記憶階層
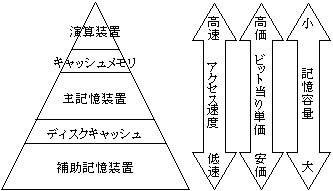
コンピュータの能力を向上するには,CPUやすべての記憶装置に高速のものを用いればよいのですが,大量のデータを保管するには大きな記憶容量が必要ですから,膨大な費用がかかってしまいます。それで,高価だが高速な小容量の記憶装置と,低速だが安価な大容量の記憶装置を組み合わせることが必要になります。これを記憶階層といいます。
しかし,CPU-メモリ-ディスクをそのままつないだのでは,それらの間の処理速度に大きなギャップがあります。メモリからCPUに取り出して処理をする時間やディスクからデータを読み込んでメモリに入れる時間で空き時間が生じてしまいます。それを防ぐために,キャッシュメモリやディスクキャッシュを設置します。これらを総称して緩衝記憶装置(バッファメモリ)といいます。
ディスクキャッシュとは、メモリとディスク間に置くキャッシュで,考え方はキャッシュメモリと同じです。個々のディスク装置あるいはディスク制御装置に半導体記憶装置を置き,必要なデータがここにあれば,いちいちディスクを読みに行かないでデータが得られるようにしたものです。ライトバッファともいいます。
アクセス時間の短い順に並べると概念的には右図のようになります。しかし、詳細には技術進歩により、単純な比較はできなくなってきました。
近年はSSDが普及してきました。半導体素子のフラッシュメモリを用いているので、HDDよりもはるかに高速でディスクキャッシュと同等の高速アクセスが実現します。
通常は記憶階層では内蔵機器を対象にしますが、外部記憶装置も対象にするときには、装置の速度がパソコンとの接続機器で制約されることがあります。外付けのHDDはUSB接続が一般的になっていますが、従来のUSB2.0をUSB3.0に変えるだけで数倍の速度になります。
- アクセスの局部性
- 常識的に考えて,あるデータやプログラムのある部分をアクセスすれば,次にはその近くにあるデータやプログラムがアクセスされる確率が大きいと思われます。それをアクセスの局部性といいます。
- キャッシュメモリ
- CPUとメモリの間にキャッシュメモリという高速のSRAMのメモリを設置し,CPUからの命令によりメモリからCPUにデータを読み込むときに,その付近のデータもキャッシュメモリに転送しておきます。次にCPUから取り出し命令があったときは,まずキャッシュメモリを調べてそこにあればそのデータをCPUに取り出します。
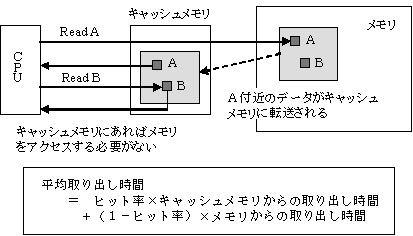
- ヒット率
- 必要なデータがキャッシュメモリにあることをヒットしたといい、その確率をヒット率といいます。もし,メモリからの取り出し時間が50ns,キャッシュメモリからの取り出し時間を10nsであり,ヒット率0.9であるとすれば,平均取り出し時間は,
10×0.9+50×(1-0.9)=14ns
になります。
キャッシュメモリの容量を大きくすればヒット率が大きくなり、処理速度が向上しますが、高速素子数が増えるので高価になります。 - ミスペナルティ
- 必要なデータがキャッシュメモリになかったことをヒットミスあるいはキャッシュミスといい、その確率をミス率といいます。
ミス率=1-ヒット率
の関係があります。ミスが発生すると、メモリからキャッシュメモリへの移動が行われます。さらに、詳細は省略しますが、キャッシュレジスタ管理情報の入れ替えなどの作業が発生します。それによるCPUの負荷損失をミスペナルティといいます。
これを考慮すると、平均アクセス時間は、
平均アクセス時間=ヒット率×キャッシュメモリへのアクセス時間
+ミス率×(メモリへのアクセス時間+ミスペナルティ関連時間)
となります。
なお、OSはミスペナルティの作業時間を低減する工夫をしています。 - コンパクション
- データがメモリ内の連続した領域にあれば、ヒット率が高くなります。メモリ内に分散している領域を一か所にまとめる処理をコンパクションといいます。
- 1次キャッシュと2次キャッシュ
- 最近のパソコンでは,キャッシュメモリを2段階に用意しています。CPUから近い順に1次キャッシュ,2次キャッシュといいます。一般には1次キャッシュを内部キャッシュとして1~16KB程度のメモリをCPU内部に内蔵し,2次キャッシュを外部キャッシュとしてCPU外部に64KB~1MB程度のSRAMを実装しています。
- キャッシュライン
- メモリからキャッシュに持ってくるデータの単位をキャッシュラインといいます。すなわち、キャッシュメモリには多数のキャッシュラインが存在します。
キャッシュラインのサイズが小さいとヒット率が小さく、メモリからキャッシュへの転送頻度が増大してキャッシュの効率が悪くなります。逆に大きすぎると、使われない部分が多くなるし、ライン数が少なくなり、キャッシュメモリの容量が非効率になります。32バイト~256バイト程度が一般的です。32バイト~256バイト程度が一般的です。 - ライトスルー方式とライトバック方式
- 書き込み処理をしたときは、キャッシュメモリのデータをメモリに書き出す必要があります。
- ライトスルー方式
CPUからの書込命令により、キャッシュメモリと同時にメモリにも書き込む方式です。
キャッシュメモリの内容とメモリの内容が常に一致するので、その間の一貫性(コヒーレンシー)が保持されます。ライトバック方式の書き戻し処理の必要もありません。
しかし、毎回メモリにアクセスするので、書込処理ではキャッシュメモリを設置する効果がないばかりか、かえって非効率になります。 - ライトバック方式
CPUからの書込命令ではキャッシュメモリだけに書き込みます。そして、メモリからキャッシュメモリへ新しい部分が転送される直前、すなわちキャッシュメモリから現在のデータが追い出される直前に、まとめてキャッシュメモリからメモリに転送して更新します。
この方式ならば、書込命令でもキャッシュメモリの効果が得られます。
しかし、一時的にキャッシュメモリとメモリの内容が異なる状態になります。そのため、一貫性を保持するための制御が複雑になります。
特に、キャッシュミスが発生するたびにキャッシュメモリ→メモリの書き戻し処理が必要になります。
このような理由により、個々のプロセッサがそれぞれのキャッシュをもつマルチプロセッサシステムには不向きです。
- ライトスルー方式