スタートページ> JavaScript> 他言語> R言語
青字部分をGoogle Colaboratryの「コード」部分にコピーアンドペースト(ペーストは Cntl+V)して実行すれば結果が表示されます。
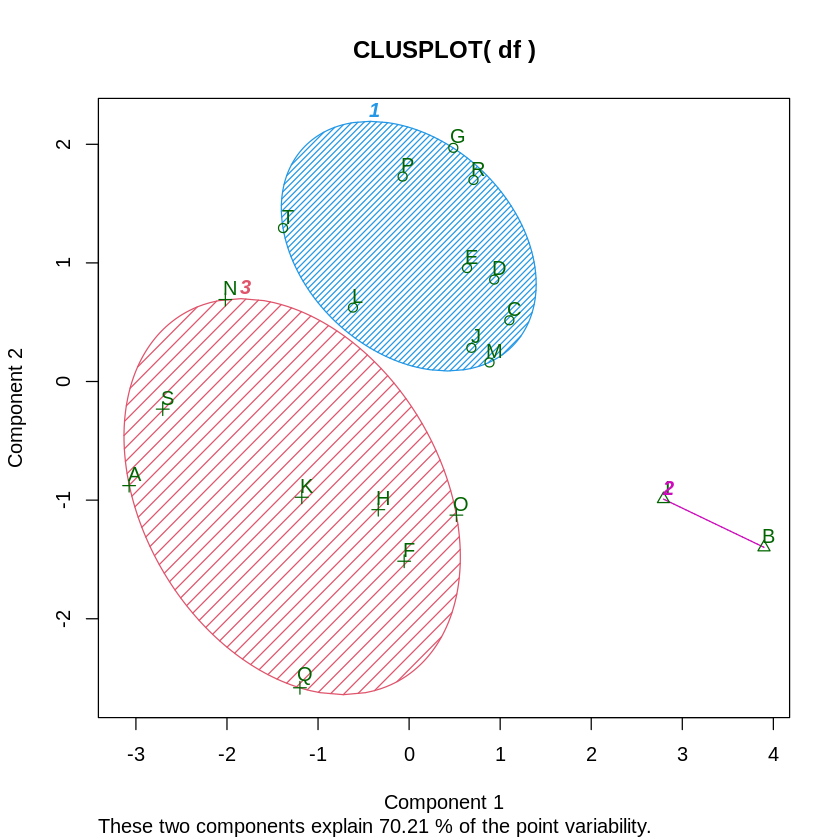
次の6つの特性を持つ20組のデータを、3つのグループにクラスタリング(似たものあつめ)すると、右図のようになります。
# 〓〓〓 入力データ
m <- matrix(c(3, 4, 4, 5, 4, 4,
6, 6, 7, 8, 7, 7,
6, 5, 7, 5, 5, 6,
6, 7, 5, 4, 6, 5,
5, 7, 6, 5, 5, 5,
4, 5, 5, 5, 6, 6,
6, 6, 7, 6, 4, 4,
5, 5, 4, 5, 5, 6,
6, 6, 6, 7, 7, 6,
6, 5, 6, 6, 5, 5,
5, 4, 4, 5, 5, 5,
5, 5, 6, 5, 4, 5,
6, 6, 5, 5, 6, 5,
5, 5, 4, 4, 5, 3,
5, 6, 4, 5, 6, 6,
6, 6, 6, 4, 4, 5,
4, 4, 3, 6, 5, 6,
6, 6, 7, 4, 5, 5,
5, 3, 4, 3, 5, 4,
4, 6, 6, 3, 5, 4),
nrow=20, byrow=T)
df <- data.frame(m)
colnames(df) <- c('x1','x2','x3','x4','x5')
rownames(df) <- c('A','B','C','D','E','F','G','H','I','J',
'K','L','M','N','O','P','Q','R','S','T')
# 〓〓〓 クラスタリング
library(cluster)
指定クラス数 <- 3
kekka <- kmeans(df, 指定クラス数)
grp <- kekka$cluster
cbind(df, grp)
clusplot(df, grp, color=TRUE, shade=TRUE, labels=2, lines=0)
「クラスタリング」以降のたった5行で、下の表と右のグラフが得られます。
# x1 x2 x3 x4 x5 x6 grp
# A 3 4 4 5 4 4 2
# B 6 6 7 8 7 7 1
# C 6 5 7 5 5 6 3
# D 6 7 5 4 6 5 3
# E 5 7 6 5 5 5 3
# F 4 5 5 5 6 6 2
# G 6 6 7 6 4 4 3
# H 5 5 4 5 5 6 2
# I 6 6 6 7 7 6 1
# J 6 5 6 6 5 5 3
# K 5 4 4 5 5 5 2
# L 5 5 6 5 4 5 3
# M 6 6 5 5 6 5 3
# N 5 5 4 4 5 3 2
# O 5 6 4 5 6 6 2
# P 6 6 6 4 4 5 3
# Q 4 4 3 6 5 6 2
# R 6 6 7 4 5 5 3
# S 5 3 4 3 5 4 2
# T 4 6 6 3 5 4 3
# 〓〓〓 入力データ
m <- matrix(c(3, 4, 4, 5, 4, 4,
6, 6, 7, 8, 7, 7,
6, 5, 7, 5, 5, 6,
6, 7, 5, 4, 6, 5,
5, 7, 6, 5, 5, 5,
4, 5, 5, 5, 6, 6,
6, 6, 7, 6, 4, 4,
5, 5, 4, 5, 5, 6,
6, 6, 6, 7, 7, 6,
6, 5, 6, 6, 5, 5,
5, 4, 4, 5, 5, 5,
5, 5, 6, 5, 4, 5,
6, 6, 5, 5, 6, 5,
5, 5, 4, 4, 5, 3,
5, 6, 4, 5, 6, 6,
6, 6, 6, 4, 4, 5,
4, 4, 3, 6, 5, 6,
6, 6, 7, 4, 5, 5,
5, 3, 4, 3, 5, 4,
4, 6, 6, 3, 5, 4),
nrow=20, byrow=T)
df <- data.frame(m)
colnames(df) <- c('x1','x2','x3','x4','x5')
rownames(df) <- c('A','B','C','D','E','F','G','H','I','J',
'K','L','M','N','O','P','Q','R','S','T')
print("===== 入力データ df =====")
df
# 〓〓〓 クラスタリング
library(cluster)
指定クラス数 <- 3
kekka <- kmeans(df, 指定クラス数) # K-Means法による非階層型クラスタリング
print("===== kekka <- kmeans(df, 指定クラス数) =====")
kekka
# 各種情報出力
print("===== 各種情報出力 =====")
kekka$centers
kekka$totss
kekka$withinss
kekka$tot.withinss
kekka$betweenss
kekka$size
kekka$iter
kekka$ifault
grp <- kekka$cluster # 各行に割り付けられたグループ番号
print("===== grp <- kekka$cluster =====")
grp
print("===== cbind(df,grp) =====")
cbind(df,grp)
# 〓〓〓 クラスタ散布図の表示
clusplot(df, grp, color=TRUE, shade=TRUE, labels=2, lines=0)
■■■■■ 入力データ df 次の構成になります。 # x1 x2 x3 x4 x5 x6 ← colnames 特性名 # A 3 4 4 5 4 4 # B 6 6 7 8 7 7 # C 6 5 7 5 5 6 # D 6 7 5 4 6 5 # E 5 7 6 5 5 5 # F 4 5 5 5 6 6 # G 6 6 7 6 4 4 # H 5 5 4 5 5 6 # I 6 6 6 7 7 6 # J 6 5 6 6 5 5 # K 5 4 4 5 5 5 # L 5 5 6 5 4 5 # M 6 6 5 5 6 5 # N 5 5 4 4 5 3 # O 5 6 4 5 6 6 # P 6 6 6 4 4 5 # Q 4 4 3 6 5 6 # R 6 6 7 4 5 5 # S 5 3 4 3 5 4 # T 4 6 6 3 5 4 # └ rownames データの名称 指定クラス数 <- 3 # K-Means法では、先にいくつのグループ(クラス)に区分するかを指示します。 ■■■■■ クラスタリング library(cluster) # cluster はクラスタリングに有用な関数を集めたライブラリです。 # kmeans() はclusterの持つ関数です。 kekka <- kmeans(df, 指定クラス数) # この1行だけで求める結果が得られます。 kekka # K-means clustering with 3 clusters of sizes 2, 8, 10 # 各クラスに振り分けられたデータ数 # Cluster means: クラス別の各列の平均値 # x1 x2 x3 x4 x5 x6 ← 特性値 # 1 6.0 6.0 6.5 7.50 7.000 6.5 ┐ # 2 4.5 4.5 4.0 4.75 5.125 5.0 ├ 3つのクラスにクラスタリングしました # 3 5.6 5.9 6.1 4.70 4.900 4.9 ┘(計算プロセスの都合で異なるクラス分けになることがあります # # Clustering vector: 各行がどのクラスに入るかの表 # A B C D E F G H I J K L M N O P Q R S T # 2 1 3 3 3 2 3 2 1 3 2 3 3 2 2 3 2 3 2 3 割り付けられたクラス # # Within cluster sum of squares by cluster: # 1.500 30.375 30.100 クラスタリングしたときの級内平方和 これが小さいほどよい # (between_SS / total_SS = 51.2 %) 級間平方和/全体平方和 これが大きいどどよい # # Available components: このkekka から取り出せる情報の一覧(次の項) # "cluster" 上のClustering vectorと同じです。 # "centers" # "totss" # "withinss" # "tot.withinss" # "betweenss" # "size" # "iter" # "ifault" 〓〓〓 各種情報出力 上の kekka 出力の主要変数を取り出す方法です kekka$centers # x1 x2 x3 x4 x5 x6 ← 特性値 # 1 6.0 6.0 6.5 7.50 7.000 6.5 ┐ # 2 4.5 4.5 4.0 4.75 5.125 5.0 ├ 3つのクラスにクラスタリングしました # 3 5.6 5.9 6.1 4.70 4.900 4.9 ┘(計算プロセスの都合で異なるクラス分けになることがあります kekka$totss # 126.95 全体平方和 kekka$withinss # 1.500 30.375 30.100 級内平方和 kekka$tot.withinss # 61.975 級内平方和計 kekka$betweenss # 64.975 級間平方和 kekka$size # 2 8 10 各クラスに割り付けられたデータ数 kekka$iter # 3 クラスタリング最適への実行反復回数 kekka$ifault # 0 最終実行でのエラーコード # 〓〓〓 cluster 結果の表 grp <- kekka$cluster # 各データが割り付けられたクラスの表 # A B C D E F G H I J K L M N O P Q R S T # 2 1 3 3 3 2 3 2 1 3 2 3 3 2 2 3 2 3 2 3 cbind(df, grp) # 入力データに結果データを組み込む # x1 x2 x3 x4 x5 x6 grp # A 3 4 4 5 4 4 2 # B 6 6 7 8 7 7 1 # C 6 5 7 5 5 6 3 # D 6 7 5 4 6 5 3 # E 5 7 6 5 5 5 3 # F 4 5 5 5 6 6 2 # G 6 6 7 6 4 4 3 # H 5 5 4 5 5 6 2 # I 6 6 6 7 7 6 1 # J 6 5 6 6 5 5 3 # K 5 4 4 5 5 5 2 # L 5 5 6 5 4 5 3 # M 6 6 5 5 6 5 3 # N 5 5 4 4 5 3 2 # O 5 6 4 5 6 6 2 # P 6 6 6 4 4 5 3 # Q 4 4 3 6 5 6 2 # R 6 6 7 4 5 5 3 # S 5 3 4 3 5 4 2 # T 4 6 6 3 5 4 3 ■■■■■ クラスタ散布図の表示 # 上の表があれば、自分で多様な加工ができますが、専用の関数を使えば簡単です。 clusplot(df, grp, color=TRUE, shade=TRUE,labels=2, lines=0) # 第1主成分を横軸1、第2主成分を縦軸にして各データの散布図を作成します。