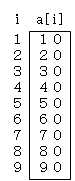
サーチ(探索)とは、右図のような配列aがあるとき、与えた値xと同じ値をもつ要素a[i]を探し、その要素番号を求める操作です。
例えば、x=50ならばi=5となります。また、x=35のときは一致する要素が存在しないことになります。
a[i]の学籍番号に対応した学生氏名をb[i]に入れておきます。学籍番号xを与えて、配列aから一致した要素のiを知ることにより、その学生氏名b[i]を得るというような操作は、事務処理のプログラムでよく用いられる操作です。技術計算の分野では、数表を検索することはよく用いられる操作です。
ここでは、ポピュラーなサーチのアルゴリズムであるリニアサーチ(順次探索法)、バイナリサーチ(二分探索法)について説明します。
リニアサーチ(順次探索法)

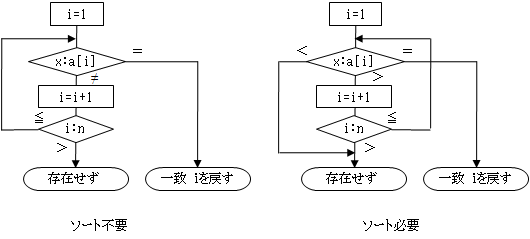
リニアサーチとは、右図のように、a[1]から順にa[2]、a[3]、・・・と探していく方法です。この場合には、配列aの要素はソートされている(小さい順に並べられている)必要はありません。
このときの流れ図は、下左図になります。
よく検索される要素を先頭に配置しておけば、検索での比較回数が少なくなります。
しかし、一致する要素が存在しない場合には、最後まで探索しなければならず比較回数が大きくなります。
それに対して、配列が事前に昇順にソートしてあれば、x>a[i]になったときに、存在しないことがわかります。ソートされているときの流れ図を下右図に示します。
どちらの場合も、サーチする値xの出現にばらつきがないならば、xとa[i]の平均比較回数は(ソートされていない場合での非存在のケースを無視すれば)、n/2回になります。
配列を事前にソートしておくかどうかは、探索する値の特徴によります。
探索の値の大部分が少数の場合は、それを配列の先頭に配置すれば、比較回数が小さくなるので、事前ソートしないほうが高速になります。
非存在(配列に存在しない)の探索が多い場合、事前にソートされていないと、配列の最後まで探索しないと非存在であることがわかりません。
バイナリサーチ(二分探索法)
バイナリサーチは、配列aが事前にソートされている場合に、比較回数を少なくできるアルゴリズムです。
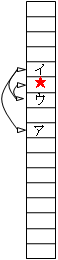
右図のように、比較のたびに、探索領域を半分にしていくのが特徴です。その流れ図を示します。
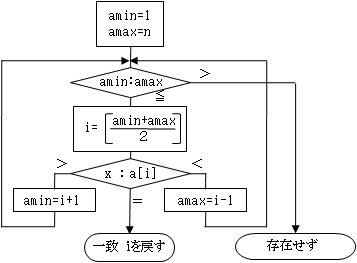
- amin=1、amax=nとします。amin~amaxが探索範囲です。
- 通常は amin≦amax のはずです。そうでなくなったときには、一致する要素が存在しなかったことになります(その説明は省略)。
- aminとamaxの中点i=(amin+amax)/2を計算して、xとa[i]を比較します(右図のアの要素になります)。
一致したならば、このiが求めるものですから、処理を終わります。
- x<a[i] ならば、一致する要素はiよりも小さい(上にある)のですから、amax=i-1 として、2に戻ります(右図では、2回目にイの要素になります)。
x>a[i] ならば、一致する要素はiよりも大きい(下にある)のですから、amin=i+1 として、2に戻ります(右図では、3回目にウの要素になります)。
右図でのア→イ→ウ→・・・のように探索範囲を半分にしながら探索していく間に、3でx=[i] となるか、2で amin>amax となり、処理が終わります。
1回の比較で、探索範囲が半分になるということは、探索を1回増やせば、探索範囲を2倍にすることができるということです。探索回数をmとすれば、2m=n、すなわち、m=log2nの関係があります。
バイナリサーチは、リニアサーチと比較して、一般的に高速ですが、リニアサーチのほうが高速な場合があります。
- 探索配列が極端に小さい場合
バイナリサーチは比較回数は小さいのですが、処理が複雑で、しかも計算時間のかかる割り算があります。そのため、極端に少ない配列を探索する場合はリニアサーチのほうが高速なことがあります。 - 探索値に大きなばらつきがある場合
配列が大きいのに、探索される値が非常に偏っているとき、探索頻度の多いものを配列の先頭に配置しておけば、比較回数が小さくなります。
バイナリサーチのトレース
配列aには、n=8個の要素が、次のように入っているとします。
i 1 2 3 4 5 6 7 8
a[i] 10 20 30 40 50 60 70 80
x=50 のとき
初期値:amin=1、amax=8
1回目:i=(amin+amax)/2=(1+8)/2=4.5→小数点以下切り捨てで、i=4
a[4]=40<x なので、amin=i+1=5
2回目:i=(5+8)/2=6.5→i=6
a[6]=60>x → amax=i-1=5
3回目:i=(5+5)/2=5
a[5]=50=x → 一致した
x=35 のとき
初期値:amin=1、amax=8
1回目:i=(1+8)/2=4.5→i=4
a[4]=40>x なので、amax=i-1=3
2回目:i=(1+3)/2=2
a[2]=20<x → amin=i+1=3
3回目:i=(3+3)/2=3
a[3]=30<x → amin=i+1=4
amin=4>amax=3 となり「存在せず」になります。
先に示した文章によるアルゴリズムの説明は不十分です。どうしてどうして2で amin≦amax の条件にするのか、どうして4では amax=i-1 でなければならず、amax=i ではだめなのかなどが疑問になります。
●amin<amax としたとき(x=10 の指定で「存在せず」になってしまう)
初期値:amin=1、amax=8
1回目:i=(1+8)/2=4.5→i=4
a[4]=40>x なので、amax=i-1=3
2回目:i=(1+3)/2=2
a[2]=20>x → amax=i-1=1
ここで、amin(=1)=amax(=1) となり打ち切られ、「存在せず」になってしまいます。
●amin=i, amax=i としたとき(x=35 の指定で「無限ループ」になってしまう)
初期値:amin=1、amax=8
1回目:i=(1+8)/2=4.5→i=4
a[4]=40>x なので、amax=i=4
2回目:i=(1+4)/2=2.5→i=2
a[2]=20<x →amin=i=2
3回目:i=(2+4)/2=3
a[3]=30<x → amin=i=3
4回目:i=(3+4)/2=3.5→i=3
a[3]=30<x → amin=i=3
5回目:i=(3+4)/2=3.5→i=3
a[3]=30<x → amin=i=3
:
となり、これが無限に繰り返されます。
ハッシュサーチ
ハッシュサーチとは、直接編成ファイル(ハッシュファイル)から、与えたキー項目の値をもつレコードを検索することです。
ハッシュファイルでは、キー項目の値をハッシュ関数により変換したハッシュ値をアドレスにして格納されています。ですから、ハッシュ関数により与えたキー項目の値を計算したハッシュ値を用いて1回の検索ですみます。計算量オーダーは O(1) になります。
バイナリサーチの計算プログラム
正しいアルゴリズム(パターン0)と、あえて誤りのアルゴリズム(パターン1、2)によるプログラムを掲げます。経過が表示されますので、いろいろなケースを与えて、実験してください。