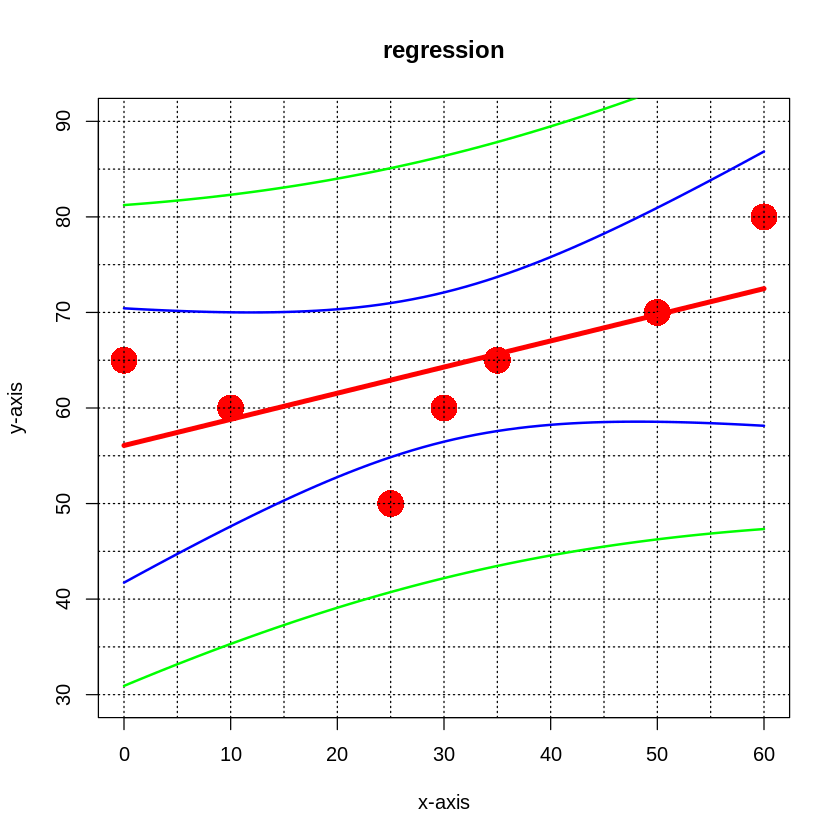
(x,y)の相関係数= 0.6167
回帰式: y= 56.078 + 0.2735 *x
決定係数 r2= 0.3803, 相関係数 r= 0.6167
p値= 0.140152
スタートページ> JavaScript> 他言語> R言語
下記の青線の部分をGoogle Colaboratryの「コード」部分にコピーアンドペースト(ペーストは Cntl+V)して実行すれば、右図の画像が表示されます。
lm関数は、線形モデル(LinearModel)の分野での代表的関数です。基本的には説明変数、被説明変数が量的データで、主に回帰分析や重回帰分析に利用されます。
y = a + bx + ε (ε は誤差項)の形式でεを小さくすることを目的にしますが、εは正規分布に従うことが仮定されています。
εが任意の分布であるとき、説明変数に量的データを含む場合、被説明変数が2値の場合などでは、glm 関数(Generalized linear model、一般化線形モデル)を用います。
関数の一般形
lm(formula, // 必須。モデルの形式
data, // 必須。分析のためのデータ
method = "qr",
...)
formula
y~x y = a + bx + ε (ε は誤差項)
y~x-1 y = bx + ε (定数項を除外)
y~x1+x2 y = a + b1x1 + b2x2 + ε
y~1+x+I(x^2) y = b0 + b1x1 + b2x2 + ε
y~x1+x2+x1*x2 y = a + b1x1 + b2x2 + b3x1x2 + ε
data ベクトルで与える
x1 <- c( 0, 10, 25, 30, 35, 50, 60)
y <- c( 65, 60, 50, 60, 65, 70, 80)
一般形式
結果 <- lm(formula, data)
summary(結果)
主な戻り値 詳細は後述の実例説明参照
summary(結果) 回帰分析の結果一覧
print(結果) 簡略版を表示.
coefficients(kekka) 回帰係数 (a, b1, b2 )
deviance(結果) 重みつけられた残差平方和.
plot(結果) 残差,当てはめ値などの 4 種類のプロットを生成.
predict(結果, newdata) newdata を回帰式に当てはめた結果
(x,y) の組から 散布図 相関係数 r 回帰直線 y = a + bx の算出と表示 信頼区間曲線の表示 を行います。
(x,y)の相関係数= 0.6167
回帰式: y= 56.078 + 0.2735 *x
決定係数 r2= 0.3803, 相関係数 r= 0.6167
p値= 0.140152
x <- c( 0, 10, 25, 30, 35, 50, 60)
y <- c( 65, 60, 50, 60, 65, 70, 80)
xmin <- 0; xmax <- 60
ymin <- 30; ymax <- 90 # 区間図がスケートアウトしないように広く設定
# ===== 散布図の作成
plot(x,y, # plot のオプション指定
xlim=c(xmin, xmax), ylim=c(ymin,ymax), # 表示範囲
pch=16, col="red", cex=3, # 点の図形
xaxt="n", yaxt="n", xlab="", ylab="") # 後述で設定するので非表示にする
axis(side=1, at=seq(xmin, xmax, 10)) # X軸目盛り
axis(side=2, at=seq(ymin, ymax, 10)) # Y軸目盛り
abline(h=seq(ymin, ymax, 5),lty="dotted") # 水平補助線
abline(v=seq(xmin, xmax, 5),lty="dotted") # 垂直補助線
title(main="regression", # タイトル
xlab="x-axis", ylab="y-axis") # 軸ラベル
# ===== X-Y相関係数
r <- cor(x,y)
paste("(x,y)の相関係数=", r)
# ===== 回帰分析
kekka <- lm(y~x) # y = a + bx の関係
summary(kekka)
# 回帰直線の係数
係数 <- coefficients(kekka)
paste("回帰式:",係数[1], "+", 係数[2], "*x")
# ========== 決定係数、p値
r2 <- summary(kekka)$r.squared
r <- sqrt(r2)
para <- summary(kekka)$fstatistic
p <- pf(para[1], para[2], para[3], lower.tail=F)
paste("決定係数 r2=",r2, ", 相関係数 r=",r, ", p値=", p)
# ===== 信頼区間
newx <- data.frame(x = seq(xmin, xmax, 1))
# 補間のためのX軸データの設定(データフレーム形式にする必要がある)
newyc <- predict(kekka, newdata=newx, # newx による信頼区間上・下限値の計算
interval='confidence', # 信頼区間
level=0.95) # 95% 信頼
newyp <- predict(kekka, newdata=newx, # newx による信頼区間上・下限値の計算
interval='prediction', # 予測区間
level=0.95) # 95% 信頼
# 信頼区間の表示
lines(newx$x, newyc[,"fit"], lwd=4, col='red') # 回帰式
lines(newx$x, newyc[,"upr"], lwd=2, col="blue") # 信頼区間上限の曲線
lines(newx$x, newyc[,"lwr"], lwd=2, col="blue") # 信頼区間下限の曲線
lines(newx$x, newyp[,"upr"], lwd=2, col="green") # 予測上限の曲線
lines(newx$x, newyp[,"lwr"], lwd=2, col="green") # 予測下限の曲線
点 (x,y) の相関関係です。回帰式とは無関係。
回帰分析により回帰直線の係数を求める関数です。
# 回帰式の構成
# y~x y= a0 + a1*x xはベクトル
# y~x-1 y= a1*x 切片0(比例)
# y~x+I(x^2) y= a0 + a1*x + a2*x^2 高次式
# y~x1+x2 y= a0 + a1*x1 + a2*x2 多項式
kekka <- lm(y~x); summary(kekka) とすれば、次の情報が得られます
#
# Call:
# lm(formula = y ~ x)
#
# Residuals: 残差(回帰式との差)
# Min 1Q Median 3Q Max
# 8.9218 1.1860 -12.9178 -4.2857 -0.6536 0.2426 7.5067
#
# Coefficients:
# 係数 標準偏差 t値 確率 有意差水準
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 56.0782 5.5835 10.043 0.000167 ***
# x 0.2736 0.1562 1.752 0.140152
# --- └ y = 56.0782 + 0.2736x
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#
# Residual standard error: 8.038 on 5 degrees of freedom
# Multiple R-squared: 0.3804, Adjusted R-squared: 0.2565
# └ r2(決定係数)
# F-statistic: 3.07 on 1 and 5 DF, p-value: 0.1402 ← P値
# └ 自由度が1と5でのF値 └ <0.05 なら回帰式とよく合致、>0.05 なら合致しない
coefficients(kekka) とすれば、上表から係数をの取出せます
# (Intercept) x
# 56.0781671 0.2735849
summary(kekka)$r.squared 上のR-squared(決定係数)を取り出す
# 回帰式と点との関係を示します。
# 決定係数が0.38とは、62%の残差があるということで、あまりよい近似ではありません。
summary(kekka)$fstatistic 上のF-statisticを取り出す
# p値:帰無仮説「母集団が回帰式に合致しない」 の発生確率が14%
# 0.05以下ならば、仮説は棄却され「母集団が回帰式に95%合致する」と結論できる。
# ここでは 0.1402>0.05 なので「棄却できない」(どちらともいえない)ことになる。
kekka <- lm(y~x) で得た回帰式に、x=newdata の値を代入した結果を得る関数です。
level=0.95 # 有意水準(変更できます)
interval="confidence" # 信頼区間(平均予測値の周りの不確実性を反映)
"prediction" # 予測区間(単一の値の周りの不確実性を反映)
信頼区間(図の青線)
回帰式の信頼区間。母集団の母数(標本から測定できない)に対して「どの範囲にあると推定できるか」を示す。
測定・解析を同一方法で100回繰り返したら、100回のうち95回は回帰直線はこの範囲を通ると考えられる。
予測区間(図の緑線)
母集団を仮定した上で、将来観察されるであろう標本値に対して「どの範囲にあると予測されるか」を示す。
予測区間が残差も考慮にいれているので、区間幅は広くなる。
全体をまとめると次のようになります。
# 信頼区間 予測区間
# x y fit lwr.x upr.x lwr.y upr.y
# 回帰式 下限 上限 下限 上限
# 0 65 56.07 41.72 70.43 30.91 81.23
# 10 60 58.81 47.61 70.01 35.31 82.31
# 25 50 62.91 54.85 70.98 40.73 85.09
# 30 60 64.28 56.19 71.83 41.91 86.10
# 35 65 65.65 57.58 73.71 43.47 87.83
# 50 70 69.75 58.55 80.95 46.25 93.26
# 60 80 72.49 58.14 86.84 47.33 97.65

x-y 相関係数 = 0.6167
回帰式: y= 64.426 -0.6870*x +0.0160*x^2
決定係数 r2= 0.8415, 相関係数 r= 0.9173
p値= 0.0251
kekka <- lm(y~x+I(x^2)) と変えただけです。
# ========== 係数算出
kekka <- lm(y~x+I(x^2)) # 説明変数が二次式のときの指定
summary(kekka) # 抜粋
# Coefficients:
# Estimate 回帰式
# (Intercept) 64.426186 a y = 64.426 - 0.687x + 0.016x^2
# x -0.687009 b
# I(x^2) 0.016010 c
# ┌ 決定係数
# Multiple R-squared: 0.8415, Adjusted R-squared: 0.7623
# F-statistic: 10.62 on 2 and 4 DF, p-value: 0.02512
# └ <0.05 95%で有意差あり
predict(kekka) # xに対応する回帰式の値
# 信頼区間 予測区間
# x y fit lwr.x upr.x lwr.y upr.y
# 回帰式 下限 上限 下限 上限
# 0 65 64.42 53.33 75.51 47.62 81.22
# 10 60 59.15 52.31 66.00 44.79 73.51
# 30 60 58.22 51.36 65.08 43.85 72.58
# 50 70 70.10 63.25 76.94 55.74 84.45
# 60 80 80.84 69.75 91.93 64.04 97.64
y = a + b*x1 + c*x2 のように、説明変数 x が複数の場合です。lm(y~x1+x2) になります。
X軸が定まらないのでグラフは描けません。その代わりに、x1,x2,y, 回帰式の値、区間の値 を表形式で出力します。
そのため、入力データをデータフレームの形式で与えるのが便利です。
# ========== 入力データ
df <- data.frame( # データフレームの形式で与えると便利
x1 = c( 0, 10, 25, 30, 35, 50, 60),
x2 = c( 30, 20, 10, 15, 20, 20, 25),
y = c( 65, 60, 50, 60, 65, 70, 80))
print("■■入力データ■■")
df
# ========== 回帰分析
kekka <- lm(y~x1+x2)
print("■■lm() simmary■■")
summary(kekka)
print("■■回帰式■■")
係数 <- coefficients(kekka)
paste("回帰式:", 係数[1], "+", 係数[2], "*x1", 係数[3], "*x2")
# ========== 決定係数、p値
r2 <- summary(kekka)$r.squared
r <- sqrt(r2)
para <- summary(kekka)$fstatistic
p <- pf(para[1], para[2], para[3], lower.tail=F)
print("■■決定係数等■■")
paste("決定係数 r2=",r2, ", 相関係数 r=",r, ", p値=", p)
# ===== 信頼区間・予測区間の計算
newx <- data.frame(x = seq(1,7, 1))
newyc <- predict(kekka, newdata = newx,
interval = 'confidence', level = 0.95) # 新X点に対応する信頼区間95%限界点
newyp <- predict(kekka, newdata = newx,
interval = 'prediction', level = 0.95) # 新X点に対応する予測区間95%限界点
# ========== 表の作成
df$回帰式 <- newyc[, "fit"] # 回帰式を計算した結果 "fit" を列に追加
df$信頼下限 <- newyc[, "lwr"]
df$信頼上限 <- newyc[, "upr"]
df$予測下限 <- newyp[, "lwr"]
df$予測上限 <- newyp[, "upr"]
print("■■結果の表■■")
df
決定係数 = 0.979、p値 = 0.0004 など、かなりよい近似になりました。
"■■入力データ■■"
x1 x2 y ←列名 これに回帰式が信頼区間などの列が追加される
0 30 65
10 20 60
25 10 50
30 15 60
35 20 65
50 20 70
60 25 80
■■lm() simmary■■"
Call:
lm(formula = y ~ x1 + x2)
Residuals:
1 2 3 4 5 6 7
-1.0673 2.0361 -1.4409 1.3465 -0.8662 -0.6076 0.5993
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 32.27422 2.47284 13.051 0.000199 ***
x1 0.31609 0.03194 9.895 0.000585 ***
x2 1.12644 0.10400 10.831 0.000412 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.632 on 4 degrees of freedom
Multiple R-squared: 0.9796, Adjusted R-squared: 0.9694
F-statistic: 95.9 on 2 and 4 DF, p-value: 0.0004174
■■回帰式■■"
'回帰式: 32.2742200328407 + 0.316091954022988 *x1 1.1264367816092 *x2'
■■決定係数等■■"
'決定係数 r2= 0.979570146433632 , 相関係数 r= 0.989732361011618 , p値= 0.000417378916743219'
■■結果の表■■"
# x1 x2 y 回帰式 信頼下限 信頼上限 予測下限 予測上限
# 0 30 65 66.067 62.010 70.124 59.985 72.149
# 10 20 60 57.963 55.498 60.429 52.805 63.122
# 25 10 50 51.440 48.008 54.873 45.756 57.125
# 30 15 60 58.653 56.413 60.893 53.599 63.707
# 35 20 65 65.866 64.097 67.635 61.002 70.730
# 50 20 70 70.607 68.141 73.073 65.449 75.765
# 60 25 80 79.400 75.789 83.011 73.606 85.194