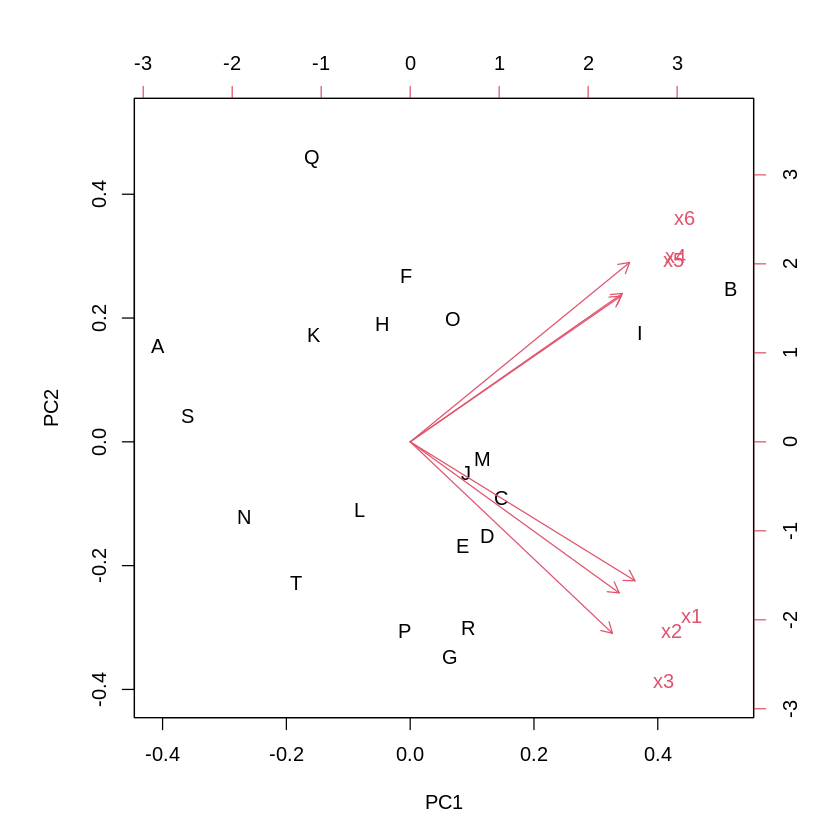
 横軸に第1主成分、縦軸に第2主成分をとったときの各科目の関係と各標本の位置
x1,x2,x3 は理系項目、x4,x5,x6 は文系項目のように人間が解釈する
横軸に第1主成分、縦軸に第2主成分をとったときの各科目の関係と各標本の位置
x1,x2,x3 は理系項目、x4,x5,x6 は文系項目のように人間が解釈する
スタートページ> JavaScript> 他言語> R言語
青字部分をGoogle Colaboratryの「コード」部分にコピーアンドペースト(ペーストは Cntl+V)して実行すれば結果が表示されます。
次の6つの特性(科目成績)を持つ20組(学生)のデータから、第1主成分と第2主成分を求めます。
# 〓〓〓 0 入力データ
# 成績表 → 科目
m <- matrix(c(3, 4, 4, 5, 4, 4, # ↓学生 A
6, 6, 7, 8, 7, 7, # B
6, 5, 7, 5, 5, 6, # C
6, 7, 5, 4, 6, 5, # D
5, 7, 6, 5, 5, 5, # E
4, 5, 5, 5, 6, 6, # F
6, 6, 7, 6, 4, 4, # G
5, 5, 4, 5, 5, 6, # H
6, 6, 6, 7, 7, 6, # I
6, 5, 6, 6, 5, 5, # J
5, 4, 4, 5, 5, 5, # K
5, 5, 6, 5, 4, 5, # L
6, 6, 5, 5, 6, 5, # M
5, 5, 4, 4, 5, 3, # N
5, 6, 4, 5, 6, 6, # O
6, 6, 6, 4, 4, 5, # P
4, 4, 3, 6, 5, 6, # Q
6, 6, 7, 4, 5, 5, # R
5, 3, 4, 3, 5, 4, # S
4, 6, 6, 3, 5, 4 # T
),
nrow=20, byrow=T)
df <- data.frame(m) # 扱いやすいようにデータフレームにする
colnames(df) <- c('x1','x2','x3','x4','x5','x6') # 科目名
rownames(df) <- c('A','B','C','D','E','F','G','H','I','J', # 学生名
'K','L','M','N','O','P','Q','R','S','T')
# 〓〓〓 1 単純に最終結果を得る 結果 <- prcomp(df, scale=T) summary(結果) biplot(結果)
結果 <- prcomp(df, scale=T)
prcompは、主成分分析を行うアドオンライブラリ
scale=T:相関行列から主成分分析を行う
scale=F:分散共分散行列から主成分分析を行う
summary(結果)
Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6 # 第n主成分
Standard deviation 1.6405 1.2335 0.8453 0.69439 0.57795 0.50658 # 標準偏差
Proportion of Variance 0.4485 0.2536 0.1191 0.08036 0.05567 0.04277 # 寄与率
Cumulative Proportion 0.4485 0.7021 0.8212 0.90156 0.95723 1.00000 # 累積寄与率
第1成分だけで45%、第1成分と第2成分で70%の説明ができる
biplot(結果)
横軸に第1主成分、縦軸に第2主成分をとったときの各科目の関係と各標本の位置
x1,x2,x3 は理系項目、x4,x5,x6 は文系項目のように人間が解釈する
# 〓〓〓 2 主成分の式 round(結果$rotation, 3) # 固有ベクトル(主成分軸の係数) round(結果$x, 3) # 主成分得点
結果$rotation
固有ベクトル(主成分軸の係数)を求める(round で小数点以下3位)。各成分と各科目の関係を示す。
PC1 PC2 PC3 PC4 PC5 PC6
x1 0.431 -0.354 -0.056 0.766 0.005 0.315
x2 0.400 -0.385 0.467 -0.538 0.122 0.411
x3 0.387 -0.488 -0.377 -0.210 -0.172 -0.629
x4 0.406 0.378 -0.526 -0.163 0.602 0.163
x5 0.404 0.371 0.592 0.199 0.206 -0.517
x6 0.420 0.457 -0.099 -0.112 -0.742 0.204
│ └ 第2主成分:-0.354*x1 - 0.385*x2 + … + 0.457*x6
│ 理系(-)と文系(+)で差が出るようにしている
└ 第1主成分:0.431*x1 + 0.400*x2 + … + 0.420*x6
全体の成績で差が出るようにしている。
結果$x
各学生の各成分での得点(上のグラフ参照)
PC1 PC2 PC3 PC4 PC5 PC6
A -2.997 0.856 -0.760 -1.109 0.574 -0.200 # 全体の成績が悪い
B 3.799 1.362 -0.571 -0.157 0.292 -0.546 # 全体の成績が良い
G 0.473 -1.920 -1.383 -0.210 0.911 0.286 # 文系と理系での差が大きい(理系が良い)
J 0.666 -0.277 -0.973 0.582 0.394 0.023 # 平均的
Q -1.169 2.517 -0.500 -0.228 -0.091 0.630 # 文系と理系での差が大きい(文系が良い)
# 〓〓〓 3 因子負荷量 主成分に強く寄与している科目
fc.l <- sweep(結果$rotation, MARGIN=2, 結果$sdev, FUN="*")
項目 <- c('1','2','3','4','5','6') # x1, x2 としたいのだが1文字の制約
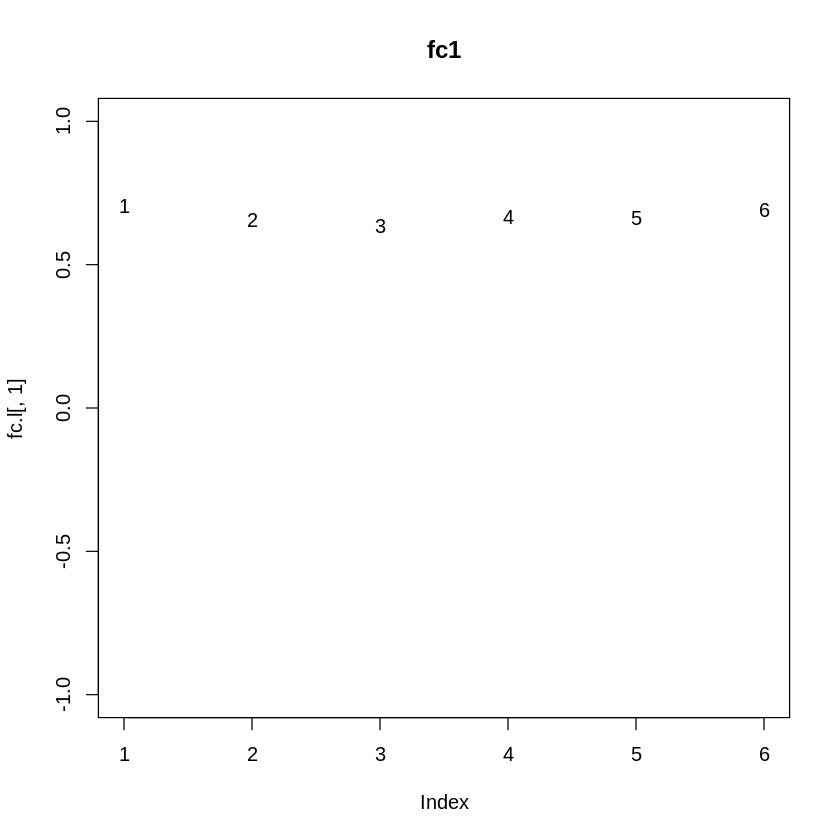
plot(fc.l[,1], pch=項目, ylim=c(-1,1), main="fc1") # 第1主成分への影響
plot(fc.l[,2], pch=項目, ylim=c(-1,1), main="fc2") # 第2主成分への影響
このプロセスは、私は理解していません。左図:第1主成分には、全ての科目が+で影響している 右図:第2主成分には、x1, x2, x3 は-、x4, x5, x6 は+で影響している
# 〓〓〓 4 第1主成分-第2主成分平面での各科目の位置 plot(fc.l[,1], fc.l[,2], pch=項目, xlim=c(-1,1), ylim=c(-1,1), main="fc1-fc2")
各科目のグループ化をしたグラフ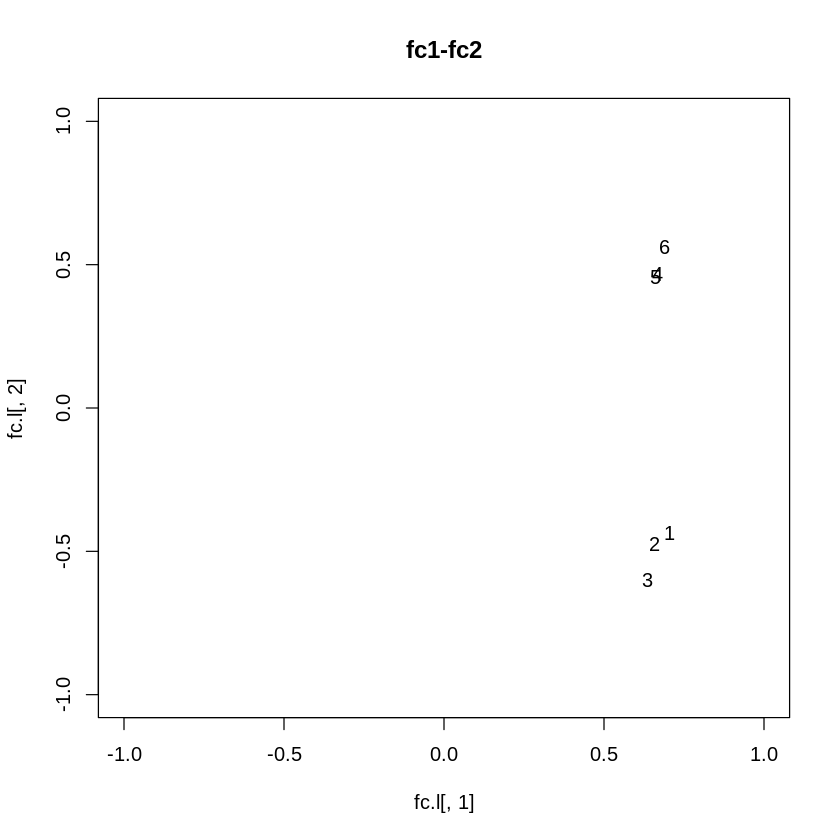
# 〓〓〓 5 各標本の入力データと第1主成分-第2主成分平面での各科目の位置 pc1 <- round(as.matrix(結果$x[,"PC1"]), 2) pc2 <- round(as.matrix(結果$x[,"PC2"]), 2) mm <- cbind(m, pc1) mm <- cbind(mm, pc2) mm
# x1 x2 x3 x4 x5 x6 PC1 PC2
A 3 4 4 5 4 4 -3.00 0.86
B 6 6 7 8 7 7 3.80 1.36
C 6 5 7 5 5 6 1.07 -0.50
D 6 7 5 4 6 5 0.91 -0.84
:
Q 4 4 3 6 5 6 -1.17 2.52
R 6 6 7 4 5 5 0.69 -1.66
S 5 3 4 3 5 4 -2.64 0.23
T 4 6 6 3 5 4 -1.35 -1.26