アルゴリズムでの基本的手法の一つに再帰(recursive)があります。再帰とは、Aというものを定義するとき、Aの定義のなかでA自体を含むことをいいます。プログラムでいえば、ある関数Aのなかで、関数Aを呼び出しているとき、再帰プログラム(再帰関数)といいます。
再帰プログラムの説明-階乗を例にして
- 再帰の説明
-
再帰関数の典型的な例が階乗関数です。階乗とは、
F(n)=n!=1×2×3×…×n ・・・ア
のことですが、
n!=(1×2×3×…×(n-1))×n
=n×(n-1)!
ですから、
┌1 (n=0のとき)
F(n)=│ ・・・イ
└n×F(n-1) (n≧1のとき)
と再帰的に定義することができます。 - プログラム
-
アによるプログラムは
function f(n);
if (n==0) return 1;
fact = 1;
for (i=1; i<=n; i++) {
fact = fact * i;
}
return fact;
}
となりますが、イのように再帰を用いると
function f(n);
if (n==0) return 1;
else return n * f(n-1);
}
となります。 - 再帰とスタック
- 再帰を配列に入れながら処理をする場合、スタックあるいはLIFO(後入先出)配列を用いるのが適切です。階乗関数 f(3) の計算では次のようになります。
│f(3)││f(2)││f(1)││F(0)=1│ │1x1=1 ││1x2=2 ││2x3=6 │
└──┘├──┤├──┤├───┤ ├───┤├───┤└───┘
│ 3 ││ 2 ││ 1 │ │ 2 ││ 3 │
└──┘├──┤├───┤ ├───┤└───┘
│ 3 ││ 2 │ │ 3 │
└──┘├───┤ └───┘
│ 3 │
└───┘
────── push ───────→ ────── pop ─────→ - 再帰の利点と欠点
-
再帰は、「n-1までが正しいと仮定したら、nの場合も正しいことを証明すれば、すべてのときに正しいといえる」という数学的帰納法と似た考え方です。nでの問題をn-1での結果を用いて解くアルゴリズムを考えればよいのです。
そのため、再帰アルゴリズムを用いることには、次のような利点があります。
・アルゴリズムを発見しやすくなる。
→プログラムが作りやすい。
・一般に、アルゴリズムが簡素になる。
→プログラムの誤りが少なくなる。
他人が読んでわかりやすいプログラムになる。
このような利点を実感するために、代表例として、「ソート」と「ハノイの塔」を後述します。しかし、プログラムが簡潔であることは、必ずしも実行効率がよいことではありません。イのプログラムで f(5) をを実行するには、f(4),f(3),…,f(3) を実行しなければないません。関数を呼び出す回数が増加しますし、それらの結果を保存しておく必要があります。処理のための時間やメモリ容量は、むしろ増大してしまいます。その代表的な例として「フィボナッチ数列」を後述します。
ソート
ソート(整列)とは、データを小さい順あるいは大きい順に並べ替えることです。多様な方法があります(「ソートの種類」参照)が、ここでは、それらを知らなくても、再帰の考え方を用いると、比較的容易にプログラムを作ることができることを説明します。
- アルゴリズム
-
配列aを小さい順にソートすることを考えます。これまでに、n-1個までは既にソートされているとき、要素a[n] について考えます。
1 2 3 n-1 n
┌──┬──┬──┬──┬──┐┌──┐
│10│20│40│50│60││a[i]│
└──┴──┴──┴──┴──┘└──┘次のようにすればよいことは、容易に気づくでしょう。
a[n]=80のように、a[n-1] ≧ a[n] の場合は、nも含めてソートされているので、何もしなくてよいことになります。
a[n]=30のように、a[n-1] < a[n] の場合は、下図の操作を行ないます。
1 2 3 n-1 n
┌──┬──┬──┬──┬──┐┌──┐
│10│20│40│50│60││30├┐
└──┴──┴─┬┴─┬┴─┬┘└──┘│①
② └┐ └┐ └┐ │
1 2 i=3 │ ③│ │n ┌┴┐
┌──┬──┐┌──┐┌┴─┬┴─┬┴─┐ │w│
│10│20││30││40│50│60│ └┬┘
└──┴──┘└─┬┘└──┴──┴──┘ │
④└─────────────┘- a[n] の値30を一時的にwに保管しておきます。
- 配列の先頭から順にa[i] ≧a[n] の間iをずらしていき、a[i] <a[n] となる個所iを見つけます。(図ではi=3)
- 要素i~n-1を右に1つずらして、i+1~nに入れます。このとき右のほうからずらさないと、データが消えてしまいます。
- a[n] の値を保管していたwの値を a[i] に入れます。
- プログラム
- 上のアルゴリズムをプログラムにするのは容易です。
function sort(n) {
if (n==1) return;
sort(n-1); ──再帰:n-1までがソートされていると仮定
w = a[n]; ①
if (w <= a[n-1]) { ──a[n-1] < a[n] の場合だけを考えればよい
i = 1;
while((i < n) && (a[i] <= w)) i++; ②
for (j=n-1; j>=i; j--) a[j+1] = a[j]; ③
a[i] = w; ④
}
}
ハノイの塔
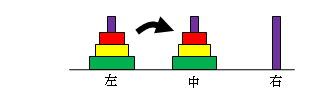
かなり難解な問題が再帰を用いることにより、非常に簡単になる例として、「ハノイの塔」があります。
図のように、右の棒にn枚の円盤が積んであります。
・1回に1枚の円盤しか動かせない。
・小さい円板の上に大きい方の円盤を置いてはならない。
の規則に従って,円盤をAからBに移動せよという問題です。
- プログラム
- 再帰を用いたプログラムは非常に簡単です。
ここでは円盤の小さい順に円盤番号nをつけています。
function hanoi(n, a, b, c) {
if (n==0) return;
hanoi(n-1, a, c, b);
document.write("円盤" + n + ": " + a + " → " + b + "<br />");
hanoi(n-1, c, b, a);
} - トレース
-
「hanoi(4, "左", "中", "右")」を実行した結果を示します。
ア 円板1: 左 → 右
イ 円板2: 左 → 中
ウ 円板1: 右 → 中
エ 円板3: 左 → 右
オ 円板1: 中 → 左
カ 円板2: 中 → 右
キ 円板1: 左 → 右
ク 円板4: 左 → 中
ケ 円板1: 右 → 中 ─┐
コ 円板2: 右 → 左 │
サ 円板1: 中 → 左 │
シ 円板3: 右 → 中 │n=3
ス 円板1: 左 → 右 ─┐ │
セ 円板2: 左 → 中 │n=2 │
ソ 円板1: 右 → 中 ─┘ ─┘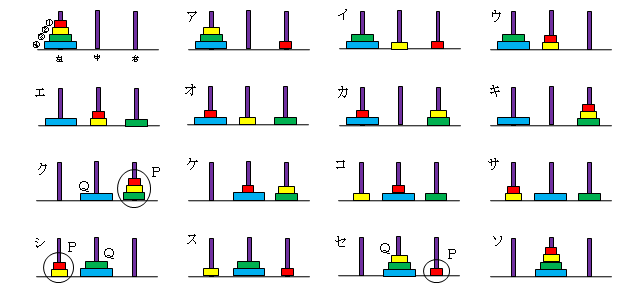
- アルゴリズム
-
円盤がn個あるとき、1~n-1の円盤を一つの円盤であるとして、1~n-1の円盤をP、n番目の円盤をQとすれば、2個の円盤を移動することだと考えることができます。
2つの円盤PとQがaの棒にあるとして、それをbの棒に正しく移動するには、次の3つの操作を行えばよいことは明白です(左中右などの物理的意味を排除するために、あえてa,b,cとします)。
操作1:PをAからCへ移動
操作2:QをAからBへ移動
操作3:PをCからBへ移動hanoi(m, a, b, c) とは、aからbへ移動することだと定義すれば、document.write(~)がそれにあたります。
そして、Pの移動とはn-1のときの移動のことですから、
操作1:hanoi(n-1, a, c, b);
操作3:hanoi(n-1, c, b, a);
となります。トレースでのクでは、円盤4(Q)が既に中に置かれているとすれば、3つの円盤(P)を移動させることであり、ク以降の操作は、円盤数nが3のときの問題を解くことだといえます。同様にシ以降はn=2、セ以降はn=1を解くための操作になっています。
ハノイの塔の問題を、再帰の概念を使わずにアルゴリズムを考えるのは、かなりの難問でしょう。それが、再帰の概念により、n個の円盤の問題を、n-1個の問題にすることができ、結局は2個の円盤での問題にすることができ、上掲のようなきわめて簡単なアルゴリズムにすることができるのです。
フィボナッチ数列
再帰による処理効率の低下の例(再帰を使うべきではない例)として有名なのがフィボナッチ数列です。フィボナッチ数列とは、
1,1,2,3,5,8,13,21,…
の数列で、1+1=2,1+2=3,2+3=5のように、直近の2つの数を加えたものです。それで、
┌1 (n=1のとき)
F(n)=│1 (n=2のとき)
└F(n-1) + F(n-2) (n≧3のとき)
と定義できます。
- プログラム
-
再帰を用いないならば、1つ前の数をx1,2つ前の数をx2として、プログラムf1にすることができます。
function f1(n);
if (n<=2) return 1;
x1 = 1; x2 = 1;
for (i=3; i<=n; i++) {
x = x1 + x2;
x2 = x1;
x1 = x;
}
return x;
}
となります。再帰を用いたプログラムf2は、
function f2(n);
if (n<=2) return 1;
else return f2(n-1) + f2(n-2);
}
となります。 - 計算量の比較
-
計算量を forループ のなかの3つで代表させるならば、f1での計算回数は、3n回です。
それに対してf2の計算回数は、ほぼフィボナッチ数列での値と同じ程度の回数になります。
nが大きい場合、例えばn=30のときでは、f2ならば90回なのに、f1では(n=30のフィボナッチ数は)832,040回になってしまいます。