�V�D�P�@�͂��߂�
�{�͂ł́C�����E�n���̂��߂̏���헪�Ɋւ��āC��Ɠ����ɂ����āC���l�I�������L�����͂��邱�Ƃɂ��C�g�D�Ƃ��Ă̑n�����̌����}�镪��ɂ��čl�@����B���̕���ł̏�p�`�Ԃ́C1970�N��̂c�r�r�iDecision Support System�j�C1980�N���ʂ��ĕ��y�������������n�V�X�e���i�P�j�C1990�N�㒆�����甭�W�����f�[�^�E�F�A�n�E�X�iData Warehouse�j�ɂ���\�����B
�����̗��p�`�Ԃ́C������x��������Z�p���͈قȂ邪�C��L���E�n��������̊ϓ_�ł͂قړ����悤�Ȉʒu�t���ɂȂ�B����Ŗ{�͂ł́C��������ʘ_�Ƃ��Ă͏���n�V�X�e���ƕ\�����C�f�[�^�E�F�A�n�E�X���L�̎����Ɋւ��Ă̓f�[�^�E�F�A�n�E�X�Ǝg�������邱�Ƃɂ���B
(1)�u��Ɩ��n�V�X�e���v�Ɓu����n�V�X�e���v�́C���{�̎����E�Ŋ��p�I�Ɏg���Ă���p��ł���C�����Ȓ�`�͂Ȃ����C�{�͂ł͎��̂悤�ȈӖ��ŗp���Ă���B��Ɩ��n�V�X�e���Ƃ́C�X�R�b�g���[�g��(Scott Morton)�ɂ��敪�ł́C�s�o�r�iTransaction Processing System�j����тh�q�r�iInformation Reporting System�j�ɑ���������̂ł���C�ŋ߂ł͂n�k�s�o�iOnline Transaction Processing�j�ƌĂ�镪��ł���B�̔��V�X�e���C���Y�V�X�e���C�o���V�X�e���Ȃǂ̂悤�ɁC�S�ГI�ȃf�[�^����I�E��^�I�ɏ������邱�Ƃ�ړI�Ƃ������V�X�e�����w���B����n�V�X�e���Ƃ́C�X�R�b�g���[�g���̂d�r�r�iExecutive Support System�j�Ɏ��Ă��邪�C�d�r�r�͌o�c�҂�Ώۂɂ������̂ł���C�����e�Ղɂ��邽�߂ɏ��V�X�e�����傪���炩���߉��H�������̂���Ă���̂ɑ��āC��Ɩ��n�V�X�e���ł́C���p�҂���ʎЈ��܂ł��Ώۂɂ��āC���p�҂����猟�����H������`�Ԃł���B�č��̎����E�ł͂c�r�r�ƌĂԂ��Ƃ��������C����ł̓X�R�b�g���[�g���́i���`�́j�c�r�r�|���݂̃p�\�R���̕\�v�Z�\�t�g�����S�[���V�[�L���O�@�\�̂悤�ȗ��p�|�܂ł��܂�ł��܂��Ɖ��߂���邱�Ƃ�����̂ŁC�����ď���n�V�X�e���Ƃ����B
�V�D�Q�@��L���E�n��������Ə���n�V�X�e��
7.2.1�@����n�V�X�e���̔��W
���V�X�e���̔��W����j�I�ɊT�ς��邱�Ƃɂ��C���V�X�e���ɂ��������n�V�X�e���̏d�v�������債�Ă������ƁC�����āC����n�V�X�e������L����n��������ɑ傫�Ȗ����������Ƃ������B
����n�V�X�e���̔��W�̐��ڂ�}�V�|�P�Ɏ����B���{�̑��Ƃ��R���s���[�^��{�i�I�ɓ������͂��߂��P�X�U�O�N�㏉���ł́C�R���s���[�^�͍����ł���\�t�g�E�F�A���n��ł������B���̂��߂ɁC���Z�p�W�c�ł�����V�X�e�����傪���S�ɂȂ�C���^�v�Z�C���㏈���C��v�����ȂǁC�f�[�^����ʂŒ�ʓI���ʂ��傫���C���I�����Ř_������r�I�P���ȋƖ��������ΏۂɂȂ����B�����ł́C�������Ɩ��n�V�X�e��(1�@�O�o)�Ƃ����B
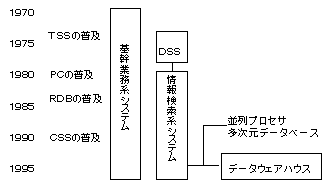
�}�V�|�P�@����n�V�X�e���̔��W
��Ɩ��n�V�X�e���̕��y�ɂ��C�Г��̊�{�I�ȃf�[�^���R���s���[�^�ɏW�ς����悤�ɂȂ�ƁC���̃f�[�^��L���Ɋ��p���邱�Ƃ����҂����悤�ɂȂ����B�܂��C�o�c�҂◘�p����́C��Ɩ��n�V�X�e�������������I�E��^�I�ł��邱�Ƃɕs���������C�A�h�z�b�N�ɔC�ӂ̐���Ō������H����������邱�Ƃ���]�����B�P�X�V�O�N��̌㔼�ɂȂ�ƁC�s�r�r�iTime Sharing System�j�Z�p�����y�������Ƃɂ��C�o�c�҂◘�p����ɔz�u���ꂽ�[������C���C���t���[���𑀍�ł���悤�ɂȂ����B�d�t�b�iEnd-user Computing�j�̊����ł����̂ł���B
���̊��ɂȂ�ƁC��Ɩ��n�V�X�e���Ŏ��W�~�ς����f�[�^���G���h���[�U�����p���₷���`���Ƀt�@�C���ɂ��Č��J���C�G���h���[�U����r�I�ȒP�ȏƉ��𗘗p���Č��J���ꂽ�t�@�C����C�ӂɌ������H���闘�p�̌n���o�������B���������n�V�X�e���ł���B
�P�X�W�O�N�㏉���ɁC�}�[�`���iMartin, J.,1986(��),pp.16-23�j�̓C���t�H���[�V�����G���W�j�A�����O�iInformation Engineering�j����C����n�V�X�e���̂悤�ȗ��p�`�Ԃ��u�v���O���}�Ȃ��̃V�X�e���J���v�Ƃ��Đ������Ă��邪�C�����ł͏���n�V�X�e�����o�b�N���O�����̂��߂̎�i�Ƃ��Ă���悤�ɁC���̍��̏���n�V�X�e���́C��Ɩ��n�V�X�e���̕⏕�I�Ȃ��̂ƔF������Ă����B��Ɩ��n�V�X�e���ɂ�葽�l�ȏ������̂ł́C���V�X�e������̕��ׂ����傷�邵�C�G���h���[�U�ɂƂ��Ă��X�̒��[�o�͂����V�X�e������Ɉ˗����Ă����̂ł͏���̂Ɏ��Ԃ�������̂ŁC�ȒP�ȏ����̓G���h���[�U�������ōs����悤�ɂ���Ƃ����ʒu�t���ł���B
����n�V�X�e���́C�P�X�W�O�N���ʂ��ĕ��y�����B�P�X�W�O�N�㒆���ɂ́C�q�c�a�iRelational Database�j�̏��������̉��P�i2�j�ƃp�[�\�i���R���s���[�^�i�ȉ��u�p�\�R���v�Ƃ����j�̕��y�ɂ��C���C���t���[������K�v�ȃf�[�^�𒊏o���ăp�\�R���Ƀ_�E�����[�h���C�g���₷���p�\�R���\�t�g�ő��l�ɕҏW���邱�Ƃ��\�ɂȂ����B����ɁC�P�X�W�O�N�㖖������P�X�X�O�N��ɂ����āC�_�E���T�C�W���O���i�݁C�b�r�r�iClient-server System�j�����y����ƁC�K�v�ȃf�[�^�𗘗p����̃T�[�o�ɒu���āC������N���C�A���g���猟�����H����`�ԂւƐi�B �@�P�X�X�O�N�����ɂȂ�ƁC����Z�p��f�B�X�N�A���C�Ȃǂ̔��W�ɂ��C����ȃf�[�^�x�[�X���i�[���Č������邱�Ƃ����p������C�������f�[�^�x�[�X�iMulti-dimensional Database�j�Ȃǂ̍��@�\�Ŏg���₷���c�[�����o���������Ƃɂ��C�f�[�^�E�F�A�n�E�X�̊T�O�����y���Ă����B
�f�[�^�E�F�A�n�E�X�̒҂̈�l�ł���C�������iInmon, W.H.,1995(��))�́C�f�[�^�E�F�A�n�E�X���u�}�l�W�����g�̈ӎv������x�����邽�߂ɁCsubject-oriented, integrated, time-variant, non-volatile�̓��������f�[�^�̏W���v�ł���ƒ�`���C���̊T�O���̂͐V�������̂ł͂Ȃ��C�b�r�r�Ƃقړ����ł���C����̔��W�`�Ԃł���Ƃ��Ă���B
����n�V�X�e���Ƃ́C��L�̊ϓ_�łƂ炦��C�G���h���[�U�Ɍ��J���ꂽ�f�[�^�x�[�X�Ƃ�����A�N�Z�X����c�[������̏W���̂ł���C�n��������̊ϓ_�ł́C�G���h���[�U�������̃f�[�^�x�[�X��c�[����p���āC�C�ӂɌ������H���邱�Ƃɂ���蔭����ۑ�����ɑn���͂�����̂��x��������V�X�e���ł���B
(2)�q�c�a�����y���͂��߂����́C�q�c�a�́C���̓����ł��铮�I�����@�\�ɂ��C�����͂��������������������̂ŁC����n�V�X�e���ɓK���Ă���C���I�ȏ�����������Ɩ��n�V�X�e���ɂ́C�ނ���m�c�a�iNetwork Database�j���K���Ă���Ƃ����Ă����B��Ɩ��n�V�X�e���ɂ��K�p�����悤�ɂȂ����̂́C�P�X�W�O�N�㒆���ł���B
�V�D�Q�D�Q�@����n�V�X�e���ɂ���L���E�n��������
��L����n��������̕���ł́C�O���[�v�E�F�A��i���b�W�}�l�W�����g�����グ���邱�Ƃ��������C��蔭����������̕���ł́C����n�V�X�e���̂悤�ɁC���l�I�ȏ������L�����đn���I�Ɍ������H���邱�Ƃ��𗧂P�[�X�������B
���Ƃ��C�Ζ��ƊE�ŗ��ʃR�X�g�팸���������邱�Ƃ��l���悤�B����͉ˋ��ł��邪�C�����炭���̂悤�ȃA�v���[�`������ł��낤�B
- ���[���Ŕz���������傫���ƃR�X�g���������낤����C�z����������������𒊏o����B
- ����ɊY������ڋq�ւ̔��㍂��e���v�̐��ڂׂ�B
- ���������璼�ڂɃ��[���ʼn^�Ԃ̂ł͂Ȃ��C�C�݂̖������֑D�ʼn^�сC�������烍�[���ʼn^��R�X�g���ǂ��Ȃ邩��������B
- ���̖������̎戵�ʂ����債�Ă��^���N�̂�肭�肪�ł��邩�ǂ�����������B
- ���Ђ̖������ł͂Ȃ��C���Ђ̖��������肽��ǂ��Ȃ邩��������B
- �������̂��ƁC���А���������^�Ԃ̂ł͂Ȃ��C���Ђ̐���������o�ׂ�����ǂ��Ȃ邩����������B
���̂悤�Ȃ��Ƃ��C�C���Â�I�ɉ����������s���낷��ߒ��ŁC���P�ł���Ă������{���Ă������Ƃɂ�藬�ʃR�X�g���팸�ł���̂ł���B
���Ȃ킿�C�]�����瑶�݂���f�[�^�����L�����āC�]���͋C�Â��Ȃ���������Ō������H���邱�Ƃ��n���I�ȉ��P�E���v�ɖ𗧂̂ł���B���̂悤�ȃA�v���[�`�͈��̒m���̋��L���C�g�D�̑n�����̌���Ƃ������悤�B�����āC������\�ɂ���̂�����n�V�X�e���ł���f�[�^�E�F�A�n�E�X�Ȃ̂ł���B
�V�D�R�@����n�V�X�e���Ɗ�Ɩ��n�V�X�e���̊W
�V�D�R�D�P�@����n�V�X�e���Ɗ�Ɩ��n�V�X�e���̊W�̋t�]
�{�߂ł́C����n�V�X�e�������V�X�e���̎���ł���C����n�V�X�e�����p����f�[�^�𐳊m�ɉ~���ɋ�������̂���Ɩ��n�V�X�e���ł���ƍl����ق����K�ł��邱�ƁC�������C����n�V�X�e���𒆐S�ɍl���Ċ�Ɩ��n�V�X�e�����\�z����ƁC�������e�ՂȊ�Ɩ��n�V�X�e���ɂł��邱�Ƃ������B
�O�q�̂悤�ɁC����n�V�X�e�����o�����������ł́C����n�V�X�e���́C��Ɩ��n�V�X�e���̕⏕�I���邢�͕t�ѓI�Ȉʒu�t���ł������B�������C���̂悤�ȔF���ł́C����n�V�X�e���ɋ��������f�[�^�́C��Ɩ��n�V�X�e���ŕK�v�Ƃ���f�[�^�ɐ���Ă��܂��B�Ζ��ƊE�ɂ�����s�撬���}�X�^�t�@�C���̎�舵�����ɂ��悤�B�K�\�����X�^���h�̐V�݁C�p�����C�]���Ȃǂ̂��߂ɂ́C�s�撬���ɂ����鐢�ѐ��C�����ԕۗL���C�K�\�����X�^���h�̐��Ȃǂ͕K�{�ȍ��ڂł���B�Ƃ��낪�C��Ɩ��n�V�X�e���ł́C�s�撬���}�X�^�t�@�C���͒P�Ȃ�Z���}�X�^�ɉ߂��Ȃ��̂ŁC�����̍��ڂ����W���邱�Ƃ���v�����Ȃ��ł��낤�B
�������p����ɂ́C�܂��C�ǂ̂悤�ȍ��ڂ��K�v�ł��邩���l���C���ɁC�����̎��W��i���l����ׂ��ł���B���Ȃ킿�C���V�X�e���͏���n�V�X�e���ł̗p�r���s���č\�z����ׂ��Ȃ̂ł���B�܂��C����n�V�X�e���̃f�[�^�̕i�����Ⴂ�ƁC���ꂩ�瓾������̕i�����Ⴍ�Ȃ�C�ӎv�������点�邱�ƂɂȂ�B�f�[�^�̕i�������߂�ɂ́C���W���@�ƕi���Ǘ��̃��[�����߂āC������������邱�Ƃ��K�v�ɂȂ邪�C���ꂪ��Ɩ��n�V�X�e���Ȃ̂ł���B���Ȃ킿�C��Ɩ��n�V�X�e���Ƃ͏��V�X�e���ɕi���̂悢�f�[�^����������@�\�Ȃ̂ł���i�}�V�|�Q�j�B
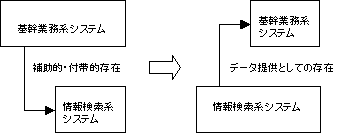
�}�V�|�Q�@����n�V�X�e���̈ʒu�t���̕ω�
�V�D�R�D�Q�@����n�V�X�e���ɂ���Ɩ��n�V�X�e���̊ȑf��
�i�P�j���o�͕����̕����ɂ��ȑf��
����n�V�X�e���y����ړI�́C�K�v�Ȑl���K�v�ȂƂ��ɕK�v�ȏ���e�Ղɓ�����悤�ɂ��邾���ł͂Ȃ��B�o�c���̌��ςɑΏ�����ɂ́C��Ɩ��n�V�X�e�������ɉ����ĉ�������K�v�����邪�C����n�V�X�e���y�����邱�Ƃɂ��C��Ɩ��n�V�X�e�����������e�ՂȃV�X�e���ɂ��邱�Ƃ��ł���̂ł���B
����n�V�X�e���y����C�X�̒��[�����̂ł͂Ȃ��C���̊�ɂȂ�f�[�^�����J�f�[�^�x�[�X�Ƃ��Ē��邾���ł悢�̂ŁC��Ɩ��n�V�X�e���S�̂̋K�͂��������ł���B�܂��C�f�[�^���͂̕������C������x�̓��[�U�̐v�ɔC���邱�Ƃ��ł���B
���o�͕��������Ȃ��Ȃ邱�Ƃ́C�q���[�}���C���^�t�F�[�X�Ɋւ��镔�������Ȃ��Ȃ�C�����̑啔�����t�@�C���Ԃł̃��W�b�N�̏��������ɂȂ�B���̂��߂ɁC�b�n�a�n�k�̂悤�Ȓ����I����ł͂Ȃ��ȈՌ���ŋL�q�ł���̂ŁC�����K�͂ł����Ă������ɕK�v�ȍ�Ɨʂ����Ȃ����邱�Ƃ��ł���B�܂��C�q���[�}���C���^�t�F�[�X�̕����́C�g�D�̉�����d���̕ύX�Ȃǂɔ����������Ȃ���Ȃ�Ȃ����C���W�b�N�̕����͊����ω����Ă���������K�v����r�I���Ȃ��B���̂��߂ɁC��Ɩ��n�V�X�e���̉������̂��̂������ł���B�}�V�|�R�́C����n�V�X�e���̕��y�ɂ��C��Ɩ��n�V�X�e���̋K�͂����ɏ������ł��邱�Ƃ������B
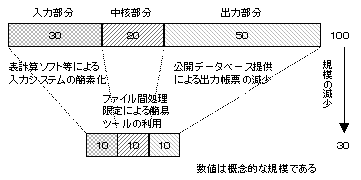
�}�V�|�R�@����n�V�X�e���ɂ���Ɩ��n�V�X�e���̋K�͍팸
�i�Q�j�}�X�^�t�@�C���̐����ɂ��ȑf��
�����ł́C���Ӑ�}�X�^�⏤�i�}�X�^�̂悤�ȑ䒠�I�ȃf�[�^�����t�@�C�����}�X�^�t�@�C���Ƃ����C����t�@�C����Ƀt�@�C���̂悤�ɃC�x���g���������邽�тɗݐρE�X�V�����t�@�C�����C�x���g�t�@�C���Ƃ����B
����n�V�X�e���ł́C�}�X�^�t�@�C���̍��ڂ��L�[�Ƃ��āC�C�x���g�t�@�C���̃��R�[�h��I���E���ށE�W�v���鏈�����命���ł���B�]���āC����n�V�X�e�����\�z����ɂ́C�܂��}�X�^�t�@�C���̑̌n�����s���C���ڂ̐��������邱�Ƃ��K�v�ɂȂ�B
���Ƃ��C�������̓��Ӑ�ɗ�O����������Ƃ��C
�@�@�@�@�h�e�@���Ӑ�R�[�h�������@�n�q�@�~�~�@�E�E�E
�Ƃ���̂ł͂Ȃ��C���Ӑ�}�X�^�t�@�C���ɓ��Ӑ�敪�Ƃ������ڂ�݂��āC
�@�@�@�@�h�e�@���Ӑ�敪���P�@�E�E�E
�Ƃł���悤�ɂ��Ă������Ƃ��]�܂����B���̂悤�ȍ��ڂ́C��Ɩ��n�V�X�e���Ō��������������n�V�X�e������̗v���ɂ��C�Â����Ƃ������̂ł���B
���̂悤�ɁC��Ɩ��n�V�X�e���̍č\�z�ɐ旧���C����n�V�X�e�����\�z���邱�Ƃɂ��C�}�X�^�t�@�C���̍��ڂ��C�����܂ł��܂߂Đ����ł���̂ł���B�}�X�^�t�@�C���̑̌n�����ł��邱�Ƃɂ��C��Ɩ��n�V�X�e���̍\�z�̓C�x���g�t�@�C��������Ώۂɂ���悢�̂ŁC���̋K�͂����Ȃ菬�����ȑf���ł���B
�V�D�R�D�R�@�f�[�^���S�A�v���[�`�Ə���n�V�X�e��
�i�P�j�f�[�^���S�A�v���[�`�̗��_
�������e�ՂȃV�X�e���ɂ���ɂ́C�f�[�^���S�A�v���[�`�i�c�n�`�FData Oriented Approach�j�ɂ��V�X�e���J�����L���ł���Ƃ����Ă���B����n�V�X�e����O��Ƃ��邱�Ƃɂ��C��Ɩ��n�V�X�e�����f�[�^���S�A�v���[�`�ō\�z���₷���Ȃ�B
�f�[�^���S�A�v���[�`�Ƃ́C�f�[�^�\�����V�X�e���\�z�̊�b�Ƃ���l�����ł���C�f�[�^���S�A�v���[�`�ɂ��\�z���ꂽ�V�X�e���́C���̂悤�ȗ��_������B
- �@�V�X�e���������e�ՂɂȂ�
- �o�c���͌��ς��Ă���C����ɔ�����Ɩ��n�V�X�e���ւ̉����v�������傷��B�������������������̂ŒZ���Ԃł̉������v�������B���̂��߁C�������e�Ղɂł���V�X�e�����D�ꂽ�V�X�e���ł���Ƃ�����B
�@�o�c���̕ω��ɂ��C���Ӑ��[����C�戵���i�Ȃǂ͑傫���ω�����ł��낤���C���Ӑ�Ɣ[����̊Ԃɐe�q�̊W������Ƃ��C�戵���i�͂������̏��i�n��ɋ敪�����Ƃ������f�[�^�\���́C��قǂ̌o�c�����ω����Ȃ�����ω����Ȃ��B�܂��C���K���inormalization�j�����t�@�C���Q�ł́C���Ӑ�⏤�i�Ƃ��������ڂ͈ꃖ���ɂ������݂��Ȃ��B���̂��߁C�V�K�̓��Ӑ悪����������C���i��p�������肷��Ƃ����t�@�C���̈ꃖ�������C�����邾���ŁC�S�̂𐮍��I�ɏC�����邱�Ƃ��ł���B���Ȃ킿�C�f�[�^���S�A�v���[�`�ɂ��C�������e�ՂȃV�X�e���ɂ��邱�Ƃ��ł���B - �A���������V�X�e�����\�z���₷��
- ���Ӑ�⏤�i�́C�̔��V�X�e�������łȂ��C���ʃV�X�e�����v�V�X�e���Ȃǂɂ��W����B�d�q�ientity-relationship�j���f�������C���Ӑ�⏤�i�̑������l����Ƃ��C�P�ɔ̔��V�X�e�������łȂ����̃V�X�e���ł̗��p���l���邱�Ƃ͔�r�I�e�Ղł��邵�C���̂悤�ɂ��č쐬�������Ӑ�}�X�^�t�@�C���⏤�i�}�X�^�t�@�C���́C�ǂ̃V�X�e���ł����ʂ��ė��p�ł���B���Ȃ킿�C�f�[�^���S�A�v���[�`�ɂ��C�c����̃V�X�e���ł͂Ȃ��C�����������V�X�e���ɂ��邱�Ƃ��e�Ղł���B
�i�Q�j����n�V�X�e���ƃf�[�^���S�A�v���[�`�̊W
����n�V�X�e���ł̌��J�f�[�^�x�[�X�́C�f�[�^�i�Ƃ��đ��l�ȗp�r�ɗ��p����̂��ړI�ł��邩��C���K�����Ă��邱�Ƃ��]�܂����B�܂��C����n�V�X�e���ł́u���Ђ��w�����Ă�������ɁC���Џ��i���ǂꂾ���[�����Ă��邩�v�Ƃ����悤�ȁC�����I�ɕ��͂��鏈�����������C����ɂ͊e�V�X�e��������������Ă���K�v������B�܂��C��q�̃}�X�^�t�@�C���̐����́C�K�R�I�ɉ����I�ȗ��p��O��Ƃ�����̂ł���C�������܂߂����ڂ̐����́C�K�R�I�Ƀf�[�^���S�A�v���[�`��v������B
���Ȃ킿�C����n�V�X�e���ł̌��J�f�[�^�x�[�X�́C�f�[�^���S�A�v���[�`�Ŋ�Ɩ��n�V�X�e�����\�z����Ƃ��̖ڕW�ƂȂ�B�܂��C�f�[�^���S�A�v���[�`�Ŋ�Ɩ��n�V�X�e�����\�z����ƁC����n�V�X�e���̌��J�f�[�^�x�[�X���e�Ղɍ\�z�ł���̂ł���B
�V�D�R�D�S�@�d�q�o�p�b�P�[�W�����Ə���n�V�X�e��
�i�P�j����n�V�X�e���ɂ��J�X�^�}�C�Y�̌���
�ŋ߂͂d�q�o�iEnterprise Resource Planning�j�p�b�P�[�W�����ڂ���Ă���B�d�q�o�Ƃ́C��ƑS�̂̌o�c�����̍œK�z����}����̂ł���C�d�q�o�p�b�P�[�W�̓��G���W�j�A�����O���������邽�߂̊�Ղł���Ƃ����Ă���B
�d�q�o�p�b�P�[�W�̓����ɂ������ẮC����n�V�X�e�����ɍ\�z����̂��悢�B���Ȃ��Ƃ��C����n�V�X�e����O��Ƃ��Ăd�q�o�p�b�P�[�W�̑Ώۋ@�\���������ׂ��ł���B
�d�q�o�p�b�P�[�W�𐬌�������ɂ́C�J�X�^�}�C�Y�icustomize�j�i3�j�����Ȃ����邱�Ƃ��d�v���Ƃ����Ă���B�Ƃ��낪�C�����ɂ͑��l�ȏo�͏�K�v�ɂȂ�B������d�q�o�p�b�P�[�W�ŃJ�o�[�����悤�Ƃ���ƁC�d�q�o�p�b�P�[�W�̋K�͂��傫���Ȃ邾���łȂ��C���ω��ɉ������J�X�^�}�C�Y�������I�ɂ������Ȃ�댯������B��ʓI�ɂd�q�o�p�b�P�[�W�ł́C���o�͕����͊�Ɗ��ɂ��قȂ�̂Ŏd�l���ȑf�ɂȂ��Ă���B�]���̌ʃV�X�e���Ɣ�r���āC�q���[�}���C���^ 8�N2��16�����j�ł́C�u�V���z�̃f�[�^�E�E�F�A�n�E�X�v�̓��W�����Ă���C�P�X���̗�������āC���C������x���^�T���C�X�^�b�t����x���^�W���C�S�Ј��x���^�U���ɋ敪���Ă���B�S�Ј��x���^�̑����ƃ��C������x���^���ʏ������j���[�^�ł���B����ȊO�̂��̂͂قƂ�ǂ��������f�[�^�x�[�X�^�ł���C���L�͂��Ă��Ȃ����C���̈ꕔ�͌ʃ��j���[����Ă���悤�Ɏv����B
�i�Q�j�������f�[�^�x�[�X�ƃf�[�^�}�C�j���O
�R�b�h��iCodd,E.F.�CCodd, S.B. & Salley, C.T.,1993(��),pp.170-210)�́C�f�[�^�E�F�A�n�E�X�̂悤�ȕ��͂���̂Ƃ��闘�p�`�Ԃ��n�k�`�o�iOnline Analytical Processing�j�Ɩ������C�n�k�`�o�ɓK�����f�[�^�̎������Ƃ��ẮC�q�c�a�����������f�[�^�x�[�X���K���Ă��邱�Ƃ��������B
�܂��C���ꂩ��̃}�[�P�e�B���O�ł͌ڋq�̍w���s�����l�̃��x���Ŕc�����邱�Ƃ��d�v�ŁC����ɂ͑�ʂ̃f�B�e�[���f�[�^���f�[�^�}�C�j���O����̂��L�����Ƃ����Ă���B�Ƃ����C���̓�͍������ėp�����邪�C���̃c�[���ɂ���p������f�[�^�ɂ���C�����͈Ⴄ���̂��Ɖ��߂���ׂ��ł���B
�������f�[�^�x�[�X�ł̏����́C��ʓI�ɒP���ȏW�v�v�Z�ł���B���̂��߁C���v�w�̒m�����Ȃ��Ƃ��C�����I�Ȓm��������Δ�r�I�ȒP�Ɋ��p�ł��邵�C��r�I����p�����Ȃ��B��ʂɓ���Ɩ��ł̖�蔭���I�ȗp�r�ɗp�����ׂ��c�[���ł���B
����ɑ��āC�f�[�^�}�C�j���O�̃c�[���́C���x�ȓ��v��@���p�����C���̃��f���쐬�⌋�ʂ̉��߂ɂ́C���x�ȓ��v�I�Ȓm�����v�������B�Ƃ������̂悤�ȏ����́C���W�̍��ڂ����v�I�ɈӖ������悤�Ȍ��ʂɂȂ����肷��B���v�w�̒m�����Ȃ��ƁC�\�ʓI�Ȍ��ʂ��L�ۂ݂ɂ���댯������B���͐��Ƃ����p���ׂ��c�[���Ȃ̂ł���B
�V�D�S�D�Q�@�f�[�^�E�F�A�n�E�X�p�f�[�^�x�[�X�ł̍���
�i�P�j�f�[�^�E�F�A�n�E�X�ł̃f�[�^�x�[�X
�f�[�^�E�F�A�n�E�X���\������v�f�ɂ́C�S�ГI�ȃf�[�^��ۊǂ���i���`�́j�f�[�^�E�F�A�n�E�X�ƁC�e����ɐݒu�����f�[�^�}�[�g�iDatamart�j������B�f�[�^�}�[�g�ł̃f�[�^�̎������Ƃ��ẮC�������ɂq�c�a�����������f�[�^�x�[�X���K���Ă���Ƃ����邪�C�f�[�^�E�F�A�n�E�X�ł́C�ނ���q�c�a�̂ق����K���Ă���B�܂��C������u�啟���f�[�^�x�[�X�v���K���Ă���Ƃ̕��������邪�C����̓f�[�^�E�F�A�n�E�X�ɂ͕s�����ł���B
�G���h���[�U�̗v���͑��l�ł���ω�����B�f�[�^�}�[�g�̃f�B�X�N�e�ʂ͔�r�I����������C���ׂĂ̗v���������邾���̃f�[�^��ۊǂł��Ȃ��̂ŁC�K�v�ɉ����ăf�[�^�E�F�A�n�E�X����f�[�^�}�[�g�Ƀf�[�^���_�E�����[�h����K�v������B���Ȃ킿�C�f�[�^�E�F�A�n�E�X�̓f�[�^�}�[�g�̃f�[�^�ۊnjɂł���Ƃ�������B���̊ϓ_�ł́C�f�[�^�E�F�A�n�E�X�ł́C�C�ӂ̐���Ńf�[�^�𒊏o���₷���f�[�^�̎��������]�܂��B����ɂ͐��K�������q�c�a���K���Ă���B
���������C�Ȃ��f�[�^�E�F�A�n�E�X���K�v�Ȃ̂��낤���B��Ɩ��n�V�X�e���̃f�[�^��ێ����Ă��郁�C���t���[��������̂�����C���C���t���[�����璼�ڂɃf�[�^�}�[�g�Ƀ_�E�����[�h����悢�̂ŁC�f�[�^�E�F�A�n�E�X�͕s�v���Ƃ��l������B�Ƃ��낪�C��Ɩ��n�V�X�e���̃f�[�^�͐��m����������̊ϓ_����C�ʂ̏����ɓK�����f�[�^�\���ɂ��Ă���B���̍\���̓f�[�^�}�[�g�ŕK�v�Ƃ���\���Ƃ͈�v���Ă��Ȃ��B���̕ϊ��ɂ͊�Ɩ��n�V�X�e���̒m�����K�v�ł���C���������G�ȏ������K�v�ɂȂ�B����ł́C�f�[�^�E�F�A�n�E�X�|�f�[�^�}�[�g�̉^�c�ێ�������ɂȂ�B������������邽�߂ɁC���̊ԂɃf�[�^�E�F�A�n�E�X��ݒu����̂ł���B
��Ɩ��n�V�X�e���̃f�[�^����f�[�^�}�[�g�̃f�[�^�ւ̕ϊ���e�Ղɂ���ϓ_������C�f�[�^�E�F�A�n�E�X�̃f�[�^�͕��i�Ƃ��Ďg����悤�ɐ��K�����Ă������Ƃ��K�v�Ȃ̂ł���i�ؕ�,1997,pp.103-113)�B���C���t���[���ł̊�Ɩ��n�V�X�e���C�f�[�^�E�F�A�n�E�X����уf�[�^�}�[�g�̊W��}�V�|�S�Ɏ����B
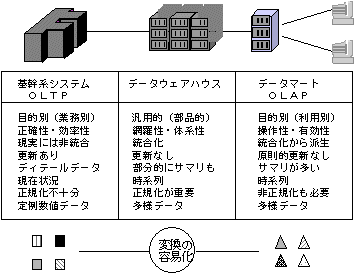
�}�V�|�S�@��Ɩ��n�V�X�e���C�f�[�^�E�F�A�n�E�X�C�f�[�^�}�[�g�̊W
�i�R�j������啟���f�[�^�x�[�X
�o�c���֘A�̗L�͂ȎG���ł���w���o���X�g���e�W�[�x�́u�啟���f�[�^�x�[�X�v����Ă���(5)�B����ɂ��C�f�[�^�E�F�A�n�E�X�ł̓f�B�e�[���f�[�^�����n��Ŏ����Ƃ���C�f�[�^�E�F�A�n�E�X�ł͑啟���f�[�^�x�[�X�Ŏ��̂��Ƃ����\���������Ƃ̊Ԃŗ��z���Ă���B�ǂ��������҂̂Ȃ��ɂ́C�u���f�[�^�v�Ɓu�f�B�e�[���f�[�^�v���������Ă��镗��������B�@�������C�f�[�^�E�F�A�n�E�X�̃f�[�^�ɂ͑啟���f�[�^�x�[�X�͕s�K�Ȃ̂ł���B���������啟���f�[�^�x�[�X�͊�Ɩ��n�V�X�e����z�肵�����̂ł���C�f�[�^�E�F�A�n�E�X�̂悤�ȏ���n�V�X�e���ɂ͌����Ă��Ȃ��B�Ԉ�����f�[�^��ۑ����邱�Ƃ́C��Ɩ��n�V�X�e���ł͏d�v�Ȃ��Ƃł��邪�C�f�[�^�E�F�A�n�E�X�̂悤�ȗ��p�ł͑���G�ɂ����Ă��܂��B
�܂��C�啟���f�[�^�x�[�X�ł͐��K����ے肵�Ă��邪�C��q�̂悤�ɁC�ނ��됳�K�������f�B�e�[���f�[�^���]�܂����̂ł���B�悵��ΔK���f�[�^�Ŏ��ɂ��Ă��C����́u���́v�f�[�^�ł͂Ȃ��C�������K��������ŁC�������l�����čœK�����ׂ��Ȃ̂ł���B
(5) �w���o���X�g���e�W�[�x���̂P�X�X�R�N�W�����Cpp. 34-56, �u�V����������ƍזE���h�啟���h�V�X�e�����j��v�ł́C�u�啟���f�[�^�̂S�����v�̒��ŁC�u��Ɗ����Ő������f�[�^�͉��H�����C���f�[�^�Ɍ`�ŋL�^���C���ڃA�N�Z�X����v�Ƃ��Ă���B�P�X�X�S�N�W����pp.42-66, �u�}���`���f�B�A����̑啟���V�X�e���F�N���C���C������������������v�ł́C�u���̓f�[�^�͂��̂܂܂P���P���Ăю��o����悤�ɋL�^����v�u�Ԉ�����f�[�^����͂��Ă������Ă͂Ȃ�Ȃ��v�Ƃ��Ă���B�܂��C�P�X�X�U�N�X���� pp.89-108�C�u�啟���V�X�e���ƃf�[�^�E�F�A�n�E�X�|��p�͍]�ˎ���Ɋw�ׁv�ł́C�u���f�[�^��啟���̖@���ŋL�^����Υ�����̃f�[�^���f�[�^�E�F�A�n�E�X�ɐ��������ƂŁA���_�̔����╪�́A�ǐՂȂǂ���葁���A�X���[�Y�Ɏ��s�ł��A��������ɗ��Ă���悤�ɂȂ�v�Ƃ����Ă���B
�V�D�T�@����n�V�X�e���̕��y��j�Q����v��
�V�D�T�D�P�@�f�[�^���J�ɂ�����Z�N�V���i���Y��
�O���[�v�E�F�A�̗L�����p�̂��߂ɂ́C�g�D�����̉e�����傫���Ƃ����Ă��邪�C����n�V�X�e���ɂ����Ă��C�g�D�̑̎������W��j�Q���Ă��邱�Ƃ������B�܂��C����n�V�X�e���̊��p�ł́C�G���h���[�U�̏�e���V�̌��オ�����Ă��邪�C�����ł́C�G���h���[�U�̉ߏ���ߏ�ˑ��̑̎����j�Q�v���ɂȂ��Ă��邱�Ƃ������i6�j�B
����n�V�X�e���̃f�[�^�̑啔���͊�Ɩ��n�V�X�e���Ŏ��W�������̂ł��邩��C�O���[�v�E�F�A�̂悤�Ɂu�d�v�ȏ��͓��͂��Ȃ��v�Ƃ������͑��݂��Ȃ��B�������C���̃f�[�^�����J����i�ɂȂ�ƁC���낢��Ȉӌ����o�Ă��āC���J�ł��Ȃ��Ƃ��C���J����ɂ��Ă����G�ȊǗ������Ȃ���Ȃ�Ȃ����Ƃ�����B
���Ƃ��C�Ђ̕��j�Ƃ��Ēl���̔��������Ƃ��ċւ��Ă���̂����C���炩�̎���ł`�x�X���l���̔��������Ƃ��悤�B����ƁC�`�x�X���l���������̂��C�`�x�X�͌��\�������Ȃ����C�{�Љc�Ɠ�������́C����𑼎x�X���m��������Ēl���̔��ɑ��邾�낤�ƍl����B����ŁC�u�̔����ʂ����J����̂͂悢���C�P���͌��J���Ȃ��v�C�u�T�}���[�f�[�^�͂悢���f�B�e�[���f�[�^�ł͋��z�����Ȃ��v�C�u�f�B�e�[���f�[�^�̒P���͊Y���x�X�������Ɍ��J����v�Ƃ����悤�Ȉӌ����o�Ă���B
���邢�́C�f�[�^�����J���邱�Ƃɂ�葼���傩��Ƃ₩��������̂������āC�u�f�[�^�̍\�������G�Ȃ̂ŁC�����m��Ȃ��҂��������H������ƁC������������ʂɂȂ�B�K�v�ȏ�ق�����Γ������o�͂��ēn������C�f�[�^�̌��J�͂���ׂ��ł͂Ȃ��v�Ƃ����悤�Ȉӌ����łĂ���B
����Z�N�V���i���Y���̋����g�D����������Ƃ��ɂ́C�f�[�^�E�F�A�n�E�X�̊��p�ȑO�ɁC���̂悤�Ȗ����������Ȃ���Ȃ�Ȃ��̂ł���B
(6)�����Ɍf����悤�Ȏ��ۂ́C�����g�D�̌��_�ɂȂ邽�߂��C���\����邱�Ƃ͏��Ȃ��B�������C������̏�ł́C���V�X�e������̋�s�Ƃ��Ă悭�b��ɂȂ邱�Ƃł���B
�V�D�T�D�Q�@�ߏ�̍و��D�ǂƉߓx�ˑ���
�i�P�j�G���h���[�U�̉ߏ�̍و��D��
�O���[�v�E�F�A�ł͂��܂���ɂȂ�Ȃ����Ƃ��C����n�V�X�e���̕��y�ł͑傫�Ȗ��ɂȂ邱�Ƃ�����B���Ƃ��u�x�X�ʕ{���ʔ���W�v�\�v�����Ƃ���B�f�[�^�x�[�X����������Ă���C�K�Ȕėp�I�ȃc�[��������C�x�^�ł��̐��\�̌`���ł������肷��͎̂��ɊȒP�ł���B�������C�G���h���[�U�́C����ł͖������Ȃ��B�}�V�|�T�̂悤�ɁC�܂��C�r�������������邪�C���̃f�U�C���͒��[�ɂ��قȂ�̂ŁC�ėp�c�[���ł͑Ώ��ł����C�ʂ̏������K�v�ɂȂ�B����ɁC�O���t�����������邪�C�ʏ�̖_�O���t�Ȃǂł͖��������C�n�}�ɐ��i�̌`�ő傫����\���悤�Ȍ`���ɂ܂ł�������B���Ȃ킿�C�G���h���[�U�́C��ق����̂ł͂Ȃ��C���ꂢ�Ȓ��[���ق����̂ł���B����ł̓G���h���[�U�̐��Y���͌��サ�Ȃ��B
�}�V�|�T�@�G���h���[�U�̉ߏ����D��
�i�Q�j�G���h���[�U�̏��V�X�e������ւ̉ߓx�ˑ���
���̂悤�ȕ������L�܂�ƁC�����ł͍��x�ȉ��H������Z�p�������Ȃ��҂܂ł��C�̍قɋÂ������[�����߂�悤�ɂȂ�C��������V�X�e������ɗv������B�f�[�^�E�F�A�n�E�X�̃c�[���͕֗��ł���C���l�ȋ@�\�����邪�C�G���h���[�U�͂�����K�����悤�Ƃ����ɁC���V�X�e������ɃO���t�܂ʼn��H����̂������^�b�`�łł���悤�ȃ}�N���@�\��g�ݍ��ނ��Ƃ�v������悤�ɂȂ�B����ł́C���V�X�e�����傪�d�������Ă��܂��B
�f�[�^�E�F�A�n�E�X���������́C�Ƃ������g�킹�邱�Ƃ��ړI�ɂȂ�C�ʏ������j���[�^�̃T�[�r�X���������ł���B����͎���₷�����C���܂ł�����𑱂��Ă���ƁC�G���h���[�U�̗v���������Ȃ����Ƃ��ɁC���V�X�e�����傪�Ή��ł��Ȃ��Ȃ�C�J�^�X�g���t�B���N����댯������B�܂��C�G���h���[�U�̓��j���[�ł̉^�p�Ɋ���Ă��܂��C�������f�[�^�x�[�X�^��f�[�^�}�C�j���O�^�Ɉڍs���邱�Ƃ��ł��Ȃ��Ȃ�C�C���Â�I�ȗ��p�C���Ȃ킿�C��蔭����n�����̌��オ�j�Q�����댯������B
�V�D�U�@���ꂩ��̃f�[�^�E�F�A�n�E�X
�V�D�U�D�P�@�f�[�^�E�F�A�n�E�X�ƃ��^�f�[�^
�i�P�j�G���h���[�U�̂��߂̃��^�f�[�^�i�G���h���[�U�p�����j
�f�[�^�E�F�A�n�E�X�͑g�D�̑n���������コ���邽�߂ɏd�v�ȃc�[���ł���B���̖ړI�������ʓI�ɂ���ɂ́C�P�ɑ��쐫�����P����Ƃ��C���l�ȏ������ł���悤�ɂ��邾���ł͂Ȃ��C�f�[�^�Ǘ��̋@�\����������K�v������B
�G���h���[�U�ւ̍u�K����J�Â��Ă��C�Ȃ��Ȃ����p�ɂ܂Ŏ���Ȃ��Ƃ�����B���̗��R�́C���p�Z�p��������炵�Ċ̐S�̃f�[�^�\���Ȃǂ̐������s�\��������ł���B�G���h���[�U�ɂƂ��č���Ȃ̂́C�p�\�R���̑����c�[���̗����Ȃǂ����C�ǂ̂悤�ȃt�@�C��������̂��C�ǂ̂悤�ȍ��ږ�������̂��C���̍��ڂ̓��e�͂ǂ��Ȃ��Ă���̂��Ȃǂ��킩��Ȃ��̂ł���B����ŁC�u�K��ł͗������Ă��C�����Ŏg���Ȃ����C�����Ŏg��Ȃ�����K���ł��Ȃ��̂ł���B
�f�[�^�E�F�A�n�E�X�ł̓��^�f�[�^���d�v�Ȃ��Ƃ́C�]������w�E����Ă���B�������C�����ɂق����̂̓G���h���[�U�̂��߂̎����ɑ���������̂��ق����̂��ł��邪�C���p�\�t�g�E�F�A�ł́C�܂���������ɂȂ��Ă��Ȃ��B
���ɓ�̗���������C����������݂̋Z�p�Ŕ�r�I�e�ՂɎ����ł���ł��낤���C����炪��������C���܂��������Ȃ��Ōʏ������j���[�^�̊����\�z�ł���B
���̑�P�̗Ⴊ�G���h���[�U�̂��߂̃��^�f�[�^�i�G���h���[�U�p�����j�ł���B���Ƃ��u���Ӑ�ʏ��i�ʔ���W�v�\�v�����߂�v���Z�X�ōl���悤�B
- ���Ӑ悪�u���Ӑ�v�Ȃ̂��u�ڋq�v�Ȃ̂��킩��Ȃ��B�܂��C���Ӑ�Ƃ͑���̐�����Ȃ̂����i�̔[����Ȃ̂��s���ł���B
- �����炭����t�@�C���͐���ނ���ł��낤�B�f�B�e�[���f�[�^�Ŏ����Ă���̂��T�}�����Ă���̂��C�ۊǂ��Ă���f�[�^�͂����炢�܂ł̃f�[�^�Ȃ̂��Ȃǂ��킩��Ȃ��Ǝg���Ȃ��B���邢�́C����̂Ȃ��ł���O�����̃f�[�^�������Ă��Ȃ������m��Ȃ��B
- ����̌����s���ł���B���Ƃ��R���ɂP�O�O�o�ׂ������̂��S���ɂP�O�ԕi�ɂȂ����Ƃ��C�R���̃f�[�^���P�O�O�łS�����|�P�O�i���邢�́{�P�O�j�ƂȂ��Ă���̂��B���邢�͂R�����X�O�ɏC�����Ă���̂��낤�����킩��Ȃ��ƁC���ʂ𐳂����������邱�Ƃ��ł��Ȃ��B
�G���h���[�U�ɂƂ��ẮC���̂悤�ȋ^��ɓ�����I�����C���������ق����̂ł���B���̗��}�V�|�U�Ɏ����B
�}�V�|�U�@�G���h���[�U�p�����̑̌n�}��
�t�ɁC���̂悤�ȋ@�\����������Ă���C�G���h���[�U���u���Ӑ�ʏ��i�ʔ���W�v�\�v�Ɠ��͂���C�i�r�Q�[�^���u�Ώۊ��Ԃ͂����炢�܂łł����v�Ƃ��u���ʏW�v�ł悢�ł����v�Ƃ����悤�Ȏ�������āC������Θb�I�ɖ��m�ɂ���V�X�e���ɂ��ł��悤�B�܂��C�ߋ��̗��p���w�K���邱�Ƃɂ��C�u�K�\�������Ώۂł����v�Ƃ��u���x�X�NJ��ł��ˁv�ȂǂƁC���p�҂ɂ���ďȗ������߂�ς��邱�Ƃ��ł��悤�B
�i�Q�j���^�f�[�^�̈��p���ƃe���v���[�g
��Q�̗Ⴊ���^�f�[�^�̈��p�ƃe���v���[�g�ł���B���t�@�C���`�����H���ĐV�t�@�C���a���쐬�����Ƃ��C�`�̃��^�f�[�^�����a�Ɉ����p���@�\���ق����B���R���̂Ƃ��C���x�X�̃f�[�^�𒊏o�����̂ł���C���Ӑ�┄����̎����ɂ́u���x�X�́v�Ƃ��������g�ݓ���Ăق����̂ł���B
�܂��C�G���h���[�U�͓����悤�ȏ��������邱�Ƃ������B���Ƃ��Δ���t�@�C��������̓t�@�C���Ƃ��Ďw�肵���Ƃ��C�ߋ��ɂ��������͂Ƃ��ď������������e�̈ꗗ�\��\�����āC���̂ǂꂩ���w�����āC�ꕔ��ύX����Ύ��s�ł���悤�ȃe���v���[�g�@�\������ƕ֗��ł���B
�V�D�U�D�Q�@�f�[�^�E�F�A�n�E�X�ƃI�u�W�F�N�g�w��
�i�P�j���^�f�[�^�ƃI�u�W�F�N�g�w��
�I�u�W�F�N�g�w���A�v���[�`�����y���Ă����B���ɂq�c�a���I�u�W�F�N�g�w���f�[�^�x�[�X�̋@�\����荞��ł���B�f�[�^�E�F�A�n�E�X�ɂ��I�u�W�F�N�g�w���̍l����������Ɏ�������邱�Ƃ����҂����B
����̃f�[�^�E�F�A�n�E�X�ł́C�f�[�^�̕��i����ė��p�̖ʂɂ͗L���ł��邪�C�������܂߂����i���E�ė��p�Ɋւ��Ă͂��܂蒍�ڂ��Ă��Ȃ��B��q�̃��^�f�[�^�̈��p���́C�N���X�Ԃł̃C���w���^���X�ł���C�e���v���[�g�̓I�u�W�F�N�g�i�N���X�j�̃G�N�X�e���V�����ł���Ƃ�������B�I�u�W�F�N�g�w���̍l�������̗p���邱�Ƃɂ��C�̌n�����e�Ղɂł���̂ł͂Ȃ��낤���B
�i�Q�j�f�[�^�E�F�A�n�E�X�ƃO���[�v�E�F�A�̓���
��L���̊ϓ_�ł́C�f�[�^�E�F�A�n�E�X���O���[�v�E�F�A�������悤�ȖړI�ł���B�Ƃ��낪�C�O�҂ł̓t�H�[�}�b�g���ꂽ���R�[�h�̉��H��ΏۂƂ��C��҂̓t�@�C���P�ʂł̉��H�����Ȃ��}���`���f�B�A����ΏۂƂ��邱�ƂŁC�Ǝ��ɔ��W���Ă��Ă���B
����ꂵ�����ŗ��p���邱�Ƃ��ł���ƕ֗��ł���B�f�[�^�E�F�A�n�E�X�ɂ��C�}���ɔ����L�����K�\�����X�^���h��������C���̎ʐ^��n�}��������C�����ł̎��ВS���҂Ƃ̏��k�L�^�Ȃǂ����ׂ��肵�����ł��낤�B�܂��C�K�\�����X�^���h���ƊE����ŕ\�����ꂽ�Ƃ̓d�q���[����������C�����̔��㍂�̐��ڂȂǂׂ����ł��낤�B
�I�u�W�F�N�g�w���f�[�^�x�[�X�ł́C���ۃf�[�^�^�Ƃ�������������C���ڂɕs�蒷�̕��͂�}�`���g������C���̃t�@�C���̃A�h���X���w�肵�āC���̃t�@�C����\�������肷��悤�ȋ@�\��������Ă���B����𗘗p���邱�Ƃɂ��C�f�[�^�E�F�A�n�E�X����O���[�v�E�F�A�̏����A�N�Z�X���邱�Ƃ͔�r�I�e�Ղł���B���Ɉꕔ�̏��p�f�[�^�x�[�X�ł͂��̂悤�ȋ@�\����Ă��邪�C�܂��f�[�^�E�F�A�n�E�X�Ƃ��Ă̈ʒu�t���ɂ͂Ȃ��Ă��Ȃ��B
�i�R�j�O���[�v�E�F�A�Ƃ̓����ƃf�[�^�E�F�A�n�E�X�̍\�z
�I�u�W�F�N�g�w���Ƃ͖��W�ł��邪�C���̂悤�ȓ������~���ɂł���悤�ɂȂ�ƁC�f�[�^�E�F�A�n�E�X�̍\�z�E�^�p���e�ՂɂȂ�B
�f�[�^�E�F�A�n�E�X�̍\�z�ł́C�Ƃ������l�ȍ��ڂ���ꂽ����B�K�\�����X�^���h�̗�ł����C�o�c�҂̂��C���Ƃ��C�O�ς����ꂢ���ǂ����Ȃǂ̍��ڂ�����悤�Ƃ���B�Ƃ��낪�^�p����i�ɂȂ�ƁC�R�[�h������̂������ł�������C���ۂɉ��ɂ��Ă悢���킩�炸�C�قƂ�ǂ��u���̑��v�ɂȂ��Ă�����C���N�o���Ă��X�V����Ȃ��܂܂ɂȂ�C���ʂƂ��Ďg���Ȃ��f�[�^�ɂȂ��Ă��܂��B
�����ɃR�[�h������̂ł͂Ȃ��C�����̓O���[�v�E�F�A�I�Ȏ��R�`���ł̕��̓t�@�C���ɂ��Ă����C����Ƃ̃����N�������f�[�^�E�F�A�n�E�X�ɓo�^���Ă��������ŁC���Ȃ���p�ɂȂ�B�����āC�����̍X�V���~���ɂł���悤�ɂȂ����i�K�ŁC���炽�߂ăR�[�h�����l����悢�̂ł���B
�V�D�V�@������
�{�͂ł́C����n�V�X�e����f�[�^�E�F�A�n�E�X����L����n��������Ɍ��ʓI�ł���C���������S���~���ɔ��W�����邽�߂ɂ́C���̂悤�ȔF�����K�v�ł��邱�Ƃ�_�����B
- ����n�V�X�e���͊�Ɩ��n�V�X�e���̕t�ѓI�ȑ��݂ł͂Ȃ��B�ނ������n�V�X�e�������V�X�e���̒��S�I���݂ł���Ƃ��āC����ɐ��m�ȃf�[�^�����̂���Ɩ��n�V�X�e���ł���ƍl����ׂ��ł���B
- ����n�V�X�e���̌�������ł���B�f�[�^���S�A�v���[�`��d�q�o�p�b�P�[�W�ɂ��V�X�e���J���ɂ������ẮC����n�V�X�e�����������邱�Ƃ���ł���B�f�[�^�E�F�A�n�E�X�����悭�^�c���邽�߂ɁC�f�[�^�E�F�A�n�E�X�̌`�ԁC�f�[�^�̎������C�g�D�����◘�p�҂̐S�\���Ȃǂɂ��Ę_�����B
- ���ꂩ��̃f�[�^�E�F�A�n�E�X�ł́C�G���h���[�U�����̋@�\���d�v�ł��邱�ƂƁC�O���[�v�E�F�A�Ƃ̓��������]�܂�邱�Ƃ��������B���Ȃ킿�C����n�V�X�e����f�[�^�E�F�A�n�E�X��_���邱�Ƃ́C���V�X�e���S�̂̂��肩����_���邱�ƂɂȂ�̂ł���B