gauss0
gauss1
スタートページ> JavaScript> 他言語> Python 目次
近年、AIの分野でラージデータやテキストマイニングが注目されていますが、ナイーブベイズ分類器そのような分野での基本的なツールの一つです。ここでは、代表的なモデルの操作を対象にします。
下記の青線の部分をGoogle Colaboratryの「コード」部分にコピーアンドペースト(ペーストは Cntl+V)して実行すれば、右図の画像が表示されます。
ベルヌーイモデルは、特性値が0/1の2値データで、1になる確率はベルヌーイ分布(2項分布)に従う。各特性の間には関連性がないと仮定できる場合に用いられるモデルです。
例えばメールの文面がスパムか、スパムでないかを推定してフィルタリングする基準を設定したいとします。
事前に通常メールとスパムメールを多く収集し、それからメール内に出現する単語(これが特性になる)を列挙して、それぞれのメールにそれらの単語が出現する(1)かしないか(0)のテーブルを作成します。
おそらくスパムメールに多く出現する単語があるでしょう。それを多く含むものがスパムメールだといえそうですが、それを統計的な方法で分析して基準を作ろうとするものです。
10個のメールを収集して20個の単語を得ました。各メールでの出現有無を表(X_train)にして、有識者により、通常A、スパムB、反社会的Cの3つのグループに分類しました(y_train)
(ここでは、確認のために、わざと前半10特性は、グループごとに同じとしました。)
# ====== 入力データ
import numpy as np
# 前半10特性は、グループごとに同じとした
X_train = [[0,0,0,0,0,0,0,0,0,0, 1,0,1,0,0,1,0,0,1,0], # Aグループ
[0,0,0,0,0,0,0,0,0,0, 1,1,1,1,0,0,0,0,1,1], # Aグループ
[0,0,0,0,0,0,0,0,0,0, 0,1,1,1,0,1,0,1,1,1], # Aグループ
[0,0,0,0,0,0,0,0,0,0, 1,0,1,0,1,0,1,0,0,1], # Aグループ
[0,0,0,0,0,1,1,1,1,1, 0,1,1,1,0,1,0,1,1,1], # Bグループ
[0,0,0,0,0,1,1,1,1,1, 1,1,1,1,0,1,0,1,0,0], # Bグループ
[0,0,0,0,0,1,1,1,1,1, 0,1,1,1,0,1,1,1,0,1], # Bグループ
[1,1,1,1,1,1,1,1,1,1, 0,0,1,0,1,0,1,1,0,1], # Cグループ
[1,1,1,1,1,1,1,1,1,1, 0,0,0,0,0,0,0,0,0,0], # Cグループ
[1,1,1,1,1,1,1,1,1,1, 0,1,1,1,0,1,0,1,1,1]] # Cグループ
y_train = np.array(["A","A","A","A","B","B","B","C","C","C"]) # 学習用正解
# ====== BernoulliNB の実行
from sklearn.naive_bayes import BernoulliNB
model = BernoulliNB()
model.fit(X_train, y_train)
# ====== 新データの判定
X_test = [[1,0,0,0,0,0,0,0,0,1, 0,0,1,0,1,0,1,1,0,1]] # 新データ 前半10特性はAグループに似ている
print(model.predict(X_test)) # ['A'] が出力された
# ===== y_train と y_test 全数での一致度の確認
import pandas as pd
y_test = model.predict(X_train)
df = pd.DataFrame()
df["y_train"] = y_train
df["y_test"] = y_test
df.err = ""
df.loc[df.y_train == df.y_test, df.err] = " "
df.loc[df.y_train != df.y_test, df.err] = "X"
print(df)
# y_train y_test ↓errになるものはなかった
# 0 A A
# 1 A A
# 2 A A
# 3 A A
# 4 B B
# 5 B B
# 5 B B
# 7 C C
# 8 C C
# 9 C C
train データをさらに増加し、多数の X_test をして、このモデルの信頼性が確認できたら、model.fit(X_train, y_train) を何からの方法で保存することにより、model.predict を用いてフィルタリングを行うことができます。これは他のモデルでも同じです。
ベルヌーイモデルでは用語が 0:出現しない、1:出現した のように、特性値が 0/1 だけでした。
それに対して、多項分布モデルでは、「出現頻度」のように、特性値は多様な値をとることができます。
# ======= 学習用入力データ
X_train = [[1, 1, 0, 1, 2, 0, 0, 0, 1, 0],
[0, 2, 1, 0, 1, 1, 0, 1, 0, 0],
[1, 0, 0, 3, 0, 0, 1, 0, 1, 0],
[1, 0, 1, 0, 0, 1, 0, 0, 0, 0],
[0, 1, 1, 0, 0, 1, 2, 0, 0, 0],
[1, 0, 0, 1, 0, 1, 1, 2, 0, 1],
[0, 1, 0, 0, 1, 0, 0, 1, 0, 2],
[0, 1, 1, 0, 0, 1, 1, 0, 0, 1]]
y_train = [0, 0, 0, 0, 1, 1, 1, 1]
# ======= MultinomialNB
import numpy as np
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(X_train, y_train) # 学習
# ======= 新文章の推定
print(model.predict([[1, 1, 0, 1, 2, 0, 0, 0, 1, 0]])) # 文章Aと同じ 結果 [0]
print(model.predict([[0, 1, 1, 0, 0, 1, 1, 0, 0, 1]])) # 文章Hと同じ 結果 [1]
print(model.predict([[1, 1, 0, 1, 1, 2, 1, 0, 0, 1]])) # 新文章 結果 [1]
# ===== y_train と y_test 全数での一致度の確認
import pandas as pd
y_test = model.predict(X_train)
df = pd.DataFrame()
df["y_train"] = y_train
df["y_test"] = y_test
df.err = ""
df.loc[df.y_train == df.y_test, df.err] = " "
df.loc[df.y_train != df.y_test, df.err] = "X"
print(df)
# y_train y_test
# 0 0 0
# 1 0 1 X 一致しなかった
# 2 0 0
# 3 0 0
# 4 1 1
# 5 1 1
# 6 1 1
# 7 1 1
上の2つのモデルとは、異なる特性値を対象にします。
ある母集団から標本を選び身長と体重を散布図にしたところ、大きくAとB(おそらく男性と女性)のグループに分かれているようです。誰かの身長と体重を得たとき、男性・女性のいづれであるかを知りたいのです。
身長や体重は連続的な数値データであり、正規分布に従っていると考えられます。GaussianNB はそのような問題を扱います。
ここでは大量データを収集・記述するのが面倒ですので、適当な数値での乱数を発生して用いることにしました。そのため、以下の結果は「たまたま」のもので再現性はありません。
# ====== 入力データ
import numpy as np
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=500, n_features=2, centers=2, cluster_std=2)
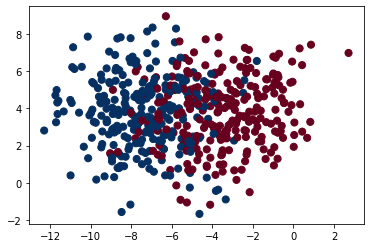
# ====== 元データの散布図
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='RdBu')
# 右上図 gauss0 になりました。 このままでは区分が不明確です。
# ====== train と test の分離
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
# ===== GaussianNB の適用
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X, y)
# GaussianNB(priors=None, var_smoothing=1e-09)
# ====== 各クラスの確率
Y_prob = model.predict_proba(X_test)
print(Y_prob[0:10].round(2)) # 小数点第2位まで表示
# 区分0 区分1 である確率
# [[0.78 0.22]
# [0.36 0.64]
# [0.7 0.3 ]
# [0.65 0.35]
# [0.09 0.91]
# [0.98 0.02]
# [0.28 0.72]
# [0.02 0.98]
# [0.68 0.32]
# [0.82 0.18]]
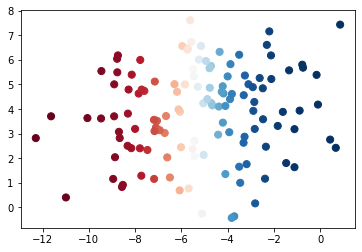
# 2クラスに分離し確率に色をつけた
plt.scatter(X_test[:, 0], X_test[:, 1], c=Y_prob[:, 0], s=50, cmap='RdBu')
# 右下のグラフ gauss1 参照 境界付近が薄い色になっている
# ====== 新データの区分判定(gauss1のX軸とY軸を参照)
# 区分0 区分1 になる確率
model.predict_proba([[-5,-5]]) # 0.333, 0.667
model.predict_proba([[ 0, 0]]) # 0.997, 0.003
model.predict_proba([[-5, 5]]) # 0.623, 0.377
特徴量配列Xは列が特徴量、行がレコードの2次元配列。ターゲットyはレコード数分のクラス属性値の整数になります。
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=100, # 発生個数(Xとyの行数)デフォルトは100。
n_features=2, # 特徴量の数(身長、体重などXの列数)デフォルトは2
centers=2, # クラスター中心の数(塊の数)幾つのグループに分けるか
cluster_std=1.5) # クラスタの標準偏差
通常はすべて省略形でよいでしょう。
import matplotlib.pyplot as plt
plt.figure(
figsize=c(x,y) # Figureのサイズ。横縦を(float, float)で指定。
dpi # 解像度 dpi。整数で指定。
facecolor # 図の背景色。Jupyterだと透過色になってたりする。
linewidth # 外枠の太さ。デフォルトは0(枠なし)。
edgecolor # 枠の色。linewidthを指定しないと意味ない。
subplotpars # AxesSubplotの基準を指定する。
tight_layout # Trueにするとオブジェクトの配置が自動調整される。
constrained_layout # Trueにするとオブジェクトの配置が自動調整される。
X_train, X_test, y_train, y_test =
train_test_split(X, y, # XだけだとX_train, X_testに、yだけだとytrain, y_testに分割
test_size=0.25, # 全体の25%をtest用にする。test_size=50 のように個数指定でもよい
shuffle=True) # その26%をシャッフルして選ぶ。指定しなければ先頭から25%を選ぶ
この関数自体のパラメータに関しては、私が理解できないので省略します。多くの事例でも指定しているのは稀のようです。
fit(X, y) # ガウスナイーブベイズにより y = f(X) の関係を求めます
model.predict_proba(X_test) # 逆にその関係に X_test を与えたときの結果(どの区分に属するかの確率)を計算します。
# その確率が高い区分に属するのですが、それと教育用の区分 y_train との比較をします。
# 一致率の大小によりモデルの信頼度が得られます。