1 プログラムからの独立
(1)ファイルデザインとプログラムの分離
プログラマは,通常のファイルについては,プログラムで項目をいちいち定義しなければならないのので,ファイルデザインを知っている必要があります。それに対してデータベースでは,データの構造をデータベースが定義しているので,プログラマは項目名だけを知っていればよいのです。
通常のファイルでのファイル定義
通常のファイルは下図のような形式になっています。ファイルに入っているものはデータだけであり,「月日」や「得意先コード」などの項目名はファイルには含まれていません。さらに,物理的にはファイルの中では,項目間の区切りやレコードとレコードの間の区切りもありません。しかも,実際にはバイナリ表示になっているので,これよりさらに複雑になっています。
1001500コダマ電器101目立テレビ10テレビ10401001500コダマ電器205HALパソコン20パソコン202001001500コダマ電器326松川ケータイ30ケータイ10101004600リラックス213MDBパソコン20パソコン30180・・・・
それで,プログラムでどこからどこまでを何という項目名で取扱うのかを定義する必要があります。下はCOBOL言語でのファイル定義文ですが,プログラマは個々のプログラムでこのような定義をしなければならなかったのです。
FD 売上ファイル.
01 売上レコード.
02 月日 PICTURE 9(4).
02 得意先コード PICTURE 9(3).
02 得意先名 PICTURE N(5).
02 商品コード PICTURE 9(3).
02 商品名 PICTURE N(7).
02 商品区分コード PICTURE 9(2).
02 商品区分名 PICTURE N(4).
02 個数 PICTURE S9(3) COMPUTATIONAL.
02 金額 PICTURE S9(9) COMPUTATIONAL.
これでは,次のような問題点が発生します。
- プログラマは項目名を勝手につけることができる。これは,便利なようだが,他人がプログラムを読むときに,非常にわかりにくくなる。
- 個々のプログラムでにそのファイルデザインを定義しているのだから,このファイルに「支店」項目を追加するとか,「金額」の桁数を変更するなどファイルデザインを変更したときには,このファイルデザインを使っているプログラム全部を修正しなければならない。
データベースの場合
データベースをアクセスするにはSQL言語が用いられますが,それでは下図のような記述ができます。ここでは,「得意先名」や「商品名」「数量」などの項目名はDBMSで定義されているので,プログラマはファイルデザインを知る必要はないのです。
SELECT 得意先名,商品名,数量 FROM 売上ファイル WHERE 月日="1001";
個々のプログラムでは,そこで必要とする項目名だけを使っているのだから,後になってファイルデザインが変更になっても,プログラムを修正する必要はない。すなわち,データベースでのデータをプログラムから独立して管理できるのである。
データ中心アプローチ
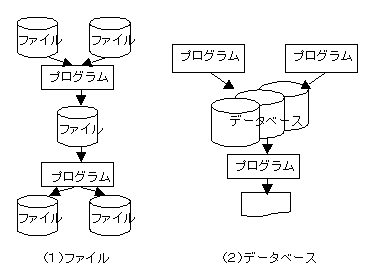
通常のファイルでは,下の左図のように,プログラムの入出力としてファイルを考えていました。いうなれば,ファイルはプログラムに付随した位置づけだったのです。
ところが,システムの保守改訂を容易にするためには,右図のように,データベースを中心にして,そのデータベースを創成・更新したり,データベースから情報を取り出すのがプログラムであると考えることができます。このような考え方をデータ中心アプローチ (DOA:Data Oriented Approach)といいます。これが現在でのシステム開発での基本的なアプローチになっています。
これは,データを部品と考えることでもあります。すなわち,データベースとはデータを部品として再利用することを目的としているともいえます。
(2)冗長性の排除
データベースにするにあたり,データの正規化をすることが必要になります。正規化すると,全体としてのデータ量が少なくなり,ディスクなどの記憶装置のコストを少なくすることができます。
それだけでなく,一つの項目は一つの場所にしか存在しなくなるので,データの管理が容易になります。たとえば,得意先名が多くのファイルに存在するとき,その名称が変更になったとしたら,どのファイルに該当する得意先があるのかを調べて,それを間違いなく修正しなければならなりません。これは大変な作業になるし,修正もれを完全になくすことは困難です。それに対して,正規化されていれば,得意先名は得意先マスタにしか存在しないので,得意先マスタを修正するだけで,すべてのシステムについて,間違いなく修正できたことになります。
排他制御□
ここでは、排他制御をデータベースから説明しましたが、OSのタスク機能としてとらえることもできます。→参照:「OS:排他制御」
過去問題:「排他制御」( haita-seigyo)
安全性の確保
機密保護
データベースに蓄えられているデータのなかには,特定の人以外には秘密にするべきデータもあります。通常のファイルでもファイル単位にユーザIDやパスワードにより,
読み書き両方ができる
読むことはできるが書くこと(更新)はできない
読み書き両方ともできない
に分けてアクセス制御することができますが,さらにデータベースでは,DBMSが独自に
列(項目)単位,行(レコード)単位でのアクセス制御できる
アクセス資格を多様なグループ分けにして指定できる
など,きめの細かい機密保護ができるようになっています。
障害回復(リカバリ)
万一のトラブルによりデータの整合性を失ったとき,データベースを回復する機能がある。データベースを更新するとき,更新件数や時間などによりチェックポイントを設定しておき,チェックポイントになると,次のチェックポイントに達するまで,更新前と更新後の情報をログというファイルに記録しておく。チェックポイント間でトラブルが発生したときは,ログファイルを用いてデータベースの内容を直前のチェックポイントの状態に回復する。
インデクス
通常のファイルでの問題点
ソート処理
通常のファイル(順編成ファイル)では,レコードは固定された順に記憶されており,それを処理するには先頭から順に読む必要があります。それで,得意先別で集計するには,レコードが得意先コードの順に並んでいることが必要だし,商品別に集計するには商品コードの順で並んでいる必要があります。このように,レコードをある項目の順に並べ替えることをソート処理といいます。事務処理ではソート処理が非常に多いし,しかも,レコード数が大きいときには,ソート処理はかなり時間のかかる処理となります。
照合処理
得意先名や商品名を付けた商品別得意先別売上集計表を出力するには,売上ファイルと得意先マスタや商品マスタを突き合わせる必要があります。このような処理を照合処理といいます。照合をするのに,売上ファイルの1レコードを読むたびに,売上ファイルの商品コードと同じ値を持つ商品マスタのレコードを探すために,商品マスタを先頭から読むのでは,あまりにも非効率です。それを解決するために,商品マスタでは,商品コードを与えたらそのレコードが直接に取り出せるようにするランダムアクセス方式になっているのが通常です。そのランダムにアクセスできるのがインデクスなのです。
インデクスの概念
上記のような工夫がインデクスであり,データベースでは多様なインデクスが付けられるようになっています。なお,ここではインデクスの考え方を示すのが目的ですので,厳密な説明にはなっていません。
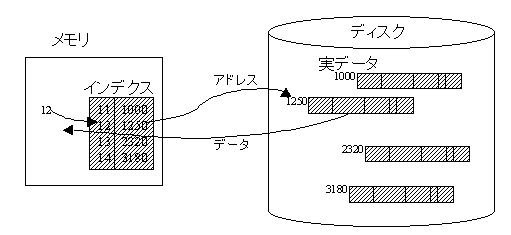
ある条件に合致したレコードを探すときに,テーブルの先頭から順に探したのでは時間がかかりますので,該当データを直接に探す手段が必要になります。これを実現するには,商品マスタはディスクに保管してあるが,その保管場所(アドレス)と商品コードの対比表を作り,その対比表をメモリに入れておき,対比表を調べることにより,商品コード(12)に対応する保管場所(1250番地)を知り,ディスクの1250番地を直接にアクセスすればよいでしょう。補助記憶装置であるディスクから読み込む時間にくらべて,内部記憶装置であるメモリ内の処理時間は数百倍速いので,このような複雑な処理をしても,このほうが処理速度が向上するのです。このような対比表をインデクスといいます。
インデクスの種類
インデクスの種類は多いが,キー項目の値の種類が多いときの代表的なものとしてB-treeインデクス,少ないときの代表としてビットマップインデクスがあります。
B-treeインデクス
通常のRDBでのインデクスでは,B-tree型のインデクスが広く利用されています。これは,図のように,キーとなる項目の値の大小関係により,2分木をたどって求める項目要素を探し出す方法です。キーとなる項目が「商品」などキーの値が多く(図3-2では11個であるが,実際には数千にもなる),一つの値(681)についてのデータの個数(ここでは,3480と5190の2つ)が少ないときは,B-treeは効果的です。
たとえば,681のコードに対応するアドレス3480と5190を求めるには,次のようなプロセスになります。
- 681と先頭のキーである512とを比較する。512よりも大きいから右へ行く。
- 735と比較すると小さいので左へ行く。
- 643と比較すると大きいので右に行く。
- ここで一致したので,3480と5190の2つであることがわかる。

ビットマップインデクス
B-treeインデクスは,「性別」や「支店」のようにキーがとる値が少ない(性別では,男=0,女=1の2つしかない)ときには,深さがなく,同一のキーについてデータ個数が非常に多いので,ほとんど役に立ちません。
このような場合に効果的なのが,ビットマップによるインデクスです。男か女かを示すには1ビットあればよく,支店数が8ならば8=23であるから3ビットでよい。データの数が8百万件あっても,性別の表は8MBですむことになります。この程度であれば,全部をメモリに入れることができるので,比較回数は多くなっても処理に要する時間は非常に短くなります。
インデクスと更新処理
多様な検索を効率的に行うには,検索の対象となる項目のすべてにインデクスをつけておくのがよいのですが,しかし,更新処理のときでは,インデクスが効果がある場合と逆効果になる場合があります。
商品マスタがシークェンシャルファイルのときは,新商品が発生して新しい商品レコードを追加するときには,1件を追加するだけでも,旧商品マスタをすべて読み込んで新商品マスタに書き出す必要があります。それに対して,商品コードでのインデクスがあるときには,インデクス表での挿入すべき箇所を探して,そこに書き込めばよいのですから,この場合には非常に効率がよくなることが理解できます。
ところが,商品マスタに商品区分など多くの項目がありそれらの項目にインデクスがついていると,追加をしたとき,それらのインデクスも変更しなければならないので,インデクスの個数が多いと更新処理の効率が悪くなってしまいます。基幹系システムでは大量のデータが発生し,それを短時間で処理すること(そのような処理をOLTP(OnLine Transaction Processing)という)が要求されます。そのために,OLTPで用いるファイルでは。更新に必要なインデクスだけをつけて,他の項目にはインデクスをつけないほうが効率的なのです。