮悢偺僒儞僾儖偱暘愅偟偰傕崅偄怣棅搙偑摼傜傟傞偙偲偼妋棪榑偺嫵偊傞偲偙傠偱偁傞丅
丂倁俴俢俛傪捈愙偵暘愅偡傞偺偱偼側偔丄倁俴俢俛偐傜斾妑揑彮検偺僒儞僾儖傪慖戰偟偰丄僷僜僐儞摍偵庢傝弌偟丄偦傟傪懡條側暘愅傪帋峴嶖岆揑偵峴偄丄偦偺寢壥傪倁俴俢俛偵偁偰偼傔偰専徹偡傞傎偆偑丄曋棙偱傕偁傝僐僗僩揑偵傕埨忋偑傝偱偁傞丅倁俴俢俛偼僨乕僞僂僃傾僴僂僗偵抲偒丄偦偺僨乕僞偼惓婯壔偡傞傋偒偩偲偄偭偨丅偦傟偼丄倁俴俢俛偦偺傕偺傪僨乕僞儅僀僯儞僌偺懳徾偲偡傞偺偱偼側偔丄倁俴俢俛偐傜揔愗側僨乕僞傪僨乕僞儅僀僯儞僌梡偵庢傝弌偡偙偲偑廳梫偱偁傝丄偦傟傪庢傝弌偡偵偼丄僨乕僞偑惓婯壔偝傟偰偄傞偺偑曋棙偩偐傜偱偁傞丅
丂偲偙傠偑丄堦晹偺婇嬈傪彍偄偰丄摑寁丒妋棪丒俷俼乮僆儁儗乕僔儑儞僘儕僒乕僠乯偺媄弍傪帩偮幰偼彮側偄丅侾俋俇侽擭戙傑偱偼丄僐儞僺儏乕僞偵偙傟傜偺媄朄傪墳梡偡傞偙偲偑壺傗偐偱偁偭偨偑丄偦偺屻偺僐儞僺儏乕僞偺敪揥偵敽偄丄偦偺傛偆側媄弍傪帩偮幰偑傓偟傠尭彮偟偰偄傞偺偑尰幚偱偁傞乮拲俆乯丅僨乕僞儅僀僯儞僌偺廳梫惈偑擣幆偝傟傞偵敽偭偰丄偙傟傜偺媄弍偑暅妶偡傞偺傪婜懸偟偨偄偺偱偁傞偑丄嵟嬤偺僨乕僞儅僀僯儞僌僣乕儖偺徯夘偱偼丄憖嶌惈傗夋柺懱嵸偽偐傝傪廳帇偟偰丄偦偺傾儖僑儕僘儉傗揔梡偵偁偨偭偰偺棷堄帠崁側偳偑偍偞側傝偵側偭偰偄傞傛偆偱偁傞丅
俀丏俇丂偄傢備傞乽戝暉挔僨乕僞乿偵偮偄偰
丂亀擔宱忣曬僗僩儔僥僕乕亁帍偼丄乽戝暉挔僨乕僞乿偲偄偆奣擮傪採彞偟偰偄傞7)8)9)丅偙傟偼丄丂婎姴嬈柋宯僔僗僥儉偱偺僨乕僞傪峫偊偰偄傞傛偆偱傕偁傞偑丄乽惗僨乕僞傪戝暉挔偺朄懃偱婰榐偡傟偽丄宱塩幚懺傪徻嵶偵挷傋傞偙偲偑壜擻偵側傝丄價僕僱僗偺摟柧搙偑戝暆偵岦忋偡傞丅偙偺僨乕僞傪僨乕僞僂僃傾僴僂僗偵惗偐偡偙偲偱丄栤戣揰偺敪尒傗暘愅丄捛愓側偳偑傛傝憗偔丄僗儉乕僘偵幚峴偱偒丄懳嶔傪偡偖偵棫偰傜傟傞傛偆偵側傞乿偲偄偭偰偄傞丅偙偺傛偆側婰帠偵塭嬁偝傟偨偨傔偐丄乽僨乕僞僂僃傾僴僂僗偵偼戝暉挔僨乕僞傪梡偄傞傋偒乿偩偲偡傞榑挷偑丄幚柋幰偺娫偱偼傛偔尒庴偗傜傟傞丅
丂偟偐偟丄偙偺戝暉挔僨乕僞傪僨乕僞僂僃傾僴僂僗偺僨乕僞偲偡傞偺偼栤戣偑懡偄丅攧忋側偳偺僀儀儞僩偑敪惗偺偨傃偵敪惗偡傞僨乕僞傪廤栺偣偢偵拁偊偰偄傞僨乕僞偺偙偲傪丄戝暉挔偱偼乽惗僨乕僞乿偲偄偆昞尰傪偟偰偄傞丅乽揱昜偺侾枃傪侾儗僐乕僪偵偡傞乿偲偟偰僨乕僞偺侾師惓婯壔傪斲掕偟偰偄傞偑丄偦傟偱偼懡條側専嶕壛岺傪偡傞偺偼戝曄偱偁傞丅傑偨丄乽娫堘偭偨揱昜傪廋惓偟偨偲偒傕岆傝揱昜偵報傪偮偗偰巆偟偰偍偔乿偲偟偰偄傞偑丄偦傟偱偼慜弎偺傛偆偵巊偄偵偔偄傕偺偵側傞丅偝傜偵丄俷俴俿俹偲俷俴俙俹偲偱摨偠僨乕僞傪巊偆偲偄偆偺偱偼丄W.H.Inmon傗E.F.Codd偺庡挘偲偼婎杮揑偵憡梕傟側偄偙偲偵側傝丄偦傟偑僨乕僞僂僃傾僴僂僗偩偲偄偆偺偼晄揔愗偩偲偄偊傞丅
丂懡條側暘愅傪偡傞偨傔偵偼丄偦偺婎偲側傞僨乕僞偼僨傿僥乕儖僨乕僞偱帩偮昁梫偑偁傞丅偟偐偟丄偦傟偼婎姴嬈柋宯僔僗僥儉偱擖椡偟偨傑傑偺乽惗僨乕僞乿偱偼側偔丄暘愅偵揔偟偨壛岺傪偟偨屻偱偺僨乕僞偱偁傞丅憖嶌惈偺搒崌偵傛傝僨乕僞傪旕惓婯宆偱帩偮応崌傕丄堦搙惓婯壔偟偰偐傜丄夵傔偰旕惓婯壔偡傞偙偲偑廳梫偱偁傞丅揔愗側張棟傪巤偟偨僨乕僞偱側偄偲丄棙梡柺偱斚嶨偵側傝丄偁傞偄偼娫堘偭偨寢壥傪摼傞婋尟偡傜惗偠傞偺偱偁傞丅
丂偙偺傛偆偵丄戝暉挔僨乕僞偼丄婎姴嬈柋宯僔僗僥儉偺曗彆偲偟偰偺忣曬専嶕宯僔僗僥儉偲偟偰偼懨摉側応崌傕偁傞偑丄僨乕僞僂僃傾僴僂僗偺僨乕僞偲偟偰偼晄揔愗側奣擮側偺偱偁傞乮拲俇乯丅
俀丏俈丂僨乕僞僂僃傾僴僂僗偺塣梡慻怐
丂俤倀俠偺悇恑慻怐偲偟偰偼丄忣曬僔僗僥儉晹栧偱偺慻怐偲棙梡晹栧偱偺慻怐乮忣曬壔儕乕僟偲偐僔僗僥儉傾僪儈僯僗僩儗乕僞側偳偲屇偽傟傞乯偑昁梫側偙偲偼傛偔巜揈偝傟偰偄傞丅昅幰偼丄偦傟偵壛偊偰丄塩嬈杮晹偲偐杮幮宱棟晹側偳偺嬈柋摑妵晹栧偵俤倀俠悇恑慻怐傪抲偔偙偲偑廳梫偱偁傞偲庡挘偟偰偒偨10)丅偙偺慻怐偼丄僨乕僞僂僃傾僴僂僗偺塣塩偵偍偄偰摿偵廳梫偵側傞丅
丂愭偵屄暿張棟儊僯儏乕採嫙曽幃傪斸敾偟偨偑丄偙傟偼曋棙側曽幃偱偁傝丄慡柺揑偵斲掕偡傞偙偲偼偱偒側偄丅棙梡昿搙偺懡偄張棟傗僷僜僐儞憖嶌偵廗弉偟偰偄側偄棙梡幰偵棙梡偝偣傞偵偼岠壥揑側曽幃偱偁傞丅
丂傑偨丄僨乕僞僂僃傾僴僂僗傗僨乕僞儅乕僩偺娗棟傪扤偑峴偆偺偐傕栤戣偱偁傞丅忣曬僔僗僥儉晹栧偑僨乕僞儅乕僩傑偱娗棟偡傞偲丄棙梡幰偼偄傑傑偱忣曬僔僗僥儉晹栧傊偺埶懚偑嫮偄偺偱丄偍偦傜偔憖嶌惈傗夋柺懱嵸側偳偺梫媮偑懕弌偡傞偱偁傠偆丅
丂偲偐偔忣曬僔僗僥儉晹栧偵偲偭偰丄棙梡幰偺僯乕僘傪斲掕偡傞偺偼崲擄偱偁傝丄屄暿張棟儊僯儏乕偵偟偰傕僨乕僞儅乕僩偺僨乕僞偵偟偰傕丄棙梡幰偺梫媮偵柍斸敾偵墳偠傞孹岦偑偁傞丅偦偺寢壥丄忣曬僔僗僥儉晹栧偼傑偡傑偡懡朲偵側傝丄棙梡幰偼忣曬僔僗僥儉晹栧埶懚偐傜敳偗弌偝側偄丅
丂偦傟偵懳偟偰丄嬈柋摑妵晹栧偼丄嬈柋偺曽恓傗巇帠偺巇曽側偳丄偦偺嬈柋偺儕僄儞僕僯傾儕儞僌傪幚尰偡傞擟柋傪帩偭偰偄傞丅偦偺堦娐偲偟偰僨乕僞僂僃傾僴僂僗偺妶梡傕悇恑偡傞棫応偵偁傞丅曽恓傪幚尰偝偣傞偨傔偵屄暿張棟儊僯儏乕傪採嫙偟偨傝丄僨乕僞儅乕僩偺僨乕僞儀乕僗傪惍旛偡傞偺傕偦偺擟柋偱偁傞偲偄偊傞丅棙梡幰偐傜偺梫媮偑偦偺曽恓偵崌抳偟偰偄傟偽愊嬌揑偵嵦梡偡傞偑丄崌抳偟側偗傟偽嫅斲偡傞偙偲傕傗傝傗偡偄丅
丂棙梡幰偺僯乕僘傪嬈柋摑妵晹栧偑庢幪慖戰偟偰忣曬僔僗僥儉晹栧偵埶棅偡傞懱惂傕峫偊傜傟傞偑丄偦傟偱偼傗偼傝忣曬僔僗僥儉晹栧偵夁忚偵墴偟偮偗傞孹岦偵側傞丅偦傟傛傝傕丄忣曬僔僗僥儉晹栧偼嬈柋摑妵晹栧偑儊僯儏乕傗僨乕僞儀乕僗峔抸偑梕堈偵偱偒傞娐嫬傪惍旛偟偰丄幚嵺偺嶌嬈偼嬈柋摑妵晹栧偑峴偆傎偆偑揔愗偱偁傞丅
丂愭偵丄儊僞僨乕僞傪傕偭偲棙梡幰偵栶棫偮婡擻傪帩偨偣傞傋偒偩偲偐丄僨乕僞僂僃傾僴僂僗偺僨乕僞偼惓婯壔偡傋偒偱偁傞偲弎傋偨偑丄偙傟傜偼嬈柋摑妵晹栧偱偺嶌嬈傪梕堈偵偡傞偙偲偵戝偒側岠壥傪帩偮偺偱偁傞丅
丂埲忋丄僨乕僞僂僃傾僴僂僗偍傛傃僨乕僞儅乕僩偺塣塩傪墌妸偐偮寬慡偵敪揥偝偣傞偨傔偵棷堄偡傋偒帠崁傪帵偟偨丅扨偵棷堄揰傪偁偘偨偩偗偱側偔丄夝寛偺偨傔偺懳張偵偮偄偰傕帵偟偨偮傕傝偱偁傞丅