スタートページ> JavaScript> 他言語> R言語
青字部分をGoogle Colaboratryの「コード」部分にコピーアンドペースト(ペーストは Cntl+V)して実行すれば結果が表示されます。
2つの特性 x1, x2 を持つ30組のデータA, B, C, … があり、何らかの基準で正群(1)と負群(ー1)にクラス分けしています。
z = a1*x1 + a2*x2 + b を想定して、 z > 0 なら正群、z < 0 なら負群となるように、入力データでのクラス分けにできりだけ合致するような a1, a2, b を求めたいのです。(lda() では、+b ではなく、-b として計算しています)
これにより、次のことができるようになります。
・現在のクラス分けは、特性をどのように評価しているのだろうか。それは妥当か。
・判別関数での計算結果と異なるクラスに仕分けされるデータは適切な仕分けであったか。
・新しいデータがどちらのクラスに属するかを評価することができる。
このような統計的方法を判別分析といい、上の式 z = a1*x1 + a2*x2 + b を判別関数といいます。
library(MASS) にある lda() 関数(linear discriminant analysis:線形判別分析)を用いることにより、判別分析の例を示します。
ここでは単純にするために、特性を2つとし、判別関数を1次式としました。
# 〓〓〓 データ入力
df <- data.frame(r = c("A","B","C","D","E","F","G","H","I","J","K","L","M","N","O",
"P","Q","R","S","T","U","V","W","X","Y","Z","a","b","c","d"),
z = c( 1, -1, -1, 1, 1, -1, -1, 1, -1, 1, 1, 1, -1, 1, -1,
1, -1, -1, -1, 1, -1, 1, -1, -1, -1, 1, -1, 1, -1, -1),
x1 = c(33, 35, 21, 53, 54, 52, 38, 56, 17, 51, 50, 32, 33, 48, 43,
53, 28, 25, 39, 59, 38, 41, 27, 43, 20, 43, 36, 36, 38, 22),
x2 = c(84, 72, 69, 64, 74, 50, 67, 70, 60, 84, 93, 80, 74, 85, 68,
60, 54, 64, 70, 74, 61, 72, 77, 65, 70, 62, 45, 85, 47, 65))
# 〓〓〓 判別分析
library(MASS) # アドオンのライブラリを用いる
kekka <- lda(df$z~+df$x1+df$x2)
# ======= 判別関数の出力
a <- kekka$scaling
b <- apply(kekka$means%*%kekka$scaling,2,mean)
print("===== 判別関数 =====")
(判別関数 <- paste0("z = ", a[1], " * x1 ", a[2], " * x2 ", -b))
# ======= 結果の一覧表の出力
df$判定 <- a[1]*df$x1 + a[2]*df$x2 - b # 特性関数による各データの計算値
df$エラー <- ifelse(df$z * df$判定 >= 0, " ", "×")
df["正群確率"] <- kekka2$posterior[,2]
df["負群確率"] <- kekka2$posterior[,1]
df
"===== 判別関数 ====="
'z = 0.094247294738935 * x1 0.0827703110077601 * x2 -9.51240421003522'
df 一部抜粋
r z x1 x2 判定 エラー 正群確率 負群確率
1 A 1 33 84 0.55046264 0.6634944182 0.3365055818
2 B -1 35 72 -0.25428650 0.3133997387 0.6866002613
13 M -1 33 74 -0.27724047 0.3108831681 0.6891168319
14 N 1 48 85 2.04694237 0.9889042467 0.0110957533
15 O -1 43 68 0.16861061 × 0.5716800454 0.4283199546
25 Y -1 20 70 -1.83353654 0.0109925342 0.9890074658
26 Z 1 43 62 -0.32801125 × 0.1920272846 0.8079727154
27 a -1 36 45 -2.39483760 0.0022315774 0.9977684226
28 b 1 36 85 0.91597484 0.8375669212 0.1624330788
29 c -1 38 47 -2.04080239 0.0062935306 0.9937064694
30 d -1 22 65 -2.05889351 0.0061654674 0.9938345326
# 〓〓〓 データ入力
df <- data.frame(r = c("A","B","C","D","E","F","G","H","I","J","K","L","M","N","O",
"P","Q","R","S","T","U","V","W","X","Y","Z","a","b","c","d"),
z = c( 1, -1, -1, 1, 1, -1, -1, 1, -1, 1, 1, 1, -1, 1, -1,
1, -1, -1, -1, 1, -1, 1, -1, -1, -1, 1, -1, 1, -1, -1),
x1 = c(33, 35, 21, 53, 54, 52, 38, 56, 17, 51, 50, 32, 33, 48, 43,
53, 28, 25, 39, 59, 38, 41, 27, 43, 20, 43, 36, 36, 38, 22),
x2 = c(84, 72, 69, 64, 74, 50, 67, 70, 60, 84, 93, 80, 74, 85, 68,
60, 54, 64, 70, 74, 61, 72, 77, 65, 70, 62, 45, 85, 47, 65))
print("===== 入力データ df =====")
df
# 〓〓〓 判別分析
library(MASS) # アドオンのライブラリを用いる
kekka <- lda(df$z~+df$x1+df$x2)
# 判別分析:判別関数の構造を z=a1*x1+a2*x2+b とし、a1,a2,b を求める
print("===== lda() 判別分析の結果 =====")
kekka
# 〓〓〓 個々の情報の取出し
a <- kekka$scaling
print("===== 判別関数:係数 =====")
a
print("===== kekka$means =====")
kekka$means
print("===== kekka$scaling =====")
kekka$scaling
b <- apply(kekka$means%*%kekka$scaling,2,mean)
print("===== 定数項 =====")
b
print("===== 判別関数 =====")
(判別関数 <- paste0("z = ", a[1], " * x1 ", a[2], " * x2 ", -b))
# 〓〓〓 各データに判別関数を適用
kekka2 <- lda(df$z~+df$x1+df$x2, CV=T)
print("===== kekka2 <- lda(df$z~+df$x1+df$x2, CV=T) =====")
kekka2
kekka3 <- table(df$z,kekka2$class)
print("===== kekka3 <- table(df$z,kekka2$class) =====")
kekka3
r <- sum(kekka3[row(kekka3)==col(kekka3)])/sum(kekka3)
print("===== 判別率 =====")
r
# 〓〓〓= 一覧表の作成(入力データ df に計算結果の列を追加する)
df$判定 <- a[1]*df$x1 + a[2]*df$x2 - b # 特性関数による各データの計算値
df$エラー <- ifelse(df$z * df$判定 >= 0, " ", "×")
df["正群確率"] <- kekka2$posterior[,2]
df["負群確率"] <- kekka2$posterior[,1]
print("===== 結果一覧表 =====")
df
# 〓〓〓 散布図表示 特性要因が x1, x2 の2つのときだけ可能
# 散布図
iro <- ifelse(df$z == 1, "red", "blue")
plot(df$x1,df$x2, col=iro, pch=df$r, cex=0.8, xlab="X1", ylab="X2")
# plot(kekka)
legend("topleft", legend=c("z=1","z=-1"), col=c("red", "blue"), pch=16)
# 判別関数の加筆
x1min <- min(df$x1)
x1max <- max(df$x1)
x2min <- (b-a[1]*x1min)/a[2]
x2max <- (b-a[1]*x1max)/a[2]
lines(c(x1min,x1max),c(x2min,x2max), type="l", col="green", lwd=2)
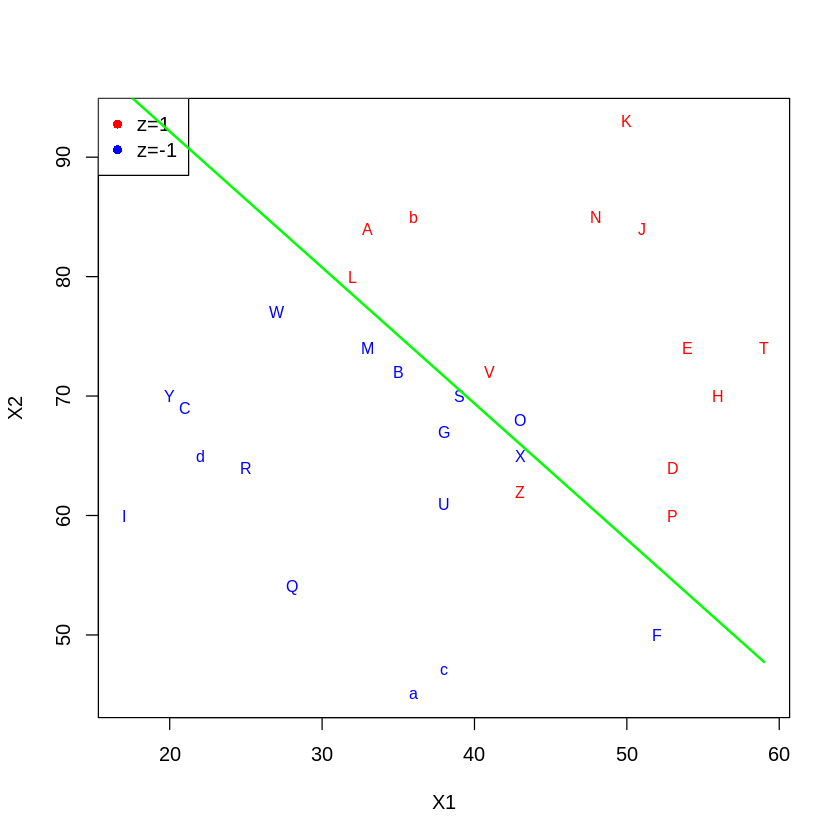
〓〓〓 判別関数と散布図
「判別関数:係数」と「定数項」から、判別関数は
Z = 0.09424729*x1 + 0.08277031*x2 - 9.512404 z = 0 のときが散布図の緑線になります。
となります。x1, x2 を与えて、z >= 0 ならば正群(赤)、z < 0 ならば負群(青)になります。
この判別関数は、赤・青をかなりよく分離しています。「合致確率」は0.9、すなわち90%が正しく分離されています。(データは30組ですので、外れているのは3組です。)
〓〓〓 判定表
「判定」は、判別関数での値です。この符号と事前の区分 z の符号が一致していれば正解、一致しなければエラーになります。エラーはL、O、Zの3組です。(●Lは正群確率<負群確率ですし、他の情報ではー1になっておりエラーになるはずですが、この表では0.125→1になっています。原因は不明です)
判定の絶対値が大ならば、判別関数の直線から離れている(KやIなど)、小ならば直線に近い(LやSなど)を示しています。
「正群確率」「負群確率」は、そのグループに属する確率です。Aを例にすれば、Aが正群に属する確率は66%で負群の属する確率は34%(合計は100%)であることを示しています。
一方の確率が高ければ、特性要因に少しの変化があってもそのグループに属すことを示します。双方の確率が似ていれば(50%程度)ならば、少しの変化があれば他のグループになることを示しています。
これらの確率と判定値は、同じことをいっています。Kを例にすれば、ほぼ100%で正群であり、判別関数から大きく離れています。
■■■■■■ 判別分析 判別関数を求める
# 〓〓〓 係数 a[1], a[2] を求める
library(MASS) # 下の lda は、この分野に特化した関数で、標準提供されていません。
# 専用のアドオンライブラリ MMSS を用います。
kekka <- lda(df$z~+df$x1+df$x2)
# 〓〓〓 係数 a[1], a[2] を求める
# lda linear discriminant analysis(線形判別分析)用の関数
# 一般形 lda(目的変数 ~ +説明変数 + 説明変数 + ・・・)判別関数の構造定義
# z = a1*x1 + a2*x2 (- b) のパターンだとしています
# lda は、b を直接には求めていません。他の情報から計算して求めます。
# kekka の内容 lda により得られた情報です
# Call:
# lda(df$z ~ +df$x1 + df$x2)
# Prior probabilities of groups: 正群・負群の組数比率
# -1 1 負群(-1)正群(1)の数値の昇順
# 0.5666667 0.4333333 その構成比率 (17と13)
#
# Group means:
# df$x1 df$x2 この結果は b の計算に用います
# -1 32.64706 63.41176
# 1 46.84615 75.92308 ← x1の列でグループ1に属しているものの平均値が46.84615
# Coefficients of linear discriminants:
# LD1 判別係数の係数 次のkekka$scalingで取り出します
# df$x1 0.09424729 x1の係数
# df$x2 0.08277031 x2の係数
# 判別係数:z = 0.09424729*x1 0.08277031*x2 - 定数項 になります。
a <- kekka$scaling
# 上の「Coefficients of linear discriminants」を取り出しています。
# LD1
# df$x1 0.09424729 a[1] として取り出せます
# df$x2 0.08277031 a[2] として取り出せます
# 〓〓〓 定数項 b を求める
b <- apply(kekka$means%*%kekka$scaling,2,mean)
# kekka$means 上の「Group means」を取り出しています
# 次の区分での平均です
# 入力 x1 x2
# 結果のクラス -1 p11=32.64706 p12=63.41176 p
# 1 p21=46.84615 p22=75.92308
# kekka$scaling上の「Coefficients of linear discriminants」を取り出しています
# a[1] = 0.09424729
# a[2] = 0.08277031
# kekka$means%*%kekka$scaling
# p[i,j]*a[j] (内積)を計算し列方向での平均値を計算する
# p11*a[1]+p12*a[2] = 8.325507964313
# p21*a[1]+p22*a[2] = 10.699299552188
# 平均 = 9.512403758250 = b
# 複雑なようですが、x1, x2 の平均値を v1, v2 として、次の連立方程式を解いているのです。
# a[1]*v1 + a[2]*v2 = b-1
# a[1]*v1 + a[2]*v2 = b+1
# 9.512404 定数項
# 判別係数:z = 0.0942*x1 + 0.0827*x2 - 9.512
■■■■■■ 交差確認(予測の精度)
kekka2 <- lda(df$z~+df$x1+df$x2, CV=T)
# CV=T とは、cross validation(交差検証)のことです。定義式(判別関数)に x1,x2 を入れて、
# -1あるいは1になる確率を計算し、各データがどちらに属するかを計算する関数です。
# kekka2 の情報
# $class 判別関数に当てはめた結果での各データの属する群
# A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d
# 1 -1 -1 1 1 -1 -1 1 -1 1 1 -1 -1 1 1 1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1
# ●(後述)
# Levels: -1 1
#
# $posterior
# 負群確率 正群確率 当然、合計=1になる。後のステップで df に取り込む
# -1 1
# 1 0.3365055818 0.6634944182
# 2 0.6866002613 0.3133997387
# 3 0.9886987214 0.0113012786
# 4 0.2084264848 0.7915735152
# 5 0.0257474248 0.9742525752
# : :
# 27 0.9977684226 0.0022315774
# 28 0.1624330788 0.8375669212
# 29 0.9937064694 0.0062935306
# 30 0.9938345326 0.0061654674
#
# $terms 問題の解析に関する事項ばかりで解に関する情報は乏しい
# df$z ~ +df$x1 + df$x2
# attr(,"variables")
# list(df$z, df$x1, df$x2)
# attr(,"factors")
# df$x1 df$x2
# df$z 0 0
# df$x1 1 0
# df$x2 0 1
# attr(,"term.labels")
# [1] "df$x1" "df$x2"
# attr(,"order")
# [1] 1 1
# attr(,"intercept")
# [1] 1
# attr(,"response")
# [1] 1
# attr(,".Environment")
#
# attr(,"predvars")
# list(df$z, df$x1, df$x2)
# attr(,"dataClasses")
# df$z df$x1 df$x2
# "numeric" "numeric" "numeric"
# $call
# lda(formula = df$z ~ +df$x1 + df$x2, CV = T)
# $xlevels
# named list()
kekka3 <- table(df$z, kekka2$class)
# table(v1, 2) は v1 と v2 のデータ数のクロス集計関数です。
# kekka3
# -1 1
# -1 16 1 入力で-1 計算後も-1だったのが16件 1になったのが1件
# 1 2 11 入力で-1 計算後は1になったのが2件 -1だったのは11件
# 全体30件のうち判別関数で一致したのは27件、一致しなかったのは3件
sum(kekka3[row(kekka3)==col(kekka3)])/sum(kekka3)
# [ ] の中は「行番号=列番号」すなわち右下がりの対角線。すなわち 16, 11
# すなわち (16 + 11)/(16+1+2+11) = 27/30 =0.9
# 0.9 これを判別率という。「判別関数の結果が入力したzと一致する確率」
■■■■■■ 判定結果をdfに記入
df$判定 <- a[1]*df$x1 + a[2]*df$x2 - b # 判別関数に特性要因を代入して計算
df$エラー <- ifelse(df$z * df$判定 >= 0, " ", "×") # z と判定地の符号が異なればエラー
df["正群確率"] <- kekka2$posterior[,2] # kekka2 の表をコピー
df["負群確率"] <- kekka2$posterior[,1]
# r z x1 x2 判定 エラー 正群確率 負群確率
# 1 A 1 33 84 0.55046264 0.6634944182 0.3365055818
# 2 B -1 35 72 -0.25428650 0.3133997387 0.6866002613
# 3 C -1 21 69 -1.82205956 0.0113012786 0.9886987214
# 4 D 1 53 64 0.78000232 0.7915735152 0.2084264848
# 5 E 1 54 74 1.70195272 0.9742525752 0.0257474248
# 6 F -1 52 50 -0.47302933 0.3375423714 0.6624576286
# 7 G -1 38 67 -0.38539617 0.2440232343 0.7559767657
# 8 H 1 56 70 1.55936607 0.9630459016 0.0369540984
# 9 I -1 17 60 -2.94398154 0.0004297177 0.9995702823
# 10 J 1 51 84 2.24691395 0.9933855558 0.0066144442
# 11 K 1 50 93 2.89759945 0.9991216362 0.0008783638
# 12 L 1 32 80 0.12513410 0.4146853032 0.5853146968 ← 注
# 13 M -1 33 74 -0.27724047 0.3108831681 0.6891168319
# 14 N 1 48 85 2.04694237 0.9889042467 0.0110957533
# 15 O -1 43 68 0.16861061 × 0.5716800454 0.4283199546
# 16 P 1 53 60 0.44892107 0.5930924950 0.4069075050
# 17 Q -1 28 54 -2.40388316 0.0024522144 0.9975477856
# 18 R -1 25 64 -1.85892194 0.0102673580 0.9897326420
# 19 S -1 39 70 -0.04283794 0.4292165622 0.5707834378
# 20 T 1 59 74 2.17318919 0.9920173470 0.0079826530
# 21 U -1 38 61 -0.88201804 0.0938795639 0.9061204361
# 22 V 1 41 72 0.31119727 0.5983295636 0.4016704364
# 23 W -1 27 77 -0.59441330 0.1936912422 0.8063087578
# 24 X -1 43 65 -0.07970032 0.4172186555 0.5827813445
# 25 Y -1 20 70 -1.83353654 0.0109925342 0.9890074658
# 26 Z 1 43 62 -0.32801125 × 0.1920272846 0.8079727154
# 27 a -1 36 45 -2.39483760 0.0022315774 0.9977684226
# 28 b 1 36 85 0.91597484 0.8375669212 0.1624330788
# 29 c -1 38 47 -2.04080239 0.0062935306 0.9937064694
# 30 d -1 22 65 -2.05889351 0.0061654674 0.9938345326
#
# (注)Lは、kekka2のclassで -1 になっている。すなわち「一致しない」3件の一つ
# 正群確率 < 負群確率 でもある。
# それなのに、判定(判別関数の値)= 0.125 > 0 なので 1 になり「一致している」
# この違いが起こった理由は、私にはわからない。
この結果による判別関数
z = 0.094247294738935*x1 + 0.0827703110077601*x2 - 9.51240421003522
が信頼できると認められるならば、後日新しいデータの x1, x2 を入力すれば、判定値を計算して正群/負群を判別することができます。
判別関数 <- function(x1, x2) 0.094247294738935*x1 + 0.0827703110077601*x2 - 9.51240421003522
判別関数(33, 84) # 0.55046264100148 → 1
判別関数(35, 72) # -0.25428650161376 → -1
判別関数(21, 69) # -1.82205956098214 → -1